- The paper introduces DepthKV, a method that reallocates KV cache budgets across transformer layers based on measured layer importance to optimize long-context LLM inference.
- It leverages representation metrics, especially InfoNCE, to predict layer sensitivity and guide non-uniform pruning, thereby preserving output quality.
- Empirical evaluations on various tasks and models confirm DepthKV consistently outperforms uniform pruning baselines, improving metrics such as ROUGE-1 and QA accuracy.
DepthKV: Layer-Dependent KV Cache Pruning for Long-Context LLM Inference
Introduction and Motivation
DepthKV addresses a fundamental bottleneck in autoregressive inference of LLMs operating over extended context lengths. As context windows are scaled to tens or hundreds of thousands of tokens, the Key-Value (KV) cache memory footprint—growing linearly with input sequence length and transformer depth—overtakes compute as the dominant cost. Post-training pruning methods have emerged to reduce the KV cache size by discarding tokens with low attention scores, but most methods uniformly allocate the pruning budget across layers, implicitly assuming homogenous layer importance. This paper empirically and statistically demonstrates that transformer layers show significant heterogeneity in sensitivity to KV cache pruning and proposes DepthKV, a framework for layer-dependent allocation based on measured layer importance.
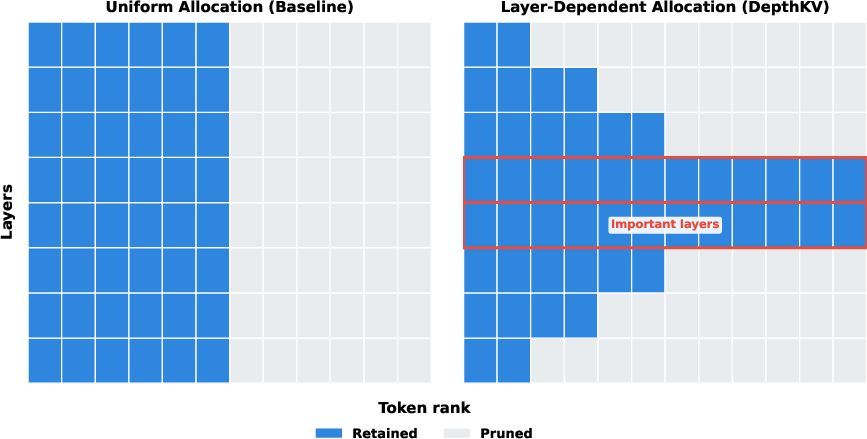
Figure 1: Uniform allocation assigns equal KV budgets per layer; DepthKV reallocates based on sensitivity, retaining more tokens in critical layers.
Layer-Wise Sensitivity Analysis and Content Amplification
The authors conduct a rigorous layer-wise ablation experiment during prefill, pruning tokens from one layer at a time and quantifying downstream performance degradation. The results exhibit pronounced layer-dependent variation: certain layers incur the greatest performance drop, while others appear partially redundant. Permutation testing robustly rejects the null hypothesis of uniform importance (p-value <0.05 for all datasets).
Layer importance is also reflected in output quality and length. Pruning sensitive layers suppresses content generation, leading to shortened and less informative summaries. YapScore, a verbosity-aligned metric, shows strong per-layer correlation with downstream metrics such as ROUGE-1, confirming the alignment between sensitivity and informative output.
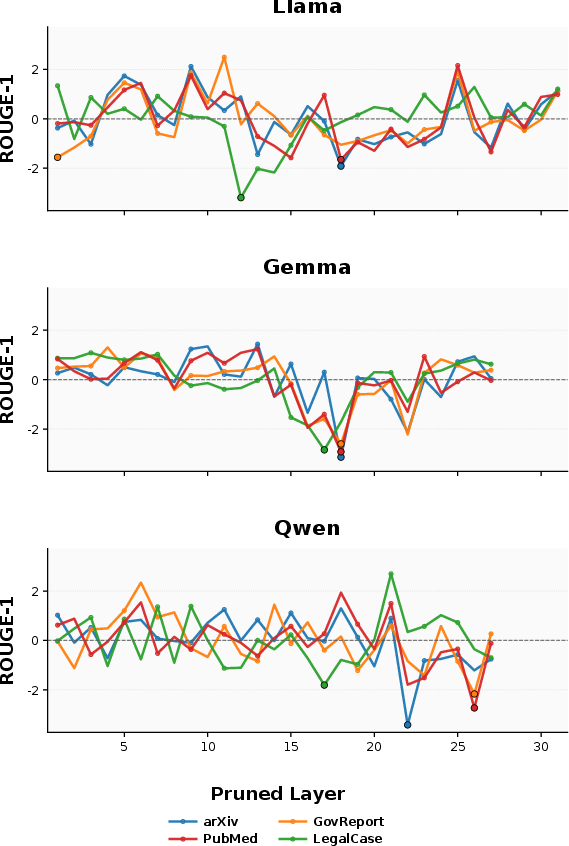
Figure 2: ROUGE-1 impact under single-layer pruning, standardized by z-score; performance drop peaks sharply at specific layers.
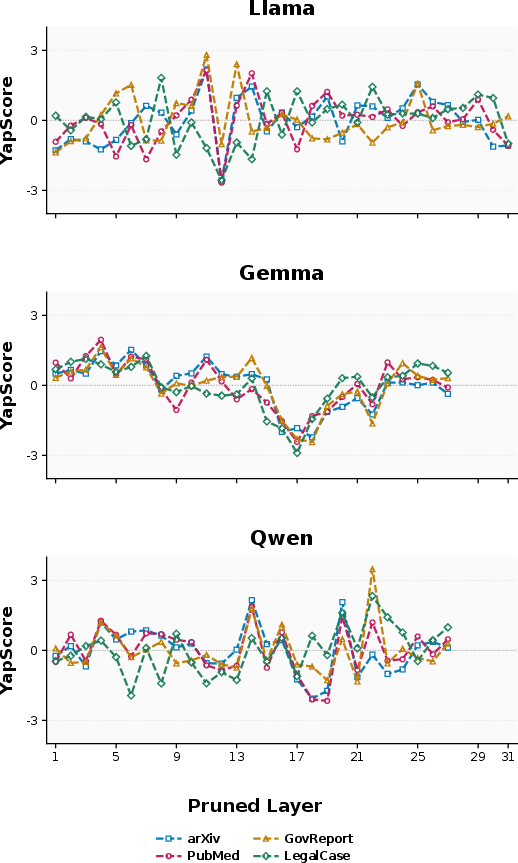
Figure 3: YapScore variation across layers indicates suppressed content generation aligns with high-sensitivity layers.
Representation Metrics and Layer Importance Estimation
To proxy layer importance, the paper leverages representation metrics derived from hidden states. Among multiple candidate metrics (spectral entropy, curvature, DiME, LiDAR), InfoNCE—measuring robustness and invariance under input perturbations—emerges as the most consistent predictor of layer sensitivity. Post-attention InfoNCE values are strongly and negatively correlated with performance drop under KV cache pruning, empirically validating representation-guided allocation strategies.
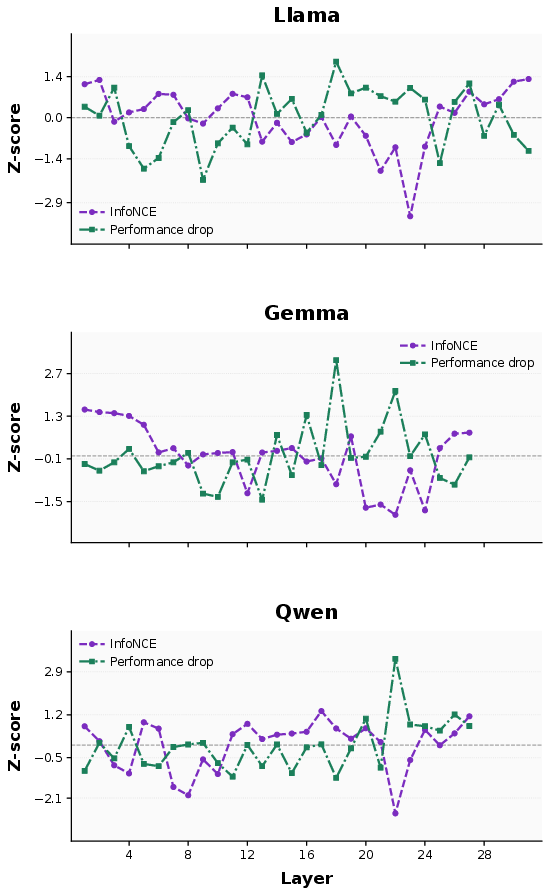
Figure 4: Negative correlation between InfoNCE and standardized ROUGE-1 drop, demonstrating InfoNCE's reliability for layer ranking.
DepthKV Framework and Allocation Strategies
DepthKV formalizes KV cache pruning as a constrained allocation problem: given a global memory budget, select token subsets and layer-specific budgets to maximize task performance. The framework allows for non-uniform, layer-dependent allocation via three main strategies:
- Middle-Layer Protection (MLP): Preserves a fixed subset of intermediate layers.
- Metric-Guided Allocation (MGA): Distributes budgets based on InfoNCE-derived layer importance scores, capping maximally pruned layers to prevent over-pruning.
- Middle-Layer Metric Allocation (MLMA): Combines MLP and MGA by protecting a subset of middle layers and assigning remaining budgets via InfoNCE rankings.
Each strategy reallocates KV cache capacity according to measured layer importance rather than structural heuristics, directly exploiting DepthKV's insights.
Empirical Evaluation Across Models and Tasks
DepthKV is evaluated on multiple open-weight LLMs (Gemma, LLaMA, Qwen) and diverse long-context tasks, including document summarization, document-grounded question answering (QA), and mathematical reasoning (GSM-infty). All experiments control for global KV cache reduction ratio (60%), ensuring memory constraints are matched across methods.
DepthKV consistently outperforms uniform pruning baselines across all datasets and models. MGA yields strong improvements in summarization quality, e.g., raising ROUGE-1 from 26.75 to 29.75 and SBERT similarity from 55.09 to 61.98 on arXiv. In QA and reasoning, MLMA-6L often achieves the highest accuracy, while MLP and MGA dominate HotpotQA and Qasper, confirming strategy-specific optimality.
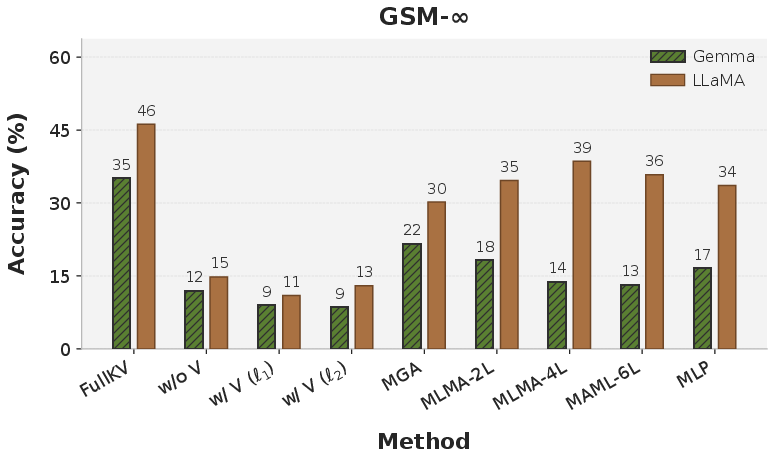
Figure 5: GSM-infty benchmark accuracy; DepthKV variants outperform uniform cache pruning in all settings.
LLM-as-a-judge evaluations further corroborate DepthKV's gains in correctness, completeness, and conciseness.
Implications and Future Directions
DepthKV demonstrates that layer-dependent pruning produces superior memory-performance trade-offs, challenging the uniform allocation paradigm. By linking sensitivity to representation metrics, it enables principled allocation for arbitrary models and tasks without retraining. Practically, DepthKV is well-suited for deployment in resource-constrained inference settings (e.g., agent workflows, retrieval-based generation, multimodal long-context processing).
Future directions include integration of query-aware token importance for adaptive retrieval, joint modeling of layer-wise and head-wise sensitivity, and exploration of synergistic effects with system-level cache optimization. Theoretical implications extend to understanding depth-wise functional heterogeneity in transformer networks and applying representation metrics as universal proxies for layer utility.
Conclusion
DepthKV establishes that transformer layers exhibit statistically significant, dataset-dependent heterogeneity in sensitivity to KV cache pruning. By reallocating a fixed global cache budget via layer-dependent importance signals, the framework consistently improves both quantitative and qualitative performance measures across summarization, QA, and reasoning tasks. The results underscore the value of exploiting hidden state metrics for efficient inference scaling and highlight new research avenues for representation-driven model compression and pruning (2604.24647).

