- The paper introduces a diagnostic framework that quantifies the impact of text priors versus genuine acoustic processing in audio-language models.
- It demonstrates that models retain 60–72% of their full-audio accuracy without any audio, indicating heavy reliance on local, textual shortcuts.
- The findings highlight the need for benchmarks that enforce full contextual audio input to ensure robust, holistic auditory reasoning.
Rethinking Audio-Language Evaluation: Text Priors and True Audio Reliance
Introduction
Recent advances in large audio-LLMs (LALMs) have produced consistently increasing benchmark scores on complex audio tasks. However, these metrics are frequently interpreted as evidence of genuine auditory understanding without critical examination of the underlying dependencies between text priors and actual audio processing. The work "All That Glitters Is Not Audio: Rethinking Text Priors and Audio Reliance in Audio-Language Evaluation" (2604.24401) introduces a systematic diagnostic framework that rigorously quantifies the degree to which current LALM benchmarks and models are truly grounded in the audio signal, as opposed to leveraging pre-existing linguistic or world knowledge from textual cues alone. This contribution is both practical and theoretically significant for guiding the design of future benchmarks and LALMs.
The authors analyze three prominent benchmarks (MMAU, MMAR, and MMAU-Pro) and eight state-of-the-art LALMs. They reveal a persistent, substantial text prior—models retain 60–72% of their full-audio accuracy with no audio input. Furthermore, only 3–4% of audio-required items necessitate holistic, global listening; most are solvable from short, local fragments. These findings demand a reevaluation of the mechanisms by which LALMs achieve benchmark success and question the validity of existing evaluation paradigms for auditory perception.
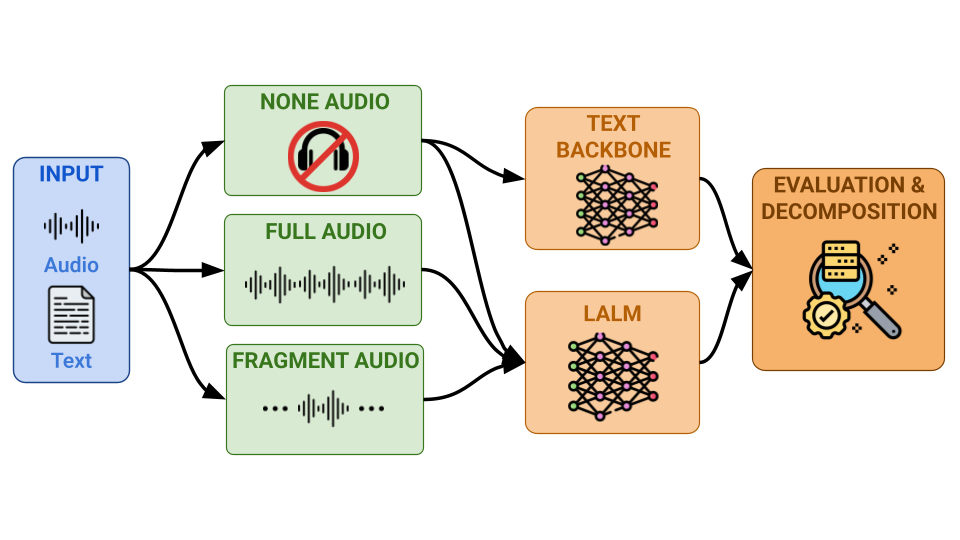
Figure 1: Overview of the proposed diagnostic framework.
Diagnostic Framework: Text Prior and Audio Reliance
The paper posits two fundamental axes for audit:
- Text Prior: The extent to which benchmark items can be solved using only the textual question and model’s pre-trained general knowledge.
- Audio Reliance: A quantitative metric of to what degree model predictions depend on the acoustic signal, and more specifically, whether that dependence is on short, local segments or the entire clip.
For text prior estimation, the authors use three conditions: the original text-only backbone of the LALM, the multimodal LALM evaluated with audio omitted, and the typical audio-plus-text setup. The comparison between these settings isolates the contribution of non-acoustic priors. The text-prior rate is operationalized as Accnone/Accfull, summarizing the fraction of full-audio accuracy possible without any audio.
Audio reliance is assessed by partitioning each audio clip into N equal-length fragments and measuring the retention rate—how much accuracy is preserved when only a fragment is given. This allows for separation between models requiring global understanding (low retention with fragments) and those operating on spurious short cues (high retention).
Quantitative Analysis of Benchmarks and Models
Empirical evaluation covers eight contemporary LALMs, ranging from compact to high-capacity models, across three challenging benchmarks: MMAU, MMAR, and MMAU-Pro. Key findings include:
- Text-only baselines (either the LALM text backbone or multimodal LALM with audio omitted) often far exceed chance performance, sometimes achieving up to half the full-audio accuracy.
- Most LALMs, after audio-language training, exhibit increased text prior compared to their original language-only backbone. Text-prior rates are consistently high, with average rates over 60% for all three benchmarks.
- The gap between text-only and audio-plus-text accuracy reveals that benchmark scores may grossly overestimate models’ actual auditory reasoning capabilities.
Fine-grained Disaggregation: Local vs. Global Audio Cues
To disambiguate between models truly integrating audio and those exploiting local cues, the authors perform fine-grained item-level analysis:
- For audio-reliant items, only 3–4% require the entire clip (cross-fragment/global dependency); the rest are solvable with a single fragment.
- The distribution across evaluation categories (Text-Solvable, Fragment-Sufficient, Cross-Segment, etc.) showcases that only a minority of items are genuinely contingent on holistic, non-local audio reasoning.
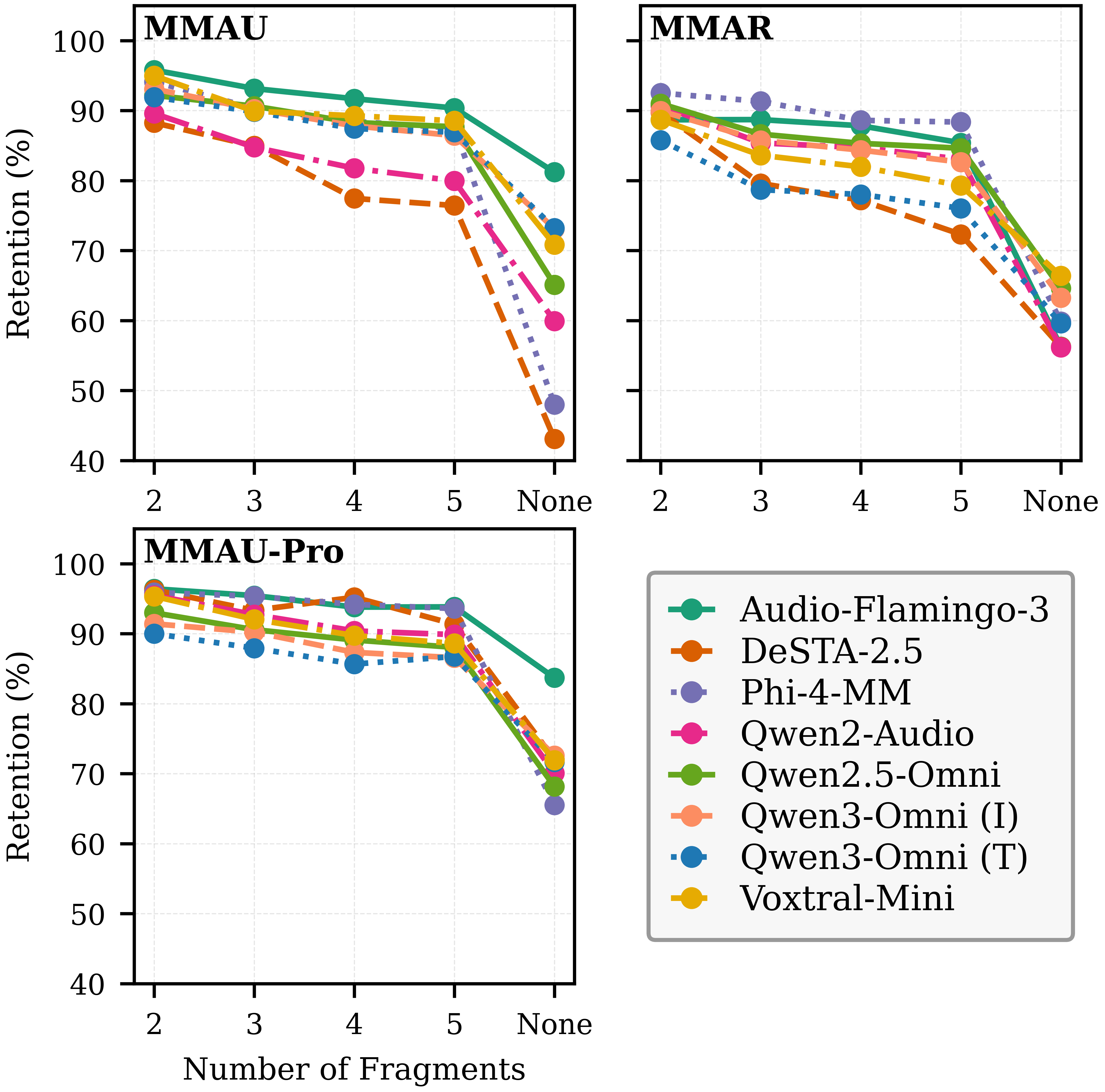
Figure 2: Retention rate (\%) across three benchmarks for eight models. Higher retention indicates reliance on localized audio cues.
Figure 3: Model-averaged stacked distribution of item categories across the three benchmarks.
Task-type analysis (instruction-following, speech, sound, music, open-ended) further corroborates these insights: multiple-choice tasks in particular retain high accuracy from short segments, with open-ended tasks occasionally showing audio as a distractor when compared to text priors.
Implications for Benchmark and Model Design
These findings underscore a fundamental misalignment between what benchmark scores purport to measure (holistic auditory reasoning) and what they actually reward (textual shortcuts and local cues). For both practical and theoretical advances in LALMs, the following implications are paramount:
- Benchmark creators need to prioritize diagnostics for text prior and fragment sufficiency: benchmarks should be constructed or filtered such that text-only or short-fragment accuracy is near chance, mitigating superficial shortcut exploitation.
- Model developers must report baseline text-only scores and perform ablations using fragment-level analysis to ensure enhancements arise from true auditory cognition rather than degenerate multimodal shortcuts.
- Emphasis should shift towards tasks and datasets that enforce long-range dependency on the entire audio context, rewarding models with robust global auditory understanding.
Future Directions
This framework opens several promising research trajectories. Automated auditing tools that enforce low text prior and high cross-segment dependence during item curation would systematize benchmark improvement. Additionally, multimodal pre-training strategies might benefit from adversarial augmentation to force reliance on long-context audio evidence. Finally, a granular analysis of failure modes (e.g., "audio-harmful" items where audio input decreases accuracy) could inform methods for robustly integrating acoustic and textual information.
Conclusion
This work provides a rigorous, actionable critique of current audio-language evaluation paradigms. By operationalizing text prior and audio reliance, the authors demonstrate that most progress as measured by prevalent benchmarks is illusory—predicated upon spurious textual cues and localized signal patterns. Iterative integration of these diagnostic axes is essential for benchmarking and developing LALMs that genuinely understand and reason over real-world auditory input.

