- The paper introduces a roundtrip verification method that ensures semantic fidelity by comparing original and roundtrip formalizations using an SMT solver.
- The approach decomposes autoformalization into three stages and applies diagnosis-guided repair, achieving formal equivalence rates of up to 85.3% for Claude and 82.7% for GPT.
- The integration of NLI-based semantic drift analysis validates that targeted repairs significantly reduce semantic inconsistencies, guiding further improvements in schema expressiveness.
Introduction and Motivation
The autoformalization of natural language (NL) into formal, machine-checkable semantics has emerged as a fundamental capability at the confluence of NLP and formal methods. However, an underexplored but critical challenge is ensuring that such formalizations are faithful: that the translation into target formalism (e.g., SMT-LIB, Lean) precisely preserves intended semantics, especially in the absence of ground-truth annotations. Existing approaches often rely on syntactic acceptance or task-based proxies, which provide at best indirect evidence of semantic fidelity.
This work proposes a rigorous, formalism-agnostic framework for autoformalization assessment and repair, based on roundtrip verification: passing the NL → Formalism → NL → Formalism loop, and checking logical equivalence between the original and roundtrip formalization. Critically, when failures in equivalence are detected, the framework introduces a diagnosis-guided, stage-localized repair protocol which corrects only the problematic translation stage, rather than performing blind end-to-end regeneration.
Framework: Roundtrip Verification and Error Localization
The roundtrip pipeline decomposes autoformalization into three distinct, stateless translation stages: (1) NL to formalism (T1), (2) formalism to reconstructed NL (T2), and (3) reconstructed NL back to formalism (T3). For an input x, one computes an original formalization yorig, a reconstructed NL x′, and a roundtrip formalization yrt. Formal equivalence is checked between →0 and →1 using an SMT solver.
When these are not judged equivalent, a trained LLM-based judge →2 sequentially compares adjacent pairs of pipeline artifacts to localize the "first-failed" stage, producing a scoped natural language explanation for use in targeted repair. This stage-focused repair operator (→3) modifies only the relevant artifact (and its dependents) per iteration, efficiently correcting the responsible error without perturbing unrelated pipeline components.
(Figure 1)
Figure 1: Cumulative UNSAT rules per iteration for Claude (left) and GPT (right). Full repair dominates at every iteration in both models.
Diagnosis-Guided Repair vs. Baselines
The pipeline is evaluated on a corpus of 150 traffic rules, targeting formalization in a hand-crafted domain ontology using many-sorted first-order logic and SMT-based equivalence checking. Both Claude Opus 4.6 and GPT-5.2 are tested, using three repair strategies:
- No Repair: Baseline, with only the initial roundtrip check.
- Random Repair: Repair stage selected uniformly at random.
- Full Diagnosis-Guided Repair: The proposed method, localizing the failure for targeted correction.
Results show that the Full diagnosis-guided strategy achieves a final formal equivalence rate of 85.3% for Claude and 82.7% for GPT, compared to 66.7% and 78.7% for Random Repair respectively (see "Repair overlap between Full and Random" below). The benefit is pronounced for Claude, with targeted repair nearly doubling unique repair counts compared to Random.
(Figure 2)
Figure 2: Repair overlap between Full and Random for Claude (left, 83 rules) and GPT (right, 58 rules). In both models, Full exclusively repairs more rules than Random.
The efficiency analysis highlights that, especially for Claude, diagnosis-guided repair achieves substantially more corrections per LLM call (41% reduction in cost-per-repair).
Diagnosis Analysis and Model-Specific Error Profiles
An analysis of the per-iteration repair trajectory finds that Full repair is more effective at every step: for Claude, more faults are corrected in the first repair iteration than the entire Random pipeline; for GPT, the advantage accrues in later steps, reflecting GPT's higher initial accuracy and a smaller residual, harder-to-correct set.
Diagnosis distributions are model-dependent. Claude errors concentrate in →4 (reformalization), with →5–diagnosed cases rising over iterations, while GPT shows strong →6 (initial formalization) concentration—behavior likely due to both true model error modes and possible sequential checking protocol bias.
(Figure 3)
Figure 3: Per-iteration stage selection (Full condition) for Claude (left) and GPT (right). Claude increasingly targets →7, while GPT consistently targets →8.
Assessing Semantic Fidelity: NLI-Based Semantic Drift Analysis
Formal equivalence only ensures self-consistency, not true semantic faithfulness. Therefore, a post-hoc bidirectional NLI (BART-large-MNLI) analysis is used to compare the original NL input and reconstructed NL after roundtrip, categorizing result pairs into Equivalent, Strengthened, Weakened, Related, Unrelated, and Contradiction.
The analysis demonstrates reduced semantic drift for diagnosis-guided repair over baselines: among formally equivalent (UNSAT) cases, only →910-14% exhibit substantial drift as flagged by NLI (contradiction/unrelated). Notably, Full repair produces more Equivalent and fewer Unrelated/Weakened outcomes across models compared to Random (see figure below).
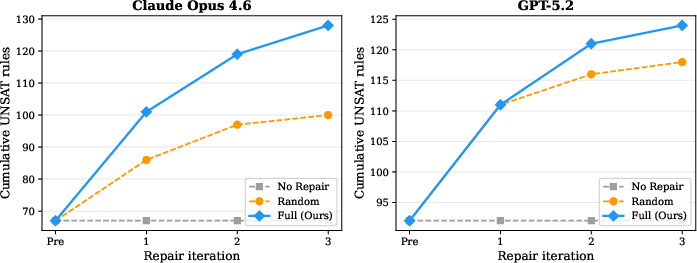
Figure 4: NLI category distribution for Claude (left) and GPT (right). Full achieves more Equivalent and fewer Weakened/Unrelated outcomes in both models.
Manual inspection reveals small numbers of false-positive drift flags, confirming that the NLI proxy generally correlates with true meaning preservation, but is imperfect due to lexical/operational mismatches.
Failure Analysis and Critical Bottlenecks
Residual failures after three diagnosis-guided iterations are dominated by schema expressiveness gaps. When the formal vocabulary cannot represent a required distinction or exception, no localized repair can succeed; increasing repair budget offers limited utility in such cases. Smaller proportions of failures are attributed to stage-cycling errors (multi-stage instability) and diagnosis fixation (repeatedly failing to correct subtle errors in the same stage).
Implications and Future Directions
The framework establishes that roundtrip verification with stage-targeted repair yields significant practical improvements in autoformalization quality, avoids the need for reference formalizations, and generically applies to domains admitting equivalence checks. However, ultimate semantic fidelity is bounded by schema coverage. The approach highlights key open directions:
- Automated schema induction and enrichment, especially to enable open-domain application.
- More robust cross-model or ensemble-based diagnosis protocols.
- Incorporation of semantic proxies (e.g., NLI or counterexample-guided repair) into the iterative loop itself.
- Extension to more structurally complex, inter-dependent texts (e.g., statutory sections with cross-references).
- Generalization to richer formal target languages (e.g., dependent type theory).
Conclusion
This work introduces a principled, annotation-free pipeline for faithful autoformalization, combining roundtrip verification with efficient, diagnosis-guided repair. Strong empirical results show improved repair success and reduced semantic drift relative to unstructured repair, for both Claude and GPT families. The necessity—but not sufficiency—of formal equivalence for true semantic preservation is quantitatively shown. Practical adoption in formal law, mathematics, or code synthesis tasks will depend on closing the schema expressiveness gap and further integrating semantic diagnostics.