- The paper introduces a deep compression video autoencoder (DC-AE-V) that achieves up to 14.8× inference speedup with minimal quality degradation.
- It employs a novel chunk-causal temporal modeling strategy that balances intra-chunk bidirectional flow with cross-chunk causality to ensure scalable video generation.
- The framework uses AE-Adapt-V with LoRA fine-tuning to align embedding spaces and reduce adaptation costs by 230× compared to full pre-training.
DC-VideoGen: Efficient Video Generation with Deep Compression Video Autoencoder
Introduction
DC-VideoGen presents a post-training acceleration framework for video diffusion models, targeting the prohibitive computational costs associated with high-resolution and long-duration video synthesis. The framework is designed to be model-agnostic, enabling efficient adaptation of any pre-trained video diffusion model to a highly compressed latent space with minimal fine-tuning. The two principal innovations are: (1) a Deep Compression Video Autoencoder (DC-AE-V) with a novel chunk-causal temporal modeling strategy, and (2) AE-Adapt-V, a robust adaptation protocol for transferring pre-trained models into the new latent space. The result is a system that achieves up to 14.8× inference speedup and supports 2160×3840 video generation on a single NVIDIA H100 GPU, with negligible quality degradation and drastically reduced training costs.
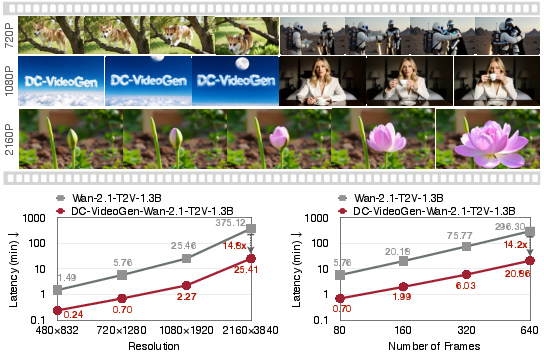
Figure 1: DC-VideoGen can generate high-quality videos on a single NVIDIA H100 GPU with resolutions ranging from 480px to 2160px, achieving up to 14.8× acceleration over the Wan-2.1-T2V-1.3B model.
Deep Compression Video Autoencoder (DC-AE-V)
Motivation and Design
Conventional video autoencoders in latent diffusion models typically achieve moderate compression ratios (e.g., 8× spatial, 4× temporal), which are insufficient for efficient high-resolution or long video generation. DC-AE-V addresses this by achieving 32×/64× spatial and 4× temporal compression, while maintaining high reconstruction fidelity and generalization to longer videos.
The core innovation is the chunk-causal temporal modeling paradigm. Unlike strictly causal or non-causal designs, chunk-causal modeling divides the video into fixed-size chunks, applies bidirectional temporal modeling within each chunk, and enforces causality across chunks. This enables the model to exploit intra-chunk redundancy for reconstruction quality, while maintaining the ability to generalize to longer sequences at inference.

Figure 2: Illustration of chunk-causal temporal modeling in DC-AE-V, which enables bidirectional flow within chunks and causal flow across chunks, balancing reconstruction quality and generalization.
Empirical Analysis
Empirical results demonstrate that DC-AE-V outperforms both causal and non-causal autoencoders in terms of PSNR, SSIM, LPIPS, and FVD at equivalent or higher compression ratios. Notably, non-causal autoencoders, while achieving better reconstruction on short clips, fail to generalize to longer videos due to temporal dependency leakage, often resulting in flickering and boundary artifacts.

Figure 3: Video autoencoder reconstruction visualization. Causal autoencoders degrade under deep compression, while non-causal models generalize poorly to longer videos.
Ablation studies on chunk size reveal that increasing chunk size improves reconstruction up to a saturation point, beyond which computational cost outweighs marginal gains.
AE-Adapt-V: Post-Training Adaptation Protocol
Naïve Adaptation Pitfalls
Directly replacing the autoencoder in a pre-trained video diffusion model and randomly initializing the patch embedder and output head leads to severe training instability and suboptimal quality. The embedding space mismatch disrupts the transfer of semantic knowledge from the pre-trained backbone, often resulting in catastrophic forgetting or output collapse.
Video Embedding Space Alignment
AE-Adapt-V introduces a two-stage alignment protocol:
- Patch Embedder Alignment: Freeze the base model's patch embedder, train a new patch embedder to minimize the MSE between the new and base embeddings (after spatial downsampling), ensuring the new latent space is mapped compatibly into the pre-trained embedding space.
- Output Head Alignment: With the patch embedder aligned, jointly fine-tune the output head and patch embedder (keeping the backbone frozen) using the diffusion loss until convergence.
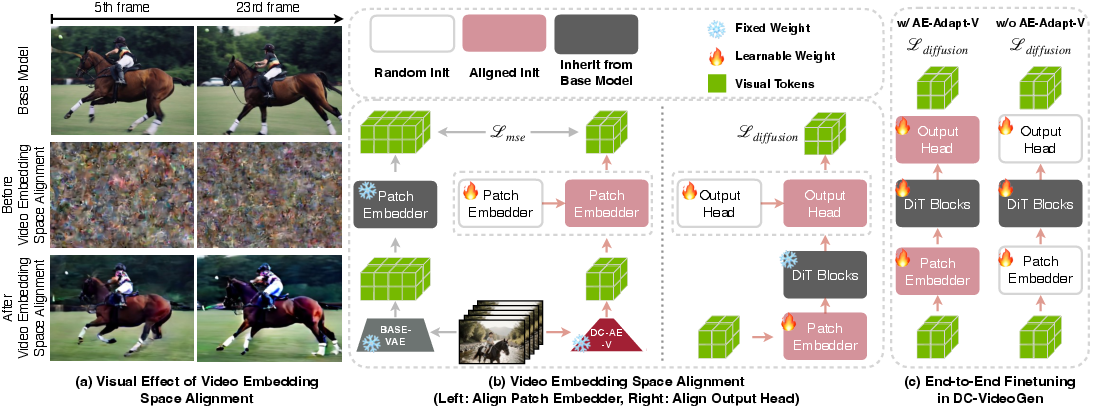
Figure 4: Illustration of video embedding space alignment, showing the necessity of aligning both the patch embedder and output head for effective adaptation.
This alignment protocol enables rapid recovery of the base model's quality and semantics in the new latent space, as evidenced by both quantitative and qualitative metrics.
End-to-End Fine-Tuning with LoRA
After alignment, lightweight end-to-end fine-tuning is performed using LoRA. LoRA tuning not only reduces the number of trainable parameters but also better preserves the pre-trained model's knowledge compared to full fine-tuning, resulting in higher VBench scores and improved visual quality.

Figure 5: Direct fine-tuning without AE-Adapt-V is unstable and yields poor quality. AE-Adapt-V enables rapid, stable adaptation and quality recovery.
Efficiency and Quality Benchmarks
DC-VideoGen achieves substantial acceleration across resolutions and video lengths. For example, at 2160×3840 resolution, DC-VideoGen delivers a 14.8× speedup over the Wan-2.1-T2V-1.3B baseline, with comparable or superior VBench scores. The framework also reduces adaptation cost to 10 H100 GPU days, a 230× reduction compared to full model pre-training.
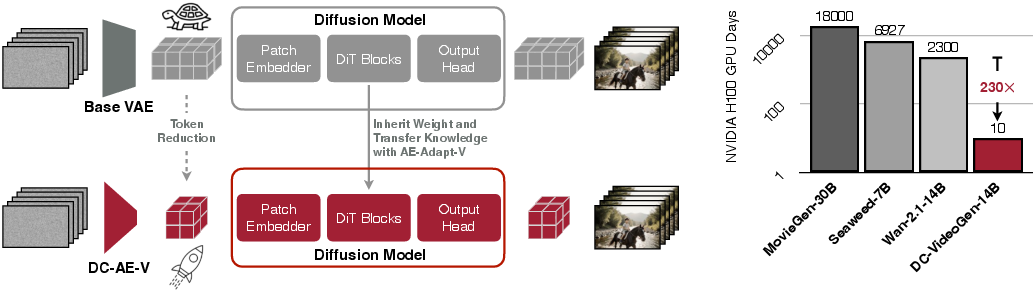
Figure 6: DC-VideoGen overview, illustrating the post-training acceleration pipeline and efficiency gains.
Qualitative comparisons confirm that the accelerated models retain the visual fidelity and semantic consistency of the base models, even at high resolutions and long durations.

Figure 7: Visual comparison of DC-VideoGen-Wan2.1-I2V-14B and the base model, demonstrating preserved generation quality.

Figure 8: Visual comparison of DC-VideoGen-Wan2.1-T2V-14B and the base model, confirming quality retention post-acceleration.
Practical Implications and Limitations
DC-VideoGen enables practical deployment of high-fidelity video diffusion models in resource-constrained environments, democratizing access to large-scale video synthesis. The framework is model-agnostic and can be applied to any pre-trained video diffusion model, facilitating rapid iteration and innovation in the video generation community.
However, the efficacy of DC-VideoGen is contingent on the quality of the pre-trained model. As a post-training framework, it cannot compensate for deficiencies in the base model's generative capacity. Future work should explore extending the framework for ultra-long video generation and further reducing adaptation costs, potentially by integrating with sparse attention or quantization techniques.
Conclusion
DC-VideoGen establishes a new paradigm for efficient video generation by combining a deep compression autoencoder with a robust adaptation protocol. The framework achieves significant acceleration and cost reduction without sacrificing quality, making high-resolution, long-duration video synthesis feasible on commodity hardware. This work demonstrates that efficiency and fidelity in video generation are not mutually exclusive, and sets the stage for further advances in scalable, accessible generative video modeling.