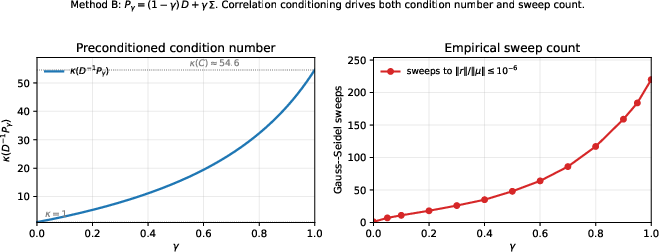
- The paper introduces hierarchical and iterative methods (HRP-μ, HRP-Σμ, CRISP) that integrate signal-aware allocation into general mean-variance portfolio optimization.
- It demonstrates that CRISP achieves 80–94% of the oracle Sharpe and HRP-Σμ outperforms HRP-μ by up to 180% under structured signals, all within an O(N²) computational framework.
- The study provides a closed-form bias–variance trade-off analysis and an adaptive shrinkage rule, offering scalable and interpretable solutions for high-dimensional portfolios.
Hierarchical and Iterative Shrinkage Methods for General Mean-Variance Portfolios: A Technical Summary
The paper "Beyond De Prado and Cotton: Hierarchical and Iterative Methods for General Mean-Variance Portfolios" (2604.23833) conducts a rigorous exploration of hierarchical and iterative frameworks for regularized portfolio optimization, systematically extending and unifying prior work by López de Prado (HRP) and Cotton, and presenting CRISP: the Correlation-Regularised Iterative Shrinkage Portfolio method. Notably, it introduces hierarchical, computationally efficient, and signal-dependent allocations for arbitrary expected-return forecasts, overcoming the 'signal-blindness' inherent in HRP and Cotton's constructions.
Problem Setting and Motivation
The classical Markowitz mean-variance portfolio suffers acute estimation error amplification—especially for off-diagonal sample covariance elements—leading to unstable and economically sub-optimal allocations. Established regularized alternatives such as Hierarchical Risk Parity (HRP) and the Schur-complement algorithm presented by Cotton provide improved robustness but are fundamentally limited to the minimum-variance setting (μ=1) and discard return forecasts entirely. These limitations misalign with practical portfolio construction, especially where heterogeneous alpha signals drive allocation decisions, high dimensionality imposes computational constraints (N3 vs N2 scaling), and robust risk control is vital.
Methodological Contributions
The paper introduces three key methods that systematically bridge the gap between signal-aware allocation and hierarchical/regularized robustness, building a spectrum from tree-based to flat iterative solvers:
- HRP-μ (Hierarchical Risk Parity with Signal):
- Maintains the HRP dendrogram structure but propagates a generic, signed-heterogeneous alpha signal μ.
- At each node, uses a sign-aware inverse-variance representative; cross-branch splitting leverages a 2×2 mean-variance system.
- Recovers HRP exactly for γ=0,μ=1, and is strictly O(N2) in cost.
- HRP-Σμ:
- Upgrades the within-cluster representative to the local mean-variance optimal portfolio (full within-cluster covariance), using recursive bottom-up solves.
- Between-branch normalisation is conducted by L1 normalization, ensuring sign preservation and eliminating sum-normalization-induced sign pathologies.
- Empirically, it dominates HRP-N30 across synthetic regimes, earning N31–N32 higher OOS Sharpe for random signals and up to N33 for structured signals, while remaining scalable (N34).
- CRISP (Correlation-Regularized Iterative Shrinkage Portfolio):
Perturbative and Bias-Variance Analyses
A central theoretical achievement is a closed-form approximation-error identity for the shrinkage trajectory N23:
N24
This yields:
- A rigorous bias–variance decomposition of OOS Sharpe loss, showing that shrinkage bias decreases with N25 while estimation error grows; the minimum therefore lies in the interior N26, not at the endpoints.
A closed-form adaptive rule for optimal shrinkage intensity is derived:
N27
with the practical implication that N28 increases with the sample size and signal strength (IC), and decreases with problem size and correlation conditioning.
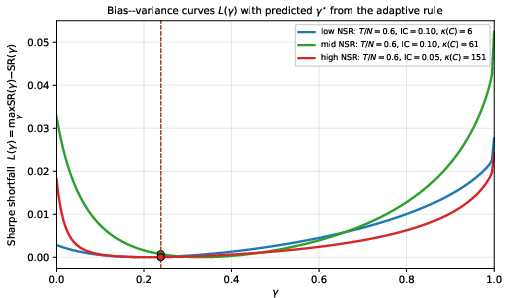
Figure 2: Bias–variance decomposition of direction error along the shrinkage parameter, numerically manifesting an interior N29 due to the trade-off between shrinkage bias and iterative convergence slack.
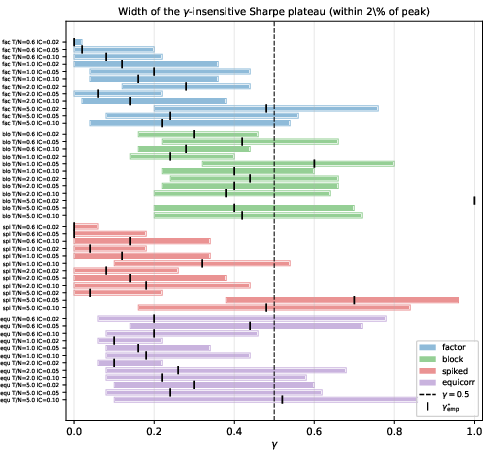
The OOS Sharpe surface is empirically observed to be nearly flat in μ0, with a dominant plateau containing μ1, providing robustness for practitioners.
Empirical Results and Strong Claims
Practical Implications
- For arbitrary signal-dependent allocation in high-dimensional portfolios, CRISP at μ6 (with μ7100 Gauss–Seidel sweeps) is recommended. It provides superior OOS Sharpe, numerical stability, and computational scalability, particularly valuable for factor-model–structured μ8 (via factor streaming implementation, reducing memory use from μ9 to 2×20).
- HRP-2×21 at 2×22 offers interpretable, hierarchical portfolios, nearly matching CRISP's statistical efficiency.
- Tree-based methods can accommodate tree-aligned constraints efficiently, but cross-tree constraints are best handled by projected CRISP.
- The effective difficulty of a portfolio problem should be gauged by 2×23, not 2×24 or determinant-based criteria.
Theoretical Implications and Open Research Directions
- Bias–variance trade-offs in allocation are precisely mapped to a one-parameter shrinkage trajectory, with rigorous perturbative, convergence-rate, and spectral analyses.
- The structural principle of variance-preserving shrinkage (shrinking only off-diagonal correlations) is shown to be operationally more effective than shrinkage-to-identity targets (as in classical Ledoit–Wolf).
- Early stopping in the iterative solver functions as implicit spectral filtering, orthogonally regularizing the portfolio by excluding noise–dominated eigenspaces.
- The Bayesian correspondence between CRISP/MVO shrinkage and prior-posterior inference is hypothesized, suggesting further development in the context of Black–Litterman generalizations.
Representative Numerical Results
- In synthetic Monte Carlo across multiple covariance regimes, at sample size ratios 2×25, CRISP at 2×26 consistently achieves 80–94% of the out-of-sample Sharpe of the oracle portfolio.
- HRP-2×27 delivers 2×28–2×29 higher Sharpe than HRP-γ=0,μ=10 on random signals and up to γ=0,μ=11 higher in structurally-aligned signals under sample estimation.
- Across all settings tested, the author recommends a default shrinkage parameter γ=0,μ=12, justified both theoretically and empirically.
Conclusion
This study establishes a rigorous methodology for signal-aware, hierarchical, and regularized portfolio construction on general mean-variance problems. By systematically generalizing the HRP and Cotton frameworks to arbitrary signals, and by introducing the CRISP iterative shrinkage architecture, it provides methods that are simultaneously statistically robust, computationally efficient (γ=0,μ=13 per iteration), interpretable, and scalable. The convergence and bias–variance characteristics are analytically characterized, with empirical evidence strongly supporting their practical superiority. The work also clarifies the conditions under which regularization, hierarchical structuring, and iterative solution methods are effective, establishing guidance for both researchers and practitioners in high-dimensional portfolio optimization.
Future Directions and Open Problems
Several non-trivial problems are open for future research:
- Characterization of the worst-case signal γ=0,μ=14 maximizing the direction error under shrinkage.
- Precise analytic correspondence between Sharpe-optimal CRISP shrinkage and Ledoit–Wolf shrinkage intensity.
- Bayesian interpretation and extension of CRISP, potentially in Black–Litterman style frameworks.
- Further analysis of tree dependence on the HRP-γ=0,μ=15 approximation gap and its interaction with different linkage/partitioning algorithms.
- Extension to dynamic, multi-period, or transaction-cost–aware regimes.
References
- See (2604.23833) for an exhaustive bibliography, open-source code, and appendices with additional numerical experiments.