- The paper introduces a novel hybrid framework that fuses VLM-based perceptual assessment with explicit anatomical structure and motion priors.
- The approach leverages detailed 2D-3D pose and stability metrics to detect subtle anatomical defects and physically implausible movements.
- Empirical results show statistically significant improvements in metric-to-human alignment, establishing a new benchmark for human-centric video evaluation.
HuM-Eval: A Coarse-to-Fine Framework for Human-Centric Video Evaluation
Introduction and Motivation
Automatic evaluation of human motion in video generation is a persistent challenge, as conventional metrics fail to robustly capture critical human-specific artifacts such as anatomical distortions and physically implausible motions. Existing metrics—distribution-based, rule-based, and VLM-based—mainly measure global statistics or pixel-level consistencies, largely disregarding the local structural and kinematic properties crucial for assessing the perceptual quality of human figures in generated videos. "HuM-Eval: A Coarse-to-Fine Framework for Human-Centric Video Evaluation" (2604.25361) presents a hybrid metric that fuses holistic scene understanding via VLMs with explicit, disentangled structural and dynamical priors for human evaluation. This approach operationalizes human perceptual sensitivity to high-level visual realism, anatomy, and dynamics, offering an evaluation paradigm with higher alignment to subjective human preference.
Framework Overview
HuM-Eval formalizes a cascade that first applies a VLM-based visual prior to gauge overall perceptual quality and then refines this assessment using two fine-grained components tailored to humans: an anatomical structure score and a motion stability score. This architecture targets critical failure cases for existing metrics, such as subtle anatomical anomalies and temporally consistent but physically implausible motion artifacts.
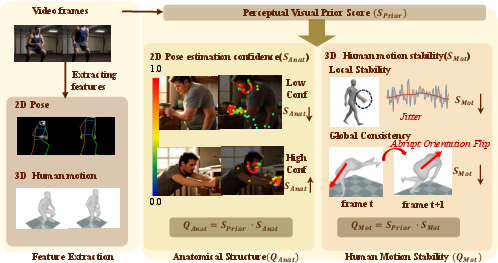
Figure 1: The HuM-Eval framework fuses holistic VLM perceptual scoring with explicit 2D-3D pose and motion features for a coarse-to-fine quality assessment.
The evaluation is structured as:
- Perceptual Visual Prior (SPrior): A VLM is queried via a rigorously constructed prompt probing clarity, stability, aesthetics, and realism, with the response score derived from the model’s classification logits. This establishes the upper bound for sample plausibility.
- Anatomical Structure Score (SAnat): Leveraging Sapiens-Pose (2B), the system quantifies anatomical plausibility via the confidence statistics of 133 body, hand, and face keypoints, min-max normalized against real-data bounds (ActivityNet). This directly penalizes visibility of degenerate geometry and structure artifacts.
- Motion Stability Score (SMot): Fine-grained physical plausibility is isolated by lifting the motion into 3D using GVHMR, and two stability measures are extracted: local joint jerk (filtered against a Gaussian-smoothed trajectory for temporal noise) and global orientation consistency (measuring abrupt unrealistic flips). These are again normalized to real motion priors (Motion-x++).
The final quality scores for appearance and motion are computed via multiplicative gating, i.e., QAnat=SPrior⋅S^Anat, and QMot=SPrior⋅SMot, enforcing that structural or kinematic failures severely suppress the overall rating, even for visually plausible samples.
HuM-Bench: Human-Centric Video Benchmark
HuM-Eval is accompanied by the introduction of HuM-Bench, a comprehensive benchmark tailored for human-centric scenarios:
- Spanning three domains: Body-Motion Only, Human-Object Interaction, and Human-Human Interaction.
- Prompts are synthesized via a systematic LLM-powered pipeline, ensuring compositional diversity and explicit context (1,045 prompts).
- Eight state-of-the-art T2V models (five open, three closed-source) are evaluated, with rigorous annotation by experts for anatomical correctness and motion smoothness.
Experimental Results
Superior Alignment with Human Judgment
Across 8 models and 100 annotated prompts, HuM-Eval achieves human correlation scores of 0.593 (anatomy) and 0.572 (motion), outperforming all rule-based and VLM-based baselines. For context, the best prior approaches—VBench Motion Smoothness and Qwen3-VL-8B (logits)—obtain only 0.503 and 0.565, respectively. The authors show statistically significant performance gains in both dimensions, and ablation studies confirm that multiplicative incorporation of anatomical and kinematic constraints consistently enhances metric-to-human alignment compared to VLM-only or rule-based-only alternatives.

Figure 2: Case analyses highlight baseline metric failure to penalize implausible artifacts, while HuM-Eval yields much lower scores consistent with human subjective judgments.
Model Differentiation and Detailed Analysis
Fine-grained HuM-Eval scores are highly discriminative, distinguishing generations with subtle anatomical defects and physically impossible dynamics. Open-source models such as Wan2.2-14B and SANA-Video(2B) achieve top scores (0.78, 0.89 on anatomy/motion), while earlier generations like CogVideoX-1.5(5B) and OpenSora-1.2 register severe underperformance, unable to model human motion plausibly at scale.
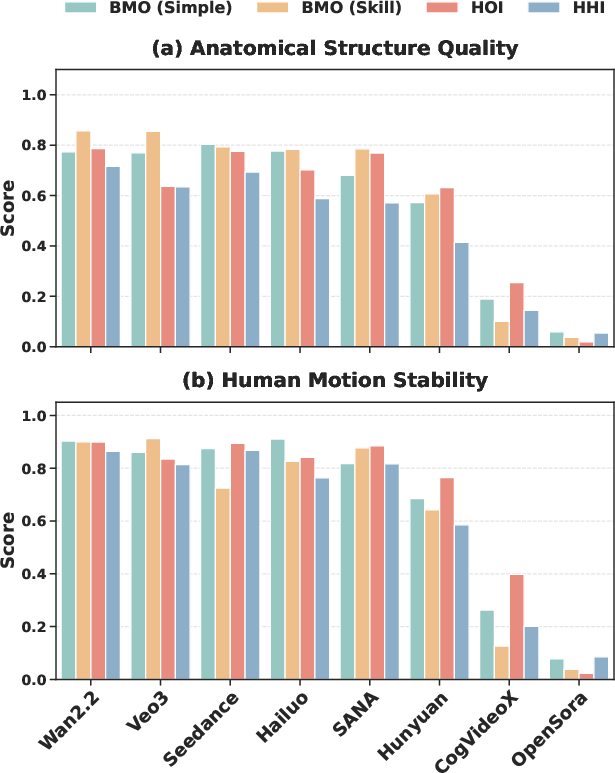
Figure 3: Category-level analysis of human appearance and motion smoothness demonstrates significant metric sensitivity and reliability across subdomains (BMO-Simple, BMO-Skill, HOI, HHI).
An important empirical finding is that interactive contexts (HOI, HHI) remain bottlenecks for SOTA models, as evidenced by a distinct drop in their HuM-Eval refinement scores. This underscores the increased complexity of modeling multi-agent or contact-rich settings.
Key Implications
Practical Significance
- Evaluation Reliability: The introduction of explicit structural and motion priors corrects “geometric blindness” present in VLM and rule-based metrics, addressing failure cases prevalent in prior work.
- Model Development: HuM-Eval provides actionable diagnostics for T2V model designers, as it distinctly identifies and penalizes off-manifold samples with plausible appearance but structurally impossible human content.
- Benchmarking: HuM-Bench sets a new standard for scalable, fine-grained, human-centric evaluation, fostering more robust future benchmarks and leading to iterative models with improved human fidelity.
Theoretical Insights
- The coarse-to-fine cascade demonstrates that VLM-derived holistic judgment alone is insufficient for human-centric domains.
- The explicit disentanglement of appearance (structure) and dynamics (physics) is necessary to induce strong human preference alignment in generative video assessment.
- The normalization of scores to real-world priors ensures that the metric exhibits robust transferability, avoiding calibration drifts when exposed to out-of-distribution generations.
Future Directions
- The metric’s modular pipeline can be extended to additional aspects such as contact events, manipulation, or multi-person coordination.
- Advances in 3D human estimation and physically grounded simulation can further increase metric sensitivity to complex interactive behaviors.
- The framework catalyzes research into metrics for AV generation, compositionality, and fine-grained perception, guiding both objective algorithmic benchmarking and subjective human alignment.
Conclusion
The HuM-Eval framework (2604.25361) delivers a rigorously validated, human-aligned evaluation protocol for human motion video generation by synergistically combining VLM perception with explicit physical and anatomical analysis. The associated benchmark establishes new standards in both scope and annotation reliability, and the empirical results demonstrate clear advances over prior baselines. This methodology is likely to serve as a foundation for next-generation evaluation of generative models targeting realistic and physically plausible human video content.