- The paper introduces a two-stage approach using cross-modal alignment pretraining and local anchor fusion to enhance RGB-T crowd counting.
- It achieves significant improvements in GAME and RMSE metrics on RGBT-CC and Drone-RGBT benchmarks compared to previous methods.
- The approach improves interpretability and efficiency via reliability-aware modality weighting and a discrepancy-aware consistency constraint.
Reliability-Aware Crowd Anchor Network (RACANet) for RGB-T Crowd Counting
Crowd counting in unconstrained scenes is confounded by the variable reliability and misalignment of visible-spectrum (RGB) and thermal (T) modalities. Existing RGB-T approaches typically utilize implicit fusion, which neglects local spatial discrepancies and lacks explicit reliability modeling at the positional level. This often limits accuracy and interpretability, particularly in environments characterized by fluctuating illumination, occlusion, and thermal noise. The RACANet framework addresses these deficits via a structured two-stage pipeline: cross-modal alignment pretraining and a reliability-aware local anchor fusion module.
Architecture and Methodology
RACANet employs a dual-branch PVTv2 backbone, extracting multi-scale features from coarsely aligned RGB-T image pairs. The training pipeline is split into two distinct stages:
- Stage 1: Cross-Modal Alignment Pretraining
Lightweight pretraining leverages crowd-aware prior supervision and bidirectional soft matching within local spatial windows to explicitly learn cross-modal semantic correspondences. Crowd-aware priors, governed by point-annotation supervision and low-dimensional feature projection, are utilized to conditionally focus feature alignment on regions with relevant crowd semantics, avoiding diffuse background confusion.
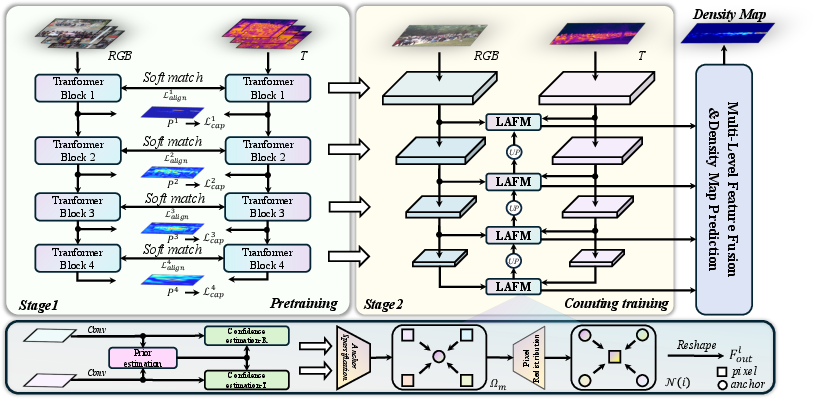
Figure 1: Overview of RACANet, showing dual-branch backbone, crowd-aware prior generation, reliability estimation, anchor aggregation, and pixel-level semantic redistribution.
- Stage 2: Formal Counting with Local Anchor Fusion Module (LAFM)
The pretrained priors inform the LAFM, which achieves position-level modality reliability modeling, sparse anchor aggregation, and adaptive pixel-level semantic redistribution. Modality-specific reliability maps are estimated via lightweight convolutional branches, fused through reliability-weighted joint features. Within local anchor windows, regional prototypes are constructed via reliability-weighted aggregation; these anchors are then used to redistribute semantic information to pixels, guided by local attention mechanisms, enforcing statistical parsimony and interpretability.
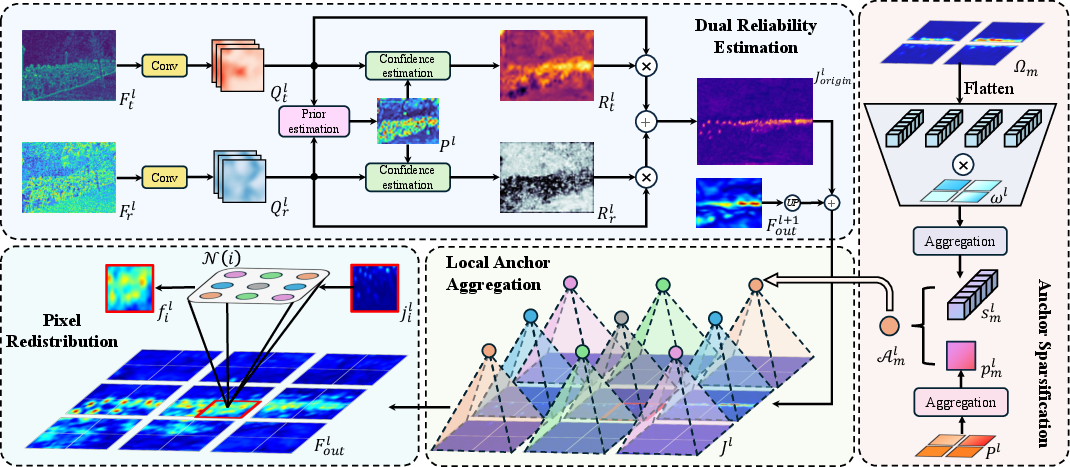
Figure 2: Architecture of LAFM, depicting reliability estimation, anchor sparsification, and anchor-guided pixel redistribution.
A discrepancy-aware consistency constraint is imposed to regularize reliability maps, enforcing strong reliability coherence in semantically consistent regions, yet preserving modality specificity and complementarity in discrepant zones. Density regression is performed using a progressive multi-scale decoder and Bayesian loss formulation, providing robust optimization under point-level supervisions.
Quantitative Evaluation and Ablation Analysis
RACANet is validated on the RGBT-CC and Drone-RGBT benchmarks, comprising diverse illumination and viewpoint conditions. Across all GAME metrics and RMSE, RACANet achieved substantial improvements over all competing RGB-T crowd counting approaches.
- On RGBT-CC, RACANet reduced GAME(0) by 6.61% and RMSE by 3.72% versus the best previous method.
- On Drone-RGBT, RACANet reduced GAME(0) by 15.65% and RMSE by 21.35% over the strongest competitor.
- Ablation studies demonstrate the critical impact of the pretraining stage, LAFM, and discrepancy-aware loss (λcons=0.1 optimal). LAFM yields lightweight design (parameter reduction) and increased inference speed.
- RACANet with the PVTv2 backbone offers superior parameter efficiency and computational cost compared to CNN and hybrid Transformer alternatives.
Qualitative Analysis
Visualization confirms RACANet's adaptive modality reliability assessment and robust density estimation under challenging scenarios. The model dynamically exploits modality complementarity: RGB reliability is dominant where visual signal is strong and thermal reliability prevails in low-light or thermal-interference conditions. LAFM effectively filters background clutter and highlights crowd regions, culminating in accurate density maps that closely match ground truths across dense, sparse, and mixed environments.

Figure 3: RACANet visualization under varying scenarios; adaptive modality reliability and accurate crowd density estimation are evident.
Implications and Future Directions
RACANet introduces explicit local alignment and fine-grained reliability modeling into multimodal crowd counting. The two-stage fusion pipeline with pretraining enables spatially robust fusion and interpretability, facilitating deployment in real-world scenarios with heterogeneous sensor reliability and misalignment. RACANet's principles—local correspondence learning, sparse anchor aggregation, and discrepancy-aware reliability—may inform future multimodal vision systems, salient object detection, and robust sensor fusion tasks in urban analytics and autonomous monitoring.
The framework's modularity and ablation-validated efficiency suggest extensibility to additional modalities or more severe spatial misalignment regimes, potentially incorporating self-supervised or domain-adaptive pretraining. Advances in anchor representation and adaptive attention mechanisms could further augment performance and scalability.
Conclusion
RACANet delivers a reliability-aware, two-stage architecture for RGB-T crowd counting, combining explicit cross-modal alignment pretraining with local anchor-based fusion. Strong empirical results validate its superiority in accuracy and robustness against state-of-the-art methods. The model's local priors, reliability-aware fusion, and discrepancy-aware constraints collectively enhance interpretability and operational applicability in complex multimodal environments (2604.24543).