- The paper demonstrates significant misalignments between user-imposed taxonomies and logical dependency communities in Mathlib.
- It employs multilayer dependency graphs to quantify key metrics like import redundancy (17.5%) and centrality differences between infrastructure and mathematical content.
- The study offers actionable diagnostics for improving formal libraries through refined import mechanisms and structural refactoring.
Quantitative Network Analysis of Mathlib's Structure
This essay presents an expert technical overview of "The Network Structure of Mathlib" (2604.24797), which undertakes a comprehensive, quantitative network analysis of the Lean 4's Mathlib library, currently the largest public formal mathematics corpus for a proof assistant. The study isolates and measures the structure, granularity, and organizational divergences inherent to large-scale mathematical formalization projects via multilayer dependency graphs and graph-theoretic diagnostics. It reveals intrinsic frictions between human-convenience taxonomies, language-infrastructure mediation, and underlying mathematical logic.
Multilayer Dependency Graphs: Methodological Framework
The analysis extracts three principal organizational graphs from Mathlib:
- Module Graph (Gmodule): Directed acyclic graph (DAG) of source files/modules linked by declared Lean imports.
- Declaration Graph (Gthm): DAG of logical and infrastructural dependencies between all $308,129$ declarations, with $8.4$ million labeled edges.
- Namespace Graph (Gns): Aggregates declarations by their dotted-name taxonomies, offering an intermediate perspective between files and declarations.
Each graph is further dissected via decompositions reflecting Lean language mechanisms—typeclass synthesis, coercions, structure inheritance, proof tactics, additive mirroring, and derivation—in order to separate tool-infrastructure from math-content edges. This design enables separation of product (formalized math logic) from organizational process (human engineering, proof assistant artifacts).
Structural Characterization and Major Empirical Findings
Divergence Between Cognitive Taxonomies and Logical Structure
The analysis demonstrates pronounced misalignment between user-imposed organizational structures (file tree, naming namespaces) and logical dependency communities. Adjusted normalized mutual information (NMI) between module or namespace boundaries and Louvain community structure in the declaration graph is only $0.34$, with cross-namespace edges accounting for 50.9% of declaration-level dependencies. This misalignment arises because developer choices privilege cognitive convenience and workflow efficiency over minimizing logical or compilation coupling.
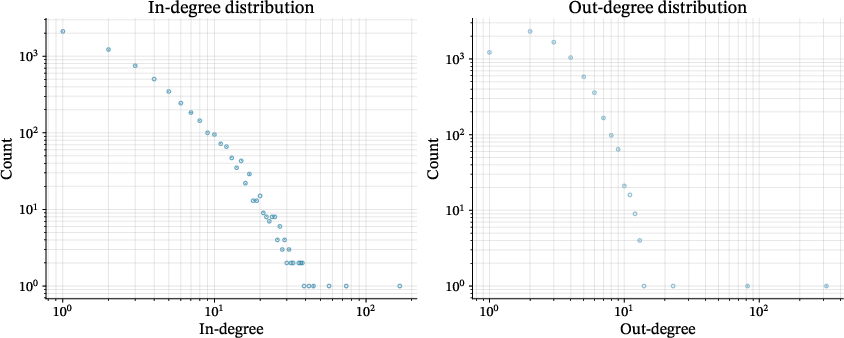
Figure 1: In-degree (blue) and out-degree (orange) distributions on log--log axes for Gmodule, highlighting heavy-tailed centralities and skew toward infrastructural hubs.
Massive Over-import and Redundant Visibility
Developers import entire files, but each module on average uses just 1.6% of the declarations it pulls in. The import graph retains 17.5% edge redundancy (post-lint), which inflates parallel build bottlenecks and the critical path dependency DAG (Gthm0 modules, Gthm1 theoretical parallelism ratio). The module import view dramatically compresses the true declaration dependency surface—aggregation amplifies import connectivity by a factor of Gthm2 compared to the file level.
Typeclass synthesis, coercions, tactic-generated proofs, and automatic mirroring via metaprogramming contribute Gthm3 of all declaration dependencies, invisible in raw source code. This silent edge inflation makes network centrality and clustering essentially measure the "technical utility" (how frequently a node is referenced by infrastructure or proof automation) rather than mathematical depth or importance. For instance, the trivial axiom Eq.refl has in-degree Gthm4—ranking above any major theorem—while central mathematical results (e.g., the Chinese Remainder Theorem) are not high-centrality nodes.
Topological Compression and Layer Structure
While module and namespace trees appear deep (Gthm5 and Gthm6 DAG layers, respectively), the logical dependency DAG is notably shallower (Gthm7 layers), and the majority of logical dependencies cross high-level human boundaries. The module hierarchy artificially inflates vertical depth due to the coarse granularity of import—a design inherited from programming language modularity, not mathematical necessity.
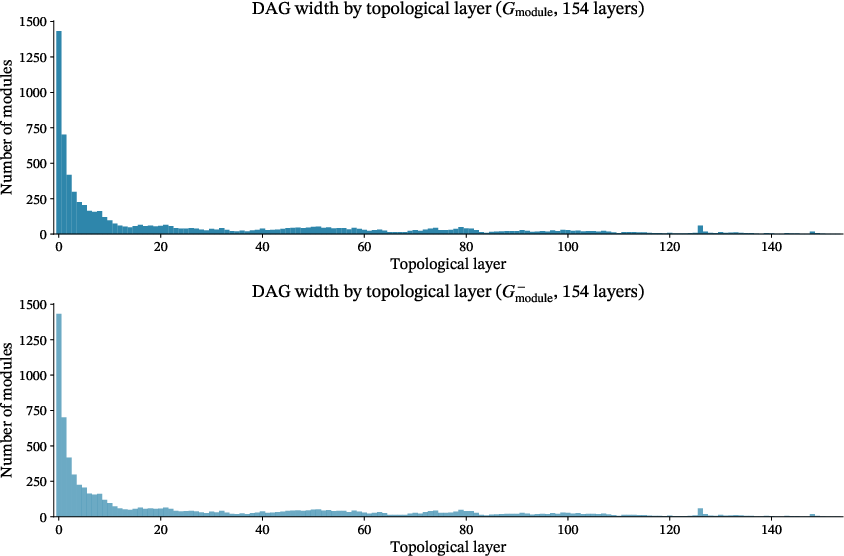
Figure 2: DAG width by topological layer for Gthm8, displaying the funnel shape of Mathlib's infrastructure with a massive leaf layer and narrow foundational core.
Theoretical and Practical Implications
Organizational Metrics for Diagnostics and Automation
The presented metrics—module cohesion (Gthm9), cross-namespace edge ratios, zero-citation rates, and PageRank/betweenness distributions—directly provide actionable diagnostics for proof-assistant maintainers. They allow quantifiable detection of scope drift, obsolete API surface, and refactoring candidates. These indicators are immediately applicable both for manual curation and for driving CI automation (e.g., phased test prioritization on high-centrality modules or strict enforcement of import utilization budgets).
Implications for Language and Library Design
Findings on import redundancy and the infrastructure–mathematical centrality bifurcation argue for finer-grained import mechanisms and sharper boundaries between language tooling and mathematical logic. The introduction of Lean’s public/private module system is a direct response to measured transitive redundancy. The evidence on centrality separation suggests that "infrastructure" modules and definitions should be encapsulated and perhaps even compiled separately to allow both build system improvements and more interpretable network centrality as a scientific measure.
Current AI premise selection/retrieval systems typically ignore structural context, treating each proof as an independent unit. The fine-grained dependency and community labels extracted here can serve as informative structural metadata to improve premise selection, proof search, or decomposition strategies for both training/evaluation of AI systems and generation of new formalized content. As AI-generated fragments enter Mathlib, the established baseline enables robust detection of structural drift—i.e., identification of changes in the graph that may originate from new organizational or logical regimes imposed by ML-driven formalization.
This study situates Mathlib as a "transitional artifact" in the migration of mathematics from informal, locally maintained knowledge stores to explicit, version-controlled, machine-verifiable corpora. The observed networks encode the friction and feedback between inherited disciplinary structure and the constraints of computational verification. Human organizational process is internally coherent but collectively divergent from the logical structure mathematicians ultimately rely upon.
The results also highlight the path-dependent brittleness of monolithic formal corpora: critical-path depth, infrastructural hub centralization, and import redundancy collectively threaten long-term maintainability and scalability. Quantitative network analysis enables early detection and management of these risks and informs future designs, including potential decentralized or federated tier architectures.
Future Directions and Open Problems
- Longitudinal structural analysis: Repeating network extraction across Mathlib development history (critical refactoring events, Lean 3/4 transitions) will clarify which network features are inherent to formal mathematics and which arise from transient engineering or community-driven factors.
- Automated boundary detection: Minimum-cut and community detection can empirically suggest "natural" package boundaries for modularization or package splits.
- Generalization to other libraries: Applying this framework to Isabelle/AFP, Coq/MathComp, Mizar/MML will further distinguish universal properties of formal mathematical corpora from Lean/Mathlib-specific procedures.
- Soft-dependency graph extraction: Enriching the logical DAG with "soft edges" extracted from adjacent prose or mathematical textbooks may enhance cognitive navigability for both humans and AI authoring systems.
Conclusion
This foundational network analysis of Mathlib's structure establishes a rigorous methodology and baseline for ongoing and future research into the macroscopic organization of formal mathematics libraries. By quantitatively isolating the tensions and alignments between human cognitive frameworks, language infrastructure, and logical dependency, it not only diagnoses current engineering bottlenecks but also provides the vocabulary and metrics necessary for maintaining, refactoring, and scaling formal mathematical knowledge in both human- and machine-driven environments.

