- The paper introduces dynamic token-level soft modality scores that enable adaptive routing across layers in MoE-VLMs.
- It employs attention and Gaussian-statistics methods to refine modality fusion, resulting in improved expert specialization and task accuracy.
- The study shows that adaptive expert binning combined with mutual information regularization enhances deployment efficiency and reduces communication overhead.
Soft Modality-Guided Expert Specialization in MoE-VLMs: A Technical Analysis
Background and Motivation
Mixture-of-Experts (MoE) architectures have become the dominant design for large vision-LLMs (VLMs), enabling efficient scalability via conditional computation. Existing MoE-VLMs adopt either hard or soft expert routing but fail to model the dynamic, layer-dependent fusion of modalities—vision and text—leading to suboptimal expert specialization and efficiency. Hard routing enforces strict modality–expert separation, impeding adaptation to cross-modal features, while soft routing allows arbitrary mixing without explicit modality guidance, resulting in over-mixing and load imbalance.
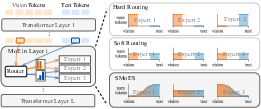
Figure 1: Comparison of routing strategies in MoE-VLMs. Hard routing enforces modality separation; soft routing allows uncontrolled mixing; SMoES uses soft modality scores for adaptive expert specialization.
Empirical analysis reveals that modality fusion in MoE-VLMs is highly heterogeneous and varies across layers. Token-level modality affiliation is neither binary nor static; instead, fusion emerges gradually, with text and vision tokens mixing dynamically as deep layers evolve. This layer-dependent heterogeneity necessitates routing strategies informed by actual modality fusion patterns rather than hand-crafted or modality-agnostic priors.
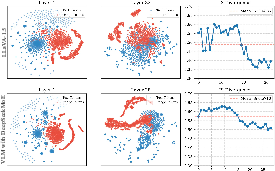
Figure 2: Modality fusion pattern across models and layers. JS divergence trajectories capture differences in vision/text token distributions.
Methodology
Soft Modality Scores
SMoES introduces dynamic, token-level soft modality scores to track evolutionary fusion states across layers. Two estimation paradigms are proposed:
- Attention-Accumulated Score: The modality score is propagated using layer-wise, head-averaged attention weights, reflecting token interactions and residual structure. Initial hard modality labels are refined via weighted aggregation and residual update, mirroring Transformer dynamics.
- Gaussian-Statistics Score: Per-layer, per-modality Gaussian distributions are maintained using exponential moving averages of token embeddings. Each token's modality affinity is computed via temperature-scaled log-likelihood under learned feature distributions, capturing global statistical tendencies.
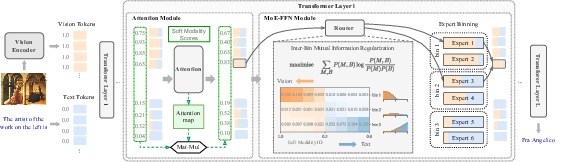
Figure 3: Overview of SMoES. Soft scores refined by attention or Gaussian statistics; expert binning for deployment; mutual information regularization for specialization.
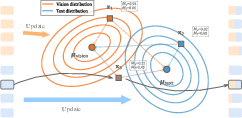
Figure 4: Gaussian-statistics score estimation. Affinity via log-likelihood under continuously updated modality distributions.
To align specialization with deployment, SMoES employs adaptive "expert binning," grouping experts by modality bias measured using EMA statistics. Each bin is encouraged to develop coherent modality preference, facilitating device placement and communication minimization in expert-parallel (EP) settings.
Mutual Information (MI) regularization is applied inter-bin, maximizing I(M;B) to ensure that bin assignment is informative about token modality. This produces sharp, coherent specialization patterns and enables optimal routing by learning affinity at bin granularity, matching hardware deployment units.
Experimental Results
Effectiveness and Specialization
SMoES was evaluated across four MoE-VLM backbones (DeepSeekMoE, OLMoE, Moonlight-MoE, Qwen3-MoE) and 16 multimodal and language benchmarks. Compared to traditional soft routing, SMoES achieves substantial gains in both multimodal (+0.9%) and language-only (+4.2%) tasks. Attention-based and Gaussian-based scores outperform hard routing and hybrid approaches, with greater improvements noted in language-centric benchmarks where prior modality-specialized methods often degrade performance due to rigid allocation.
Ablation Studies
The role of soft modality scores and MI-based objectives was validated via ablations. Hard-score (binary) achieves high specialization index (MSI), but soft scores (attention-soft and gaussian-soft) yield superior task performance by accommodating fusion dynamics. Expert binning improves both MSI and throughput; MI regularization is essential, outperforming KL-based approaches (e.g., SMAR) in both accuracy and coherence.
Binning granularity experiments reveal a trade-off: more bins allow finer specialization but may incur deployment imbalance, whereas fewer bins limit specialization efficiency.
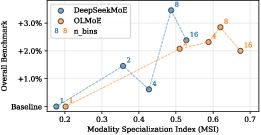
Figure 5: Ablation on number of expert bins.
Visualization of Specialization Patterns
SMoES yields distinct bin-modality correspondence, especially in shallow layers with clear modality separation. Deeper layers show increased fusion, matching natural feature blending. Dynamic training curves demonstrate stable specialization versus baseline collapse to mixed-modal experts.
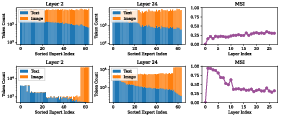
Figure 6: Routing distribution of tokens to experts in DeepSeekMoE. SMoES achieves sharper differentiation.
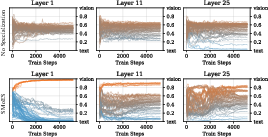
Figure 7: Evolution of expert specialization during training. SMoES maintains strong differentiation; baseline collapses.
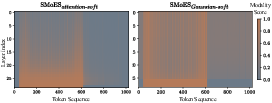
Figure 8: Soft modality score across layers—gradual fusion observed especially in deeper layers.
Deployment Efficiency
Specialization improves efficiency in distributed EP deployments by routing tokens to modality-aligned experts, reducing cross-device communication. SMoES enables significant transfer ratio reductions (up to 86% for vision tokens), lowering overhead and latency. Asynchronous transmission and expert co-location further accelerate inference, particularly for large batches and vision-dominant inputs.
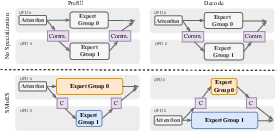
Figure 9: Expert-parallel deployment on two GPUs—modality-aligned bin placement reduces communication.
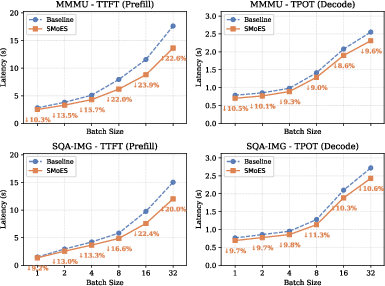
Figure 10: Latency decrease of SMoES compared to baseline at various batch sizes; improvements in TTFT and TPOT.
Implications and Future Directions
SMoES demonstrates that modality-guided, learnable specialization is critical for unlocking MoE-VLM capacity and deployment efficiency. By unifying adaptive soft modality scores, bin-based expert allocation, and MI-driven objectives, SMoES achieves a balance between flexibility, task accuracy, and efficiency not attainable via hard-coded routing.
Practical implications extend to real-time edge deployment, where memory and bandwidth are constrained, and to cloud-scale inference where communication costs dominate. SMoES's learnable specialization is inherently extensible to more sophisticated density modeling; preliminary results with Gaussian mixtures indicate further gains may be realized with richer token distribution modeling.

Figure 11: Routing distribution across bins in DeepSeekMoE and OLMoE.
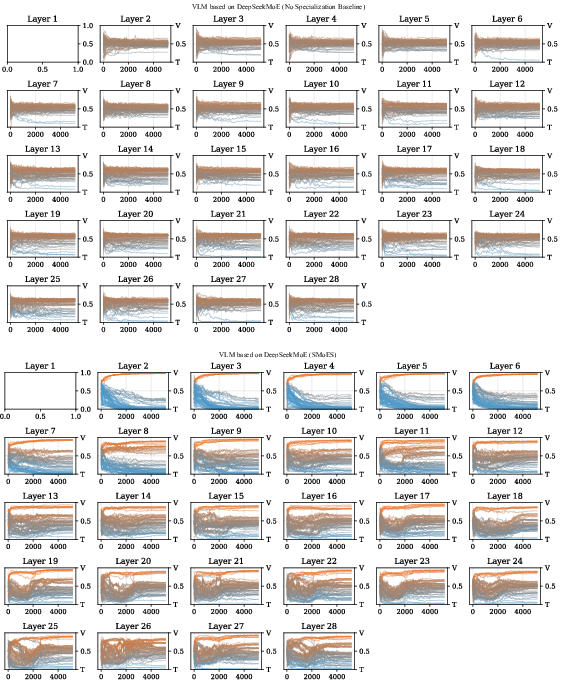
Figure 12: Evolution of specialization in DeepSeekMoE—differentiation maintained throughout training.

Figure 13: Specialization collapse in Qwen3-MoE baseline, highlighting the necessity of explicit specialization objectives.

Figure 14: Robust specialization with SMoES in Qwen3-MoE.
Conclusion
SMoES redefines expert specialization in MoE-VLMs via dynamic, soft modality-guided routing, adaptive binning, and MI regularization. Empirical gains in both task performance and deployment efficiency validate its superiority over modality-agnostic and hand-crafted specialization approaches. SMoES lays a data-driven foundation for scalable, efficient, and unified multimodal models, opening further research in density modeling and large-scale distributed deployment strategies.