- The paper presents a vision-only SR framework (VOSR) that uses dual conditioning—structural and semantic—to overcome hallucinations and preserve fine details.
- It introduces a restoration-oriented guidance mechanism that balances generative realism with input fidelity through adjustably scaled conditioning.
- The study achieves competitive perceptual quality and efficiency by employing one-step distillation, significantly reducing training cost and inference time.
Vision-Only Generative Image Super-Resolution: VOSR Framework
Introduction and Motivation
Recent advances in generative image super-resolution (SR) have largely relied on adapting large-scale text-to-image (T2I) diffusion models with multimodal pretraining. These models leverage language-derived semantics to condition generation, achieving impressive perceptual quality. However, such architectures are fundamentally built for free-form synthesis and require complex prompt engineering or conditioning mechanisms to enforce compliance with low-resolution (LR) image inputs. This approach introduces risks of hallucination, weakens spatial fidelity, and incurs significant training and inference overhead.
The central question addressed in "VOSR: A Vision-Only Generative Model for Image Super-Resolution" (2604.03225) is whether high-fidelity, perceptually competitive, and efficient generative SR can be achieved using a purely vision-only architecture—eschewing any multimodal data or T2I model adaptation. The authors introduce VOSR, a restoration-native framework that grounds both structural and semantic conditioning entirely in the visual domain, and design a restoration-oriented guidance mechanism specifically suited for generative restoration rather than generic generation.
Architectural Overview
VOSR operates in the latent diffusion paradigm. Given a LR image, it constructs two conditioning signals: (1) a structural condition derived from VAE-encoded spatially aligned LR features and (2) a visual semantic condition, extracted by a pretrained vision encoder such as DINOv2/DINOv3, representing high-level semantic abstractions directly from the image. These conditions are injected into a diffusion transformer (DiT) backbone to denoise the HR latent and reconstruct the output.
Figure 1: Overview of VOSR architecture, illustrating dual conditioning (structural and semantic) and restoration-oriented partial guidance.
Compared to previous vision-only SR models, which rely solely on structure or lack semantically strong conditioning, the additional semantic branch in VOSR resolves ambiguities arising from severely degraded inputs. Semantic features, learned in the visual domain without text supervision, provide better local grounding and spatial compliance than coarse text-aligned representations.
Restoration-Oriented Guidance
Conventional Classifier-Free Guidance (CFG) alternates during training between a fully conditioned branch and a completely unconditional one, then interpolates model outputs with a guidance scale to promote perceptual qualities. However, for the restoration problem, standard CFG introduces a weak auxiliary branch (often tasked with generic image generation from scratch), which is statistically and semantically mismatched to the restoration task.
VOSR proposes a partial conditioning approach for guidance: the auxiliary branch is not fully unconditional, but instead preserves weakened LR structural cues while dropping semantic conditioning. This ensures both branches remain input-anchored but differ in the strength and type of information utilized. At inference, the guidance scale s interpolates between a weakly conditioned (more generative) and strongly conditioned (more faithful) branch, with higher s values yielding results that are increasingly input-faithful (lower hallucination, stronger structure preservation).
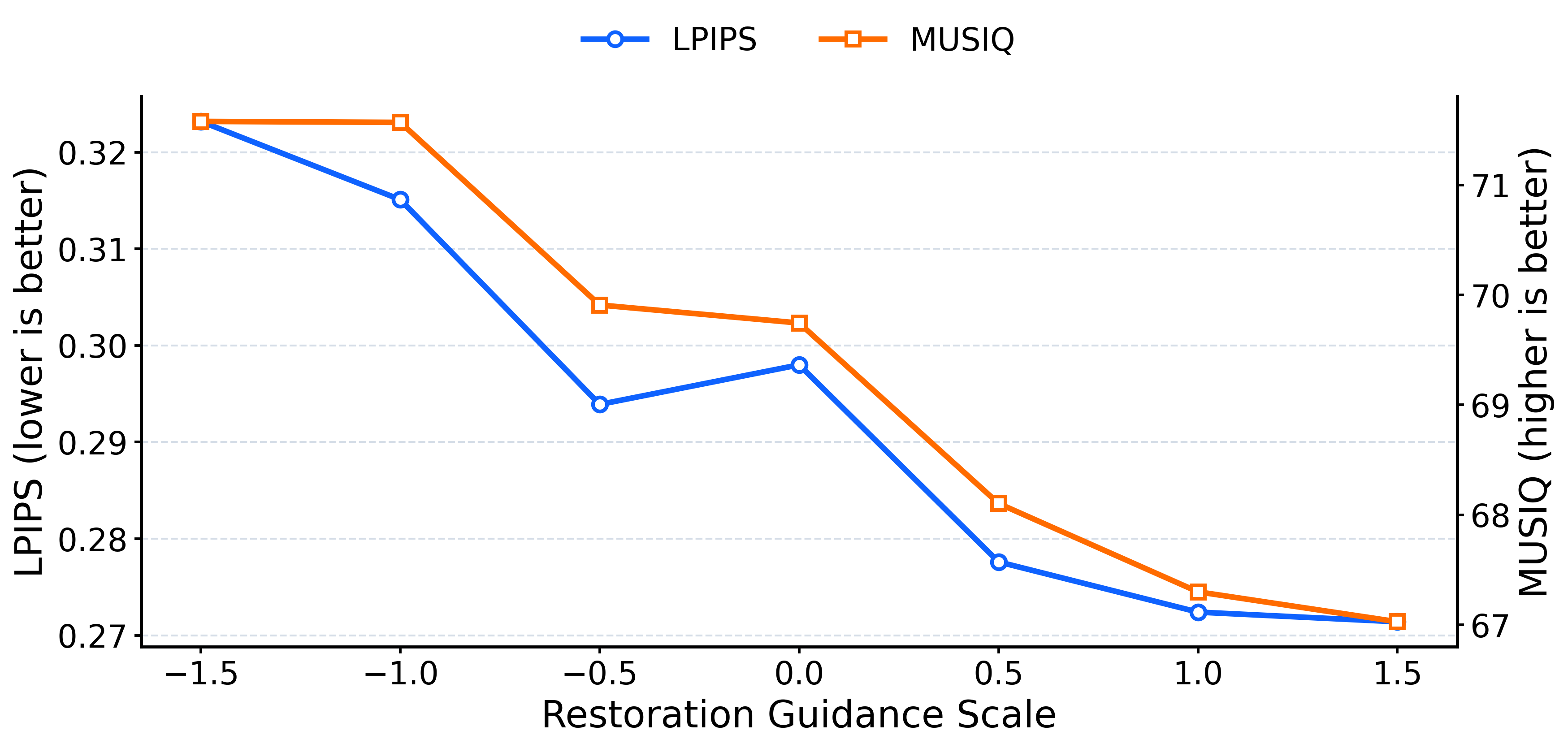
Figure 2: LPIPS and MUSIQ trends demonstrate how increasing guidance scale switches VOSR between more generative and more faithful restoration behaviors.
This behavior is notably distinct from T2I-SR, where guidance scale tends to amplify global semantic priors at the cost of fine spatial faithfulness. In VOSR, the guidance scale provides a direct control knob over the trade-off between generative realism and structural fidelity.
One-Step Distillation
To address the inefficiency of iterative multi-step diffusion, VOSR leverages knowledge distillation to compress the generative process to a single forward pass. The one-step student network is trained to match the denoising trajectory of the multi-step teacher under the same dual-conditioning and restoration-oriented guidance.
Distillation employs recursive consistency-based objectives, preserving both the balance of generative semantic abstraction and fidelity to the LR input. This enables VOSR to deliver state-of-the-art quality at a fraction of the computational budget needed for T2I-based and multi-step architectures.
Experimental Evaluation
Comprehensive quantitative and human perceptual studies were conducted on synthetic and real-world SR benchmarks, including LSDIR, RealSR, and the authors’ new ScreenSR dataset. VOSR was evaluated against state-of-the-art vision-only (e.g., ResShift, SinSR) and T2I-based (e.g., StableSR, SeeSR, OSEDiff, PiSA-SR) generative SR methods.
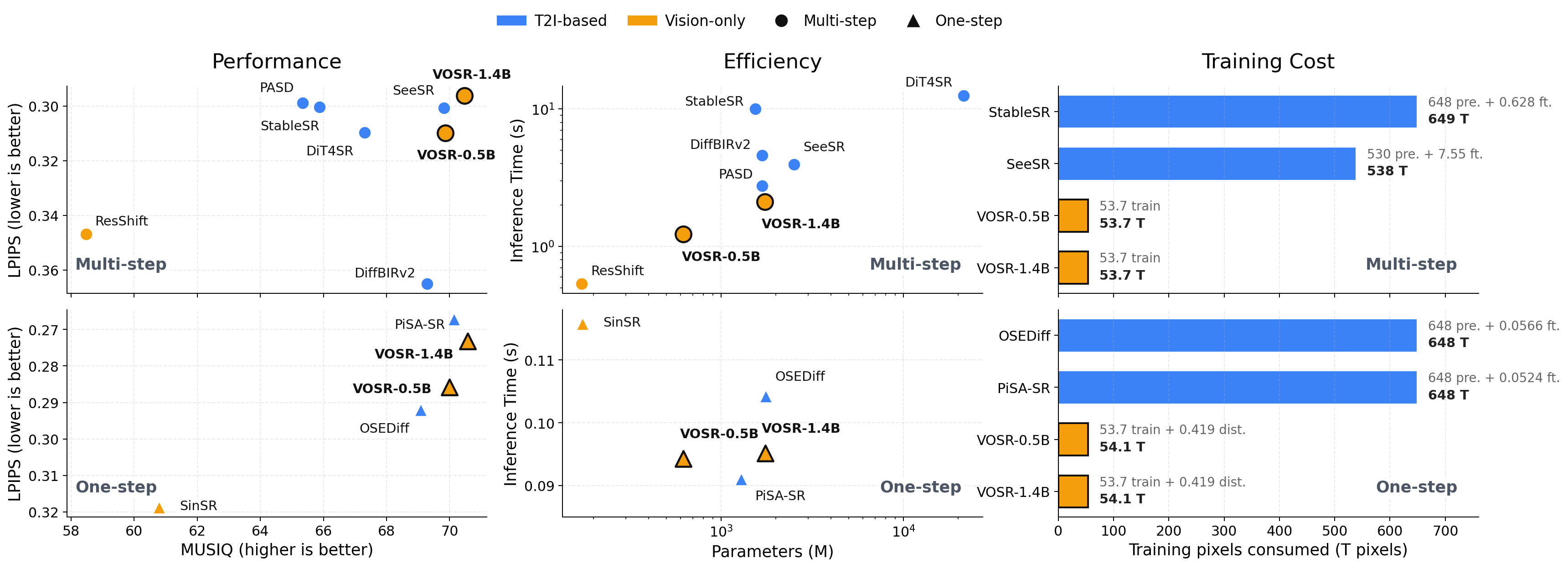
Figure 3: VOSR achieves strong perceptual quality, competitive or superior performance to T2I-based methods, and dramatic reductions in training cost and inference time.
Key findings:
- VOSR achieves top or competitive performance in all perceptual metrics (LPIPS, DISTS, AFINE-FR, MUSIQ, MANIQA, and others) and is consistently preferred in user studies for both multi-step and one-step settings.
- The method is markedly more efficient: VOSR-1.4B-ms, for example, runs at least 20–60% faster than comparable T2I-based methods with an order-of-magnitude lower training cost.
- On real-world benchmarks (ScreenSR, RealSR), VOSR produces restored images that are more faithful to fine local details and structure, particularly in challenging conditions where T2I-based methods are prone to hallucinations.

Figure 4: Qualitative comparisons showing multi-step and one-step SR results where VOSR recovers finer, structurally accurate details versus T2I and vision-only baselines.
Figure 5: Additional visual results highlighting VOSR’s improved recovery of thin structures, text, and complex contours with fewer artifacts or hallucinations.
ScreenSR Benchmark

Figure 6: The ScreenSR dataset covers diverse scenes, scales, and object types for robust SR evaluation.
To overcome the limitations of outdated or low-quality ground truth in existing real paired SR datasets, the authors introduce ScreenSR, a re-photography-based benchmark targeting high-quality, content-diverse test samples for robust generative SR evaluation. VOSR demonstrates superior or competitive performance on this challenging suite.
User Study
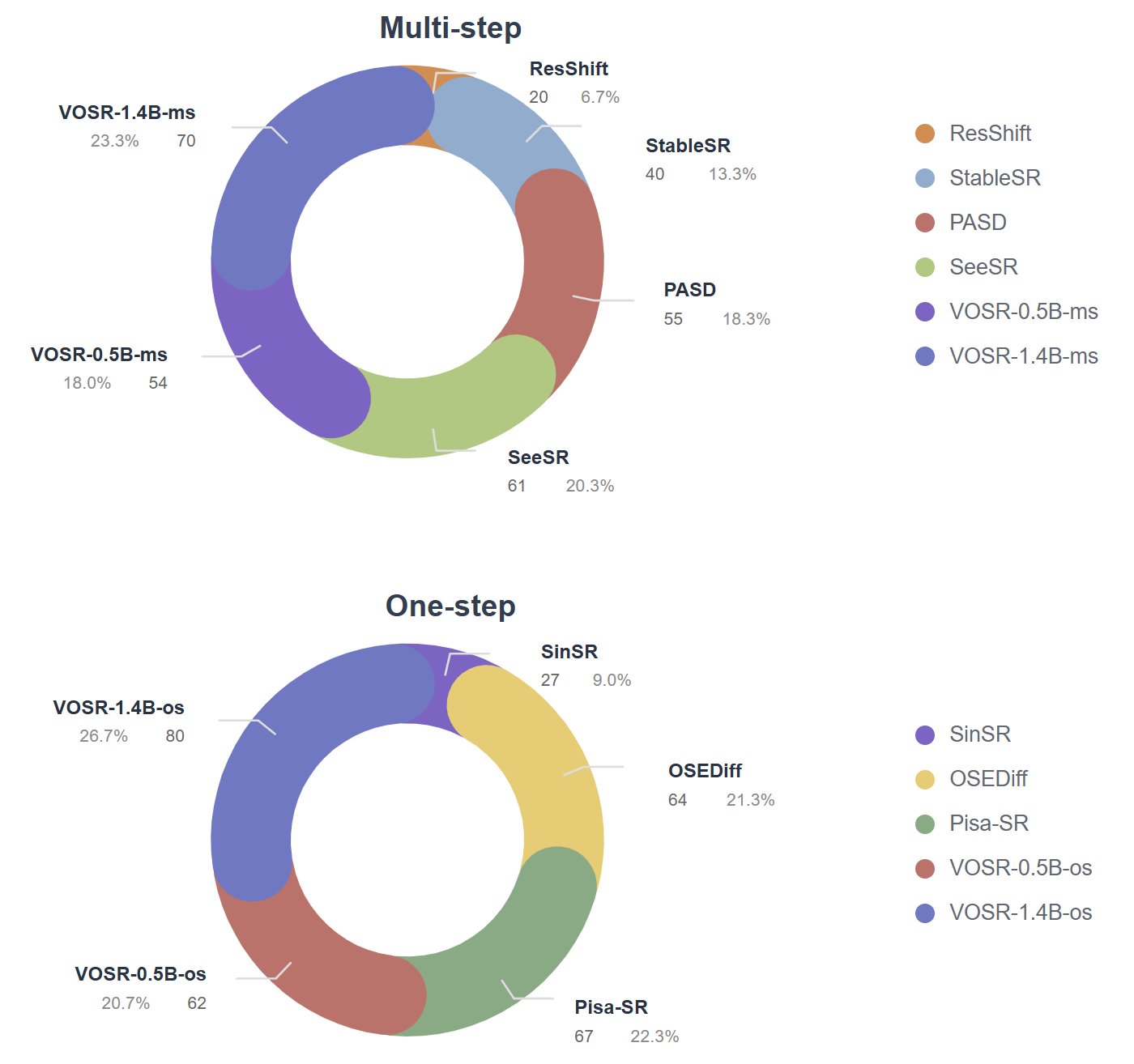
Figure 7: VOSR-1.4B models receive the highest human preference in both multi-step and one-step settings, underscoring perceptual gains.
Ablations and Analysis
Ablation studies confirm the importance of:
- Visual semantic conditioning: Removing the semantic condition or switching to weaker encoders (e.g., replacing DINOv2 with CLIP or SigLIP) consistently degrades perceptual quality.
- Restoration-oriented partial guidance: Standard CFG with a fully unconditional branch degrades performance versus partial conditioning, especially under limited data or computation.
VOSR’s partial conditional strategy provides more robust optimization and stronger guidance, effectively leveraging input-anchored semantics to ensure sample fidelity.
Implications and Future Directions
VOSR demonstrates, for the first time, that vision-only generative SR can match or exceed multimodal T2I-based methods in both quality and efficiency, with drastically reduced resource requirements. The method closes the perceived gap between large-scale text-pretrained generators and image-focused architectures for finely detailed, hallucination-free restoration.
Theoretically, this work highlights the limitations of text-induced semantics for controlled restoration, advocating for spatially grounded visual abstractions and restoration-native optimization. Practically, VOSR’s one-step distilled variant opens opportunities for deployment in memory and latency-constrained scenarios, such as mobile image enhancement.
Immediate extensions include scaling VOSR further (in data and model size) and generalizing to other restoration tasks (e.g., deblurring, denoising) leveraging the same vision-only, guidance-anchored framework.
Conclusion
VOSR (2604.03225) advances the state of restoration-oriented generative super-resolution by grounding semantics entirely in the visual domain and introducing a tailored, input-anchored guidance formulation. It achieves strong perceptual quality, structural fidelity, and efficiency, setting a new baseline for high-resolution image restoration without dependence on multimodal supervision or generative pretraining. This work redefines the design landscape for generative SR and has clear impact for future research in efficient vision-conditioned generative modeling.