- The paper introduces T2, a successor theorem-driven testing framework and Testing Accuracy (TA) metric to evaluate semantic correctness in automated theorem proving systems.
- It demonstrates that conventional compilation metrics yield high false positives, with models showing up to 80.3% compilation accuracy but only as low as 38.9% TA in rigorous testing.
- The study highlights the need for dependency-aware training and enhanced context integration to bridge the gap between syntactic fluency and true semantic correctness.
Benchmarking Semantic Correctness in Automated Theorem Proving: The T2 Framework and Testing Accuracy Metric
Introduction
The application of LLMs to Automated Theorem Proving (ATP) has advanced rapidly, yielding the ability to generate formally verifiable proofs in proof assistants such as Lean. However, prevailing evaluation methodologies largely measure syntactic and logical correctness, commonly reducing to whether generated statements compile in isolation. Such compilation-based metrics are insufficiently stringent: they fail to assess whether the generated theorem semantically realizes the intended mathematical proposition. The paper "Benchmarking Testing in Automated Theorem Proving" (2604.23698) addresses this critical shortcoming, proposing a successor-theorem-driven testing framework called T2 and introducing Testing Accuracy (TA)—a rigorously automatic, semantic correctness metric for theorem generation.
Compilation-Based Evaluation vs. Semantic Correctness
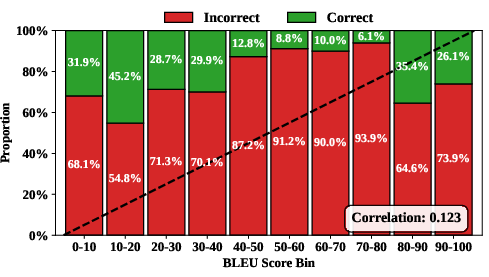
Existing formal theorem proving benchmarks either depend on code compilation or rely on proxy metrics, such as surface-level lexical similarity (e.g., BLEU), entailment checks, or costly human inspection. The consensus has been that these approaches cannot guarantee that a generated theorem faithfully expresses the desired mathematics. The compilation metric, by construction, only ensures logical and type-correct statements within the formal system, leading to numerous false positives—where semantically incorrect responses still pass.
A paradigmatic example is illustrated below. Here, both a commutativity theorem and its tautological incorrect variant are accepted by compilation, yet their distinction is critical for downstream correctness.
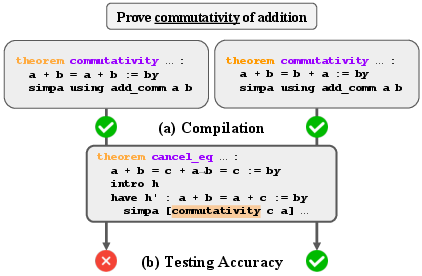
Figure 1: Compilation alone cannot distinguish between a semantically correct commutativity theorem and a trivial tautology when tested in isolation; only integration testing with successor theorems exposes the tautology as incorrect.
The T2 Benchmark: Integration Testing and Semantic Verification
Motivated by integration testing in software engineering and the Curry-Howard correspondence linking proofs and programs, T2 operationalizes semantic evaluation by exploiting the dependency structure inherent in real-world mathematical developments. In T2, each generated theorem is subjected to all of its successor theorems—those that depend upon it, transitively within the proof repository. TA (Testing Accuracy) is defined as the fraction of dependency chains in which the replacement of the ground-truth theorem with the model's output does not break any successors.
This approach is instantiated over a large, automatically extracted Lean 4 benchmark (2,206 problems; ~41 successors each), providing rich, realistic semantic constraints. This structure enables T2 to distinguish between logically correct but semantically irrelevant outputs and genuinely correct theorem generations.
Evaluation of 18 open and closed-source LLMs on T2 reveals substantial divergence between compilation-based and semantically-aware metrics:
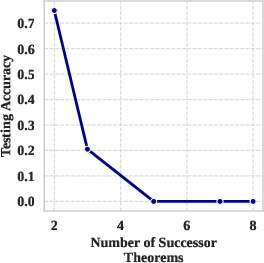
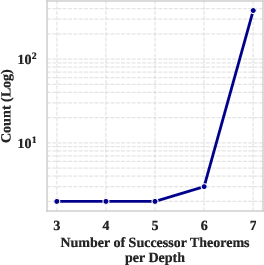
Figure 3: (a) Distribution of successor theorem depth in the T2 Hard set; (b) Testing Accuracy sharply decreases as the number of successor constraints increases, indicating evaluation stringency.
- Successor Theorem Context Matters: Supplying both the successor theorem and the NL proof context achieves the strongest TA scores, indicating the practical utility of dependency information in guiding LLM formalization.
Numerically, top-performing models such as Claude-Sonnet-4.5 obtain only 38.9% TA on the full test set, despite 80.3% compilation accuracy, and only 4.5% TA on the most challenging subset (T2 Hard). This 2× to 50× drop demonstrates the fundamental overestimation embedded in conventional evaluation practices.
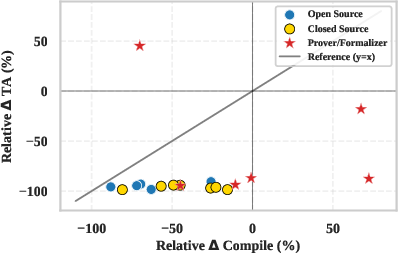
Figure 4: Compilation gains (x-axis) for specialized formalization models do not translate to gains in Testing Accuracy (y-axis), underscoring the gap between syntactic fluency and semantic correctness.
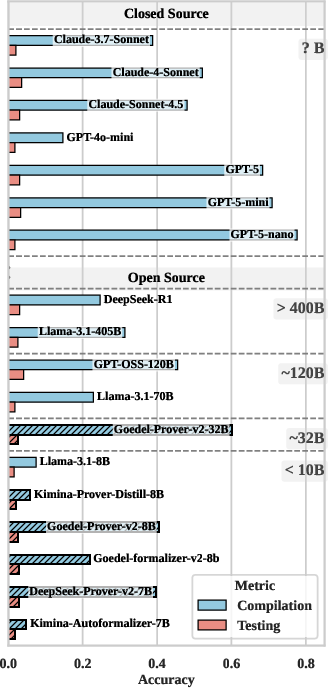
Figure 5: Compilation and testing accuracy for a range of LLMs on T2 Hard, stratified by open/closed source and parameter scale. Fine-tuned and larger models improve compilation, but semantic correctness remains uniformly low.
Theoretical and Practical Implications
Theoretical
T2 promotes a formal view of semantic evaluation as observational equivalence in context, rather than mere syntactic validation. This aligns with foundational results in proof theory (e.g., Cut Elimination), operationalizing correctness through compositional behavior within the global mathematical system. The approach shifts the burden from unattainable full logical equivalence tests to comprehensive contextual behavioral testing, a move supported by deep analogies with software test coverage.
Practical
Tools and benchmarks rooted in T2 and TA provide greater alignment with real-world mathematical workflows, where theorems exist as interconnected nodes rather than isolated solutions. The framework is fully automatic and scalable, requiring no ground-truth reference proofs or annotation. Implementing better evaluation and trust metrics will be essential as LLMs are integrated into research mathematics, education, and formal verification pipelines.
Importantly, the severe semantic gap uncovered indicates that simply scaling models or further fine-tuning on domain-specific corpora is insufficient. Advances in LLM architectures, enhanced context integration, and dependency-aware training paradigms appear necessary to close this gap.
Limitations and Future Directions
The strictness of TA is contingent upon the depth and breadth of successor theorem coverage; standalone theorems or those with few dependents cannot benefit from this method. As with software testing, coverage cannot confer guarantees of completeness in error detection. The present implementation is restricted to Lean 4 but is designed to be extensible to other formal proof assistants with suitable dependency-tracking infrastructure.
Future work includes development of graded TA metrics (partial credit for subsets of satisfied dependencies), expansion to non-Lean proof systems, enrichment of repository coverage, and more robust natural language to formal statement mapping validated by domain experts.
Conclusion
T2 and the Testing Accuracy metric represent a substantive step forward in rigorously evaluating ATP systems for mathematical correctness, revealing a critical and persistent semantic gap in contemporary LLMs. The results underscore the inadequacy of syntactic and lexical evaluation metrics and the necessity of dependency-structured integration testing for meaningful progress. As theorem-proving models move towards deployment in serious mathematical and verification applications, adopting frameworks such as T2 will be essential for safe and trustworthy AI-assisted formalization.