- The paper proposes RecFlash, a novel accelerator that uses frequency-based remapping to optimize embedding data layout, achieving up to 81% latency reduction.
- It integrates plane-level distribution and a hardware-managed page-wise cache to boost NAND flash bandwidth utilization and cut energy consumption by 91.9%.
- Adaptive online remapping minimizes retraining interruptions while enhancing scalability for deploying recommender systems on massive datasets.
RecFlash: Fast Recommendation System on In-Storage Computing with Frequency-Based Data Mapping
Introduction and Motivation
The continuous expansion of personalized recommender systems has placed severe strain on computational and storage infrastructures, particularly as sparse embedding tables now routinely reach terabyte scale. NAND flash-based in-storage computing (ISC) presents a promising avenue for hosting such embeddings due to its high density and superior bandwidth relative to traditional HDDs and moderate scalability compared to DRAM. However, current NAND flash ISC architectures are hampered by a bandwidth underutilization bottleneck: embedding access patterns are highly irregular, and the granularity mismatch between small embedding vector fetches (64–512B) and the page buffer size (several KBs) yields significant waste of internal bandwidth.
The paper proposes RecFlash, an ISC accelerator that addresses this fundamental inefficiency via access-frequency-guided remapping of embedding vectors, plane-level distribution, and a hardware-managed page-wise cache. Through an in-depth quantitative evaluation, RecFlash is shown to achieve latency reductions up to 81% and energy consumption savings of 91.9% relative to state-of-the-art ISC baselines.
Analysis of Bandwidth Underutilization in Embedding Access
While conventional neural network layers such as matrix multiplication exploit spatial locality via sequential fetches from DRAM or flash (Fig. 1a), recommendation models' embedding layers exhibit temporally localized but spatially random access (Fig. 1b). As a result, each NAND flash page load brings into the buffer a large amount of extraneous data that is typically not accessed for current inference, as illustrated in
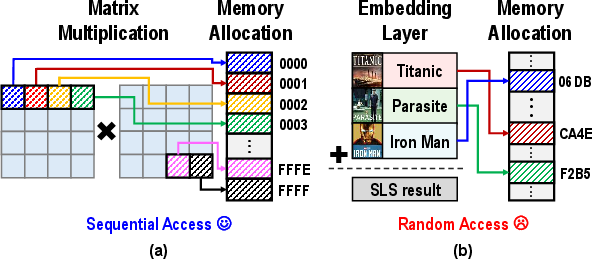
Figure 1: Memory access patterns: (a) show spatially local access for GEMM, (b) show sparse, random access for recommendation model embedding layers.
The inefficiency is clarified in
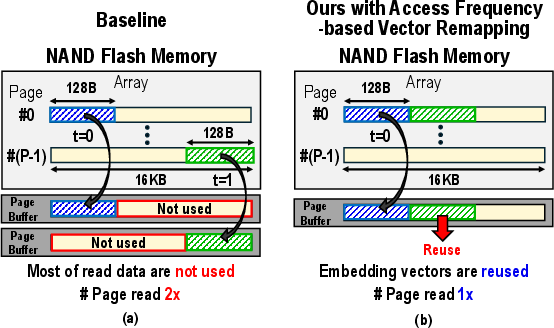
Figure 2: Baseline mapping yields poor bandwidth use (a); frequency-based remapping (b) clusters frequently accessed embeddings together, enabling improved utilization.
This problem is exacerbated with increasing page size in MLC/TLC/QLC flash and becomes particularly acute for real-world datasets featuring large embedding tables—e.g., the Criteo Terabyte Click Logs are now the norm and well beyond DRAM caching capacity. DRAM-based caches typically cover <0.2% of these tables, further motivating architectural innovation (see Fig. 3, embedding frequency distribution).
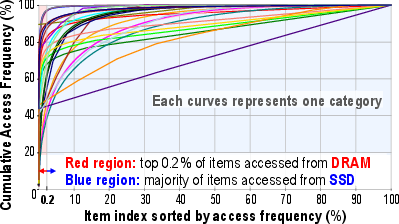
Figure 3: Access frequency distribution of embedding vectors in the Criteo TB dataset demonstrates few hot vectors and a large cold tail.
The RecFlash Architecture
Data Remapping and Plane-Level Distribution
The central innovation of RecFlash is the access-frequency-based remapping of embedding vectors. Hot (frequently accessed) vectors are sorted and reassigned to physical flash pages in a way that clusters them within pages and evenly distributes the hottest vectors across all planes. This ensures not only higher effective bandwidth utilization per page read, but also improved inter-plane parallelism. The importance of collocating hot vectors is clear from a comparison of read timing diagrams: retrieving two random vectors (baseline) typically incurs double the array+page-out latency as fetching two collocated vectors post-remapping.
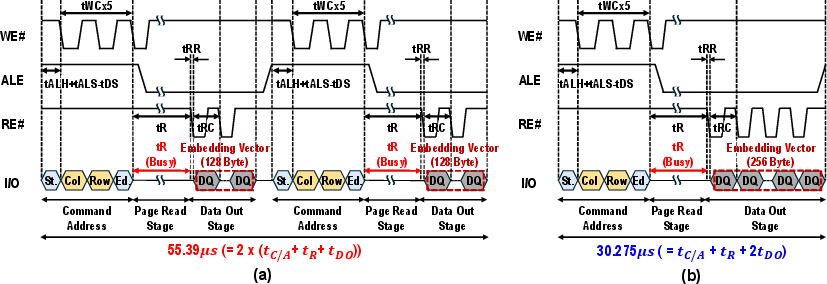
Figure 4: Timing diagrams show reduced latency when embedding vectors are colocated (b) compared to distributed across pages (a).
The method’s hardware realization organizes mapping and frequency counts using a hash table. Adaptive online remapping (Algorithm 1) avoids prohibitive global table reordering by updating only the hot region upon retraining, minimizing service interference.
Page-Wise Caching
Because machine learning-driven access locality often results in strong short-term reuse, RecFlash utilizes a hardware-managed, page-level LRU cache implemented in SSR controller SRAM. By caching frequently loaded pages, the system further reduces redundant NAND reads.
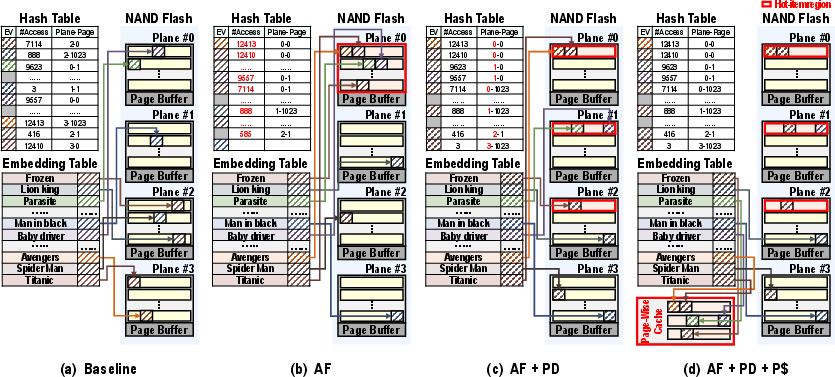
Figure 5: (a) Baseline mapping, (b) frequency-based remapping (AF), (c) AF plus plane distribution (PD), (d) AF+PD plus page-wise cache (P\$).
Adaptive Online Training and Remapping
Industrial-scale models require continual incorporation of user behavior via online training; RecFlash accommodates two classes of dynamic update policies:
- Threshold-based trigger: retraining/remapping is activated only when frequent updates to hot-spot vector IDs are detected above a certain quantile threshold (top-5/10/15%).
- Period-based trigger: retraining occurs at fixed intervals (e.g., daily), well suited for log-batched data such as Criteo.
Figures 6 and 7 trace the core remapping mechanisms and their resulting service overheads.
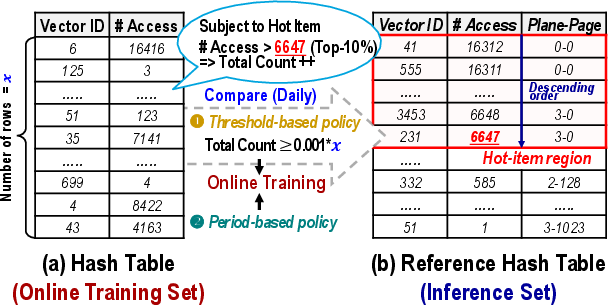
Figure 6: Hash table mechanisms for counting and managing embedding vector access frequencies, for both inference and online training.
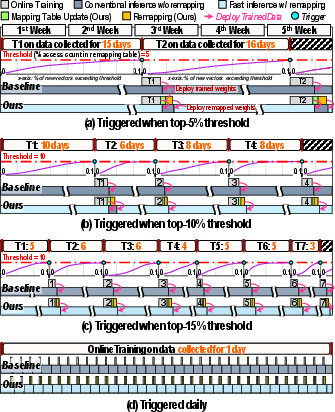
Figure 7: Remapping overheads under various online training trigger policies (top-5%, 10%, 15%, and period-based).
Critically, RecFlash overlaps much of the remapping with continued inference, and remaps only the minimal hot region, resulting in marginal interruption.
Hardware Implementation
The proposed architecture is realized as a lightweight hardware module within the SSD controller, interfacing to the FTL mapping tables (DRAM-resident). Comparator and pointer-update logic are synthesized to negligible area and power cost—orders of magnitude smaller than the flash die area—enabling practical deployment in commodity controller designs. The overall data flow, combining offline training, inference, and adaptive online retraining with selective remapping, is illustrated below.
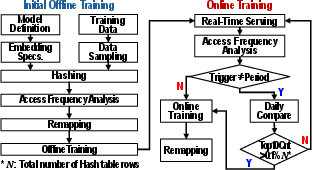
Figure 8: Overview of RecFlash data mapping, inference, and retraining flow.
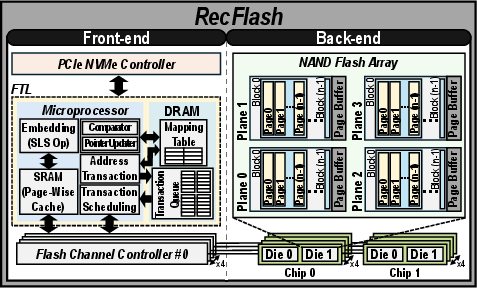
Figure 9: Top-level hardware architecture integrating the RecFlash components—page-wise cache, mapping tables, and remapping logic into the SSD controller and NAND backend.
Experimental Results
Latency and Energy Efficiency
Experiments sweep three DLRM variants and synthetic as well as real-world datasets on SLC, TLC, and QLC configurations, benchmarking against RecSSD and RM-SSD baselines. Latency for embedding operations is reduced by up to 91.4%, particularly for models (e.g., RMC2) with embedding-dominated compute. End-to-end model latency reductions remain strong (81% for embedding-bound, 40% for MLP-heavy models).

Figure 10: Normalized embedding latency across RMC1–RMC3 on TLC; RecFlash achieves 54–91% reductions.
Energy consumption follows a similar trend, with RecFlash attaining up to 91.9% read energy reduction over the state-of-the-art.

Figure 11: Normalized read energy: RecFlash eliminates redundant page reads, yielding up to 91.9% savings.
Real-World Dataset Evaluation
The RecFlash benefits are validated on the Criteo Terabyte and Criteo Kaggle datasets (Fig. 13). The design’s advantages persist even at lower data scale, supporting its generalizability.
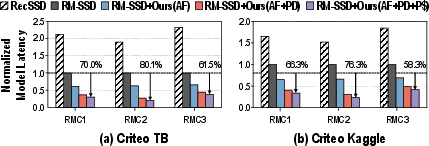
Figure 12: End-to-end latency improvements across DLRM models, for Criteo TB and Kaggle datasets, consistently favoring RecFlash.
Adaptive Online Remapping Overhead and Amortization
Remapping and retraining overheads, including for frequent retraining policies, are modest due to the selective hot-item-only updates. Even with up to 20M daily inferences and daily retraining, the cumulative inference time is reduced by up to 76.7% over RM-SSD, due to effective amortization and minimal interruption.

Figure 13: Cumulative inference time (days) under various retraining policies; RecFlash significantly outpaces the baseline.
Implications and Future Directions
RecFlash redefines the interaction between embedding-table access patterns and storage hardware for recommender workloads by aligning data layout and runtime adaptation with the architectural organization of NAND flash, all without non-standard changes to commodity flash chips. In practice, these innovations allow scaling up recommendation service throughput and reducing energy costs without incurring DRAM penalty or necessitating hardware overhauls.
The selective adaptive remapping strategy introduced—targeting only hot regions while maintaining service continuity—provides a concrete blueprint for future ISC-based accelerator deployment in large-scale online learning environments. This design choice directly addresses the trade-off between retraining responsiveness and system availability, a recurring challenge for personalized models with long lifetime deployments. As recommendation models grow in scope and diversity, further extensions could incorporate hardware/software co-optimization for even finer-grained access prediction, hierarchical caching, and cross-ISC-controller scheduling.
Conclusion
RecFlash enables fast, energy-efficient recommendation inference on NAND flash ISC by systemically tackling the root cause of flash bandwidth underutilization in embedding-heavy workloads. Through access-frequency-based remapping, plane-level distribution, and intelligent page-wise caching, it achieves up to 81% latency reduction, 91.9% energy savings, and over 76% lower cumulative inference time under online retraining relative to leading ISC baselines. These results establish RecFlash as a viable solution for scalable, adaptive deployment of DNN-based recommendations over extremely large datasets, explicitly bridging storage-level constraints and deep learning system requirements.