- The paper presents SROT as an innovative formulation that leverages a sliced OT (SOT) prior to achieve higher fidelity to exact optimal transport while maintaining Sinkhorn scalability.
- Empirical results on synthetic datasets, color transfer, and gradient flows demonstrate that SROT consistently reduces bias compared to traditional entropic OT under varying regularization.
- The study offers deep theoretical insights and practical algorithms for integrating informative priors in OT, setting the stage for advances in generative modeling and statistical inference.
Motivation and Problem Context
Optimal transport (OT) and its computational relaxations—most notably entropic OT (EOT)—have become foundational for mathematical modeling across machine learning, statistics, and computer vision. EOT leverages entropic regularization which, by penalizing deviation from the independent coupling, enables efficient computation via the Sinkhorn algorithm and yields the Sinkhorn divergence, a metric with favorable statistical and computational properties. However, the independent coupling prior used in EOT is typically non-informative with respect to the structure of the true OT plan, leading to regularization-induced bias especially at moderate ε. While recent extensions (quadratic, sparse, or low-rank regularization) encode desirable inductive biases, they do not explicitly favor plans close to the true OT solution and can thus degrade transport geometry.
The paper "Sliced-Regularized Optimal Transport" (2604.23944) addresses this limitation by proposing a novel regularized OT formulation—Sliced-Regularized Optimal Transport (SROT)—which regularizes towards a sliced OT (SOT) plan, a proxy for the true OT plan derived from aggregating one-dimensional projections. SROT replaces the independent prior with a smoothened SOT plan, aiming for higher fidelity to the exact OT geometry at equivalent regularization strengths, while retaining Sinkhorn scalability.
SROT modifies the classical entropic regularization framework by introducing a SOT plan πSOT as the KL prior for regularization, leading to the optimization:
πε,SOT⋆=argπ∈Π(μ,ν)min∫c(x,y)dπ(x,y)+εKL(π∣πSOT)
As ε→0, SROT recovers the exact OT; as ε→∞, it converges to the SOT plan. To ensure full support, the prior is practical as a convex combination of the SOT plan and the independent coupling, though empirical evidence supports success with the pure SOT prior in most cases.
The dual formulation mirrors EOT, but integrates with respect to the SOT reference coupling. The optimal plan admits the closed-form:
dπε⋆(x,y)=exp(εf⋆(x)+g⋆(y)−c(x,y))dπSOT(x,y)
where (f⋆,g⋆) are dual potentials.
The SROT divergence, defined analogously to the Sinkhorn divergence, is constructed as:
Sε,SOT(μ,ν)=OTε,SOT(μ,ν)−21OTε,SOT(μ,μ)−21OTε,SOT(ν,ν)
The divergence is proved symmetric, non-negative, and metrizes weak convergence for any ε>0, thus suitable for estimation, alignment, and generative modeling tasks.
Computational Algorithms and Sinkhorn Scaling
SROT retains the computational efficiency of Sinkhorn scaling. The SOT plan in the discrete setting is efficiently constructed via sorting and aggregation across pre-sampled projections. The matrix scaling steps are structurally identical to EOT, except with the reference coupling replaced:
K=PSOT⊙exp(−C/ε)
with scaling iterations for marginals and the final plan:
πSOT0
The additional computational cost of constructing πSOT1 is negligible relative to Sinkhorn iterations, even for moderate numbers of projections.
Empirical Results
Synthetic Datasets
The paper evaluates SROT against EOT and SOT across several synthetic probability distributions—half moon, 8 Gaussians, and two rings—visualizing and quantifying transport plan fidelity relative to exact OT.
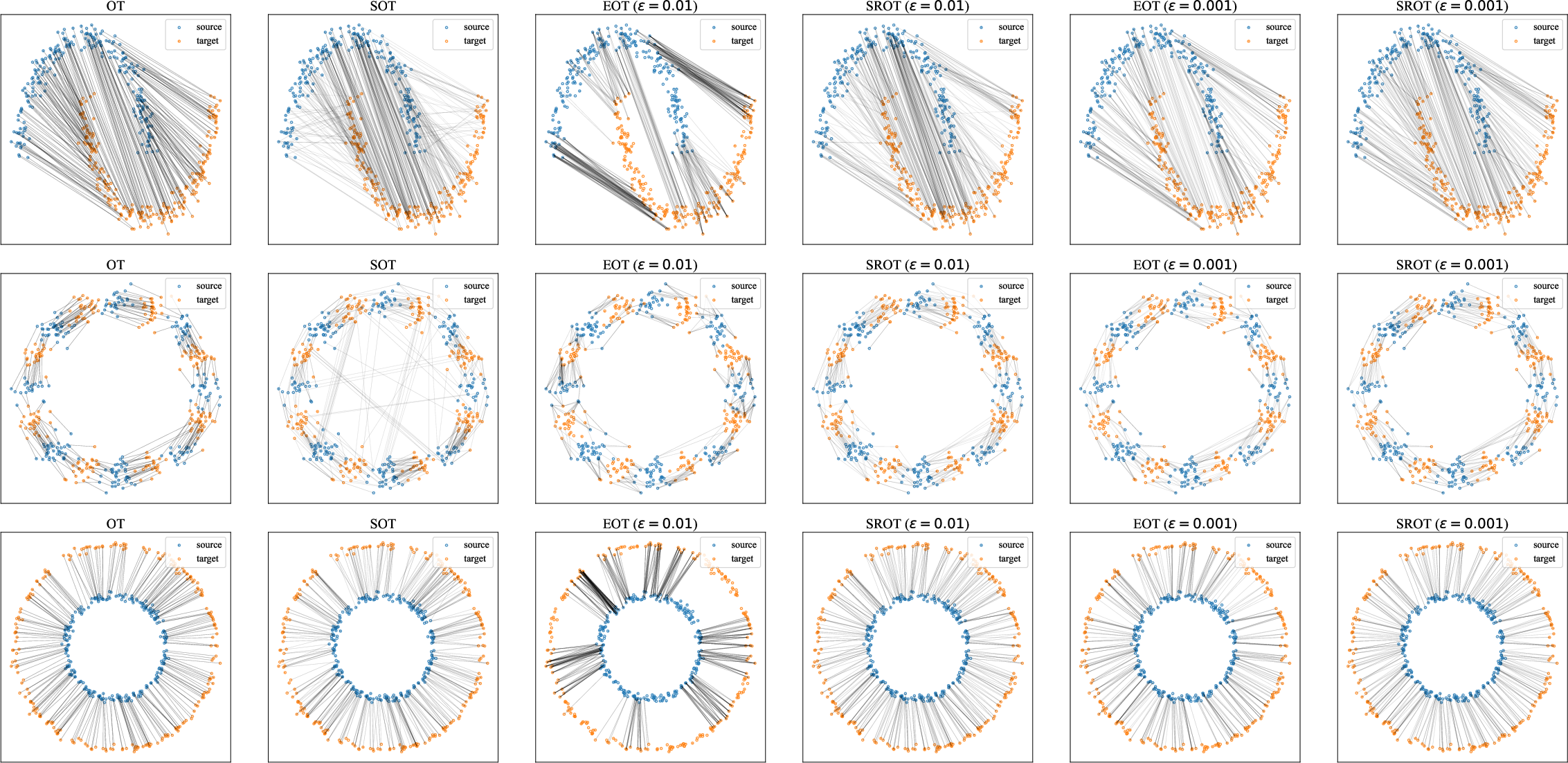
Figure 2: Visualization of transportation plans from OT, SOT, EOT, and SROT for synthetic datasets.
SROT consistently yields transport plans closer to the exact OT than EOT at comparable levels of regularization, with superior robustness even when the SOT prior itself deviates significantly from OT (notably in the 8 Gaussians case).
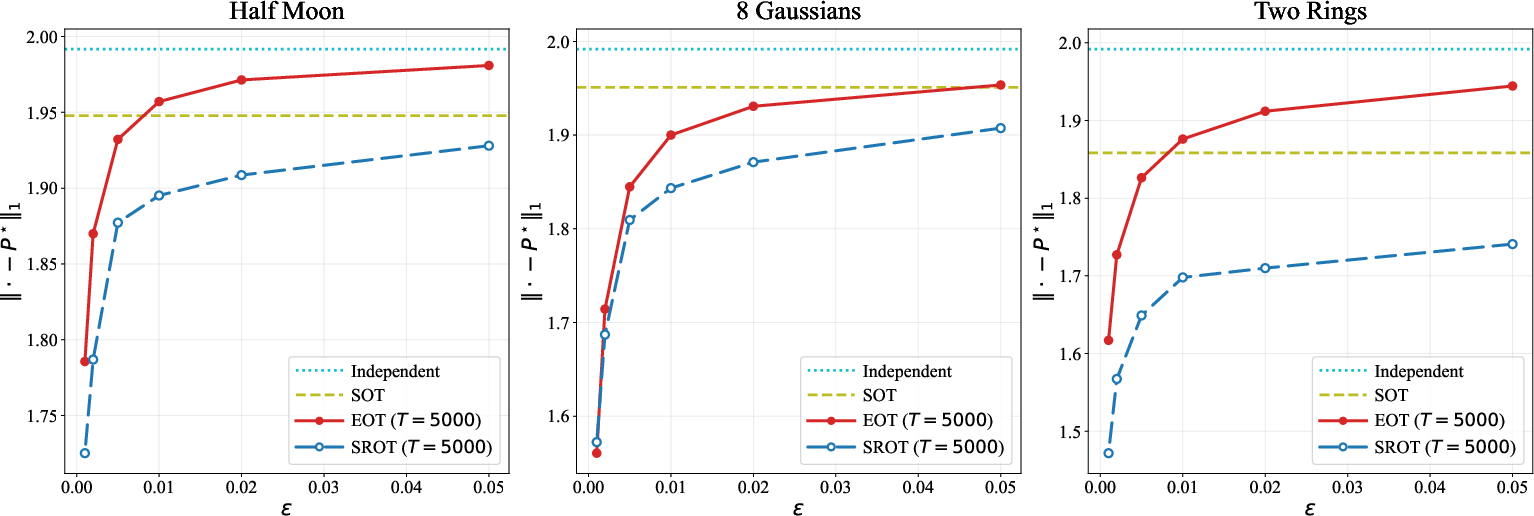
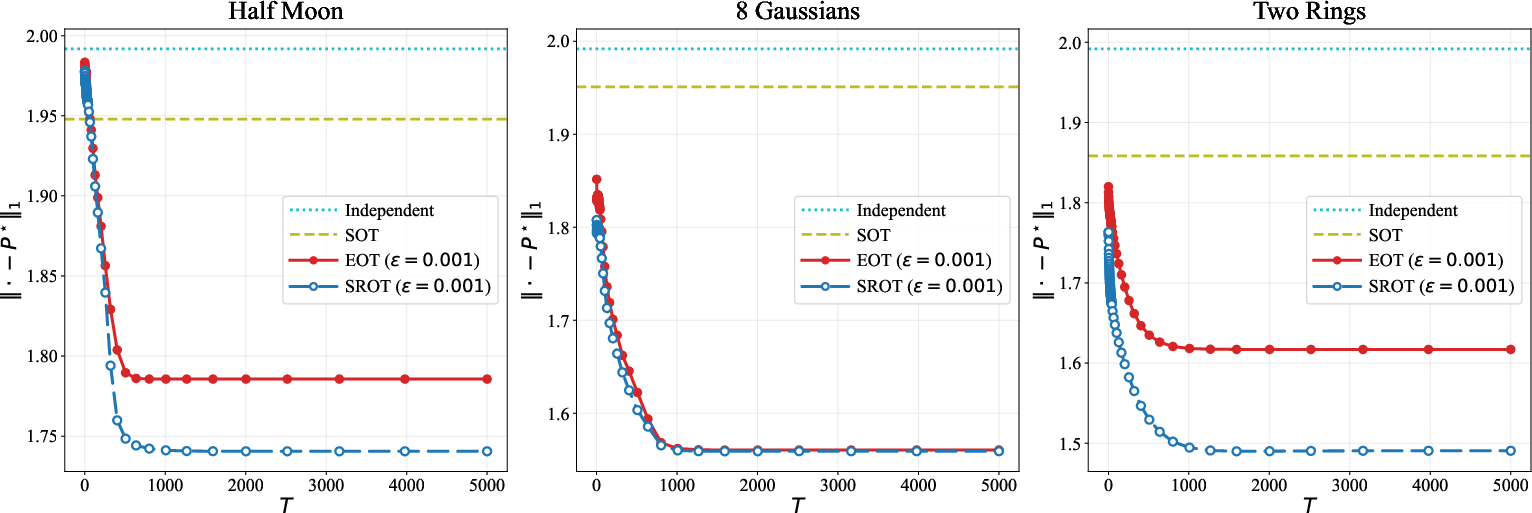
Figure 4: Ablation studies of varying the regularization strengths (πSOT2) and Sinkhorn iterations (πSOT3).
Across variations in πSOT4 and Sinkhorn iteration counts, SROT demonstrates tighter approximation error versus OT. SOT serves as a stronger prior than the independent coupling; SROT maintains lower bias than EOT across nearly all tested hyperparameters.
Color Transfer
In image processing, color transfer tasks were benchmarked across 132 pairs. Each image is matched as a discrete weighted point cloud in RGB space. The mean πSOT5 errors to exact OT plans are lowest for SROT at all regularization strengths. Qualitative results show SROT plans yield visually more faithful transfers relative to EOT and SOT.






Figure 1: Color transfer results of OT, SOT, EOT, and SROT.
Gradient Flows
Gradient flows driven by Sinkhorn divergence or SROT divergence demonstrate practical advantages. Notably, for small πSOT6, SROT divergence induces weaker repulsion (πSOT7, πSOT8) than Sinkhorn; however, for larger πSOT9, SROT gradient flows converge faster in Wasserstein distance, confirming more effective bias correction throughout the flow.




Figure 3: Gradient flows of Sinkhorn divergence and SR divergence with Wasserstein distance as neutral evaluation metric.


Figure 5: Gradient flows of Sinkhorn divergence and SR divergence with Wasserstein distance as neutral evaluation metric.
Ablation: Number of Projections
Robustness to the number of projections used in SOT computation was established. Uniform SOT averaging is generally recommended, although alternatives (softmin, min cost) can yield incremental improvements for specific geometries.
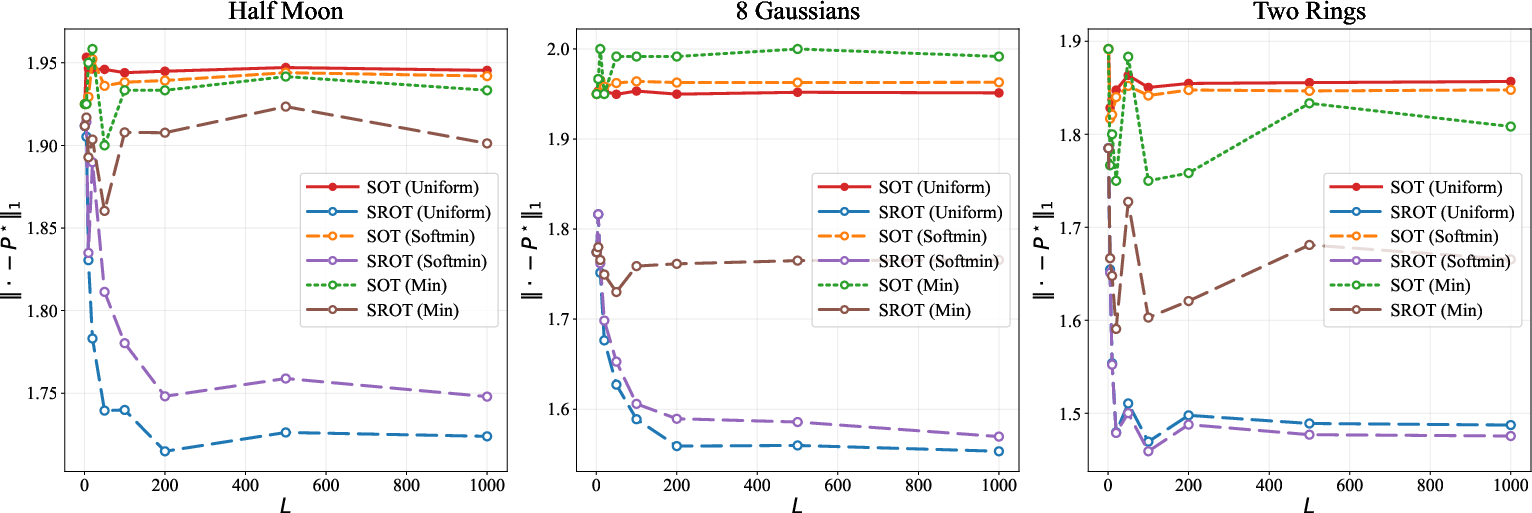
Figure 6: Ablation study of varying the number of projections πε,SOT⋆=argπ∈Π(μ,ν)min∫c(x,y)dπ(x,y)+εKL(π∣πSOT)0.
Discussion, Implications, and Future Directions
SROT demonstrates that leveraging a more informative prior—in this case, the SOT plan—substantially improves the fidelity of regularized OT without sacrificing computational tractability. This approach directly addresses the main limitation of entropic regularization: bias towards non-informative independent couplings. The strong numerical results for color transfer and synthetic plan recovery establish SROT as preferable to EOT for OT approximation under moderate regularization. Furthermore, SROT divergence inherits favorable theoretical properties including symmetry, non-negativity, and metrization of weak convergence, opening its application for parameter estimation, generative modeling, and domain adaptation.
Key future directions include:
- Statistical analysis of SROT: sample complexities, central limit behavior, and consistency properties in parameter estimation.
- Optimization of SOT priors: learning projection distributions and aggregation strategies for different metric geometries to further enhance plan fidelity.
- Extensions to unbalanced, partial, and semi-discrete OT settings, leveraging the modularity of the regularization framework.
- Integration of SROT in scalable deep generative models and neural optimal transport architectures.
Conclusion
The SROT framework establishes a regularized OT paradigm driven by informative priors derived from sliced OT plans, achieving superior accuracy relative to EOT and robust scalability. Theoretical analysis and empirical validation support its adoption across OT-driven tasks, including generative modeling, statistical inference, and image processing. SROT's post-Bayesian interpretation, duality structures, and divergence properties ensure its theoretical and practical integration with classical and advanced OT methodology (2604.23944).

