- The paper introduces a geometry-conditioned latent diffusion framework that synthesizes blanket occlusions directly from skeletal keypoints.
- It employs cross-attention for pose embedding fusion, achieving a high joint localization accuracy ([email protected] = 0.93) without requiring paired supervision.
- The approach minimizes annotation effort and enhances privacy by decoupling occlusion synthesis from appearance-level inputs.
Geometry-Conditioned Diffusion for Occlusion-Robust In-Bed Pose Estimation
Introduction and Problem Scope
Human pose estimation under blanket occlusion is a critical challenge in non-invasive patient monitoring applications, especially for sleep analysis and fall prevention. RGB-based estimators, while highly effective under non-occluded conditions, lose efficacy under occlusion due to the absence of visible joints and reliable annotations for covered keypoints. The structural data scarcity, particularly for occluded samples, impedes supervised advancements.
Prior approaches fall into two categories: (1) multi-modal sensing—incorporating depth, pressure, or thermal imagery, which increases hardware and operation complexity; and (2) generative models—such as unpaired and paired image-to-image translation, which synthesize blanket-covered images but remain constrained by their reliance on visible source imagery. This fundamentally limits pose diversity and scalability.
The paper "Geometry-Conditioned Diffusion for Occlusion-Robust In-Bed Pose Estimation" (2604.23651) addresses the data and annotation bottlenecks by reformulating augmentation as a geometry-conditioned generative modeling problem. The core task becomes the direct synthesis of realistic blanket occlusions from skeletal keypoints, bypassing the need for pixel-level input, aligned supervision, or appearance-conditioned generation.
Methodological Framework
The research presents a systematic comparison of four augmentation paradigms:
- Heuristic Deterministic Masking: Uses keypoint-guided padding and Gaussian smoothing to create simplistic occlusion masks covering lower-body regions, simulating blankets via color blending and local shadowing.

Figure 1: Heuristic augmentation employs keypoint-defined padded masks, Gaussian smoothing, and local intensity attenuation to mimic blanket occlusion.
- Unpaired Image Translation (CycleGAN): Leverages unpaired uncovered/covered domain mapping via adversarial learning and cycle-consistency loss, maintaining structural alignment without direct supervision.
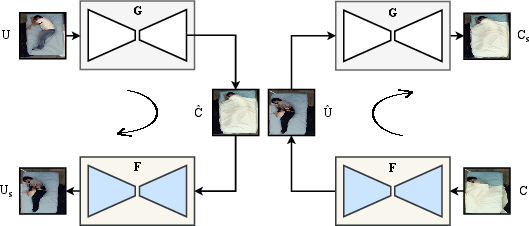
Figure 2: Unpaired CycleGAN translation with dual generators enforcing cycle-consistency, transforming uncovered to covered domains and vice versa.
- Paired Translation (Brownian Bridge Diffusion Model, BBDM): Utilizes paired uncovered and covered images to define a Brownian bridge in latent space, guiding a diffusion process between source and target image representations.
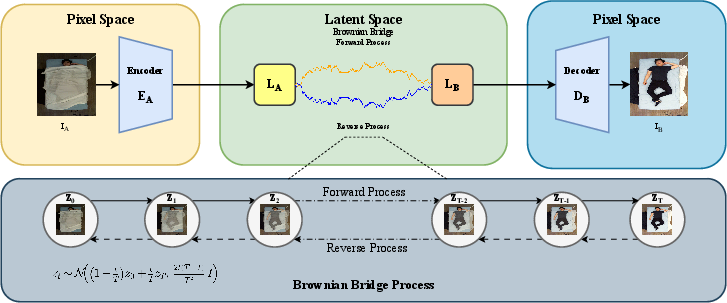
Figure 3: Paired BBDM leverages latent interpolations between uncovered and covered images, driven by Brownian bridge stochasticity.
- Pose-Conditioned Latent Diffusion Model (Pose-LDM): The proposed formulation conditions solely on raw skeletal coordinates, eschewing source imagery. It synthesizes covered images in latent space via a U-Net-based denoiser, conditioned on pose embeddings injected through spatial concatenation or cross-attention mechanisms.
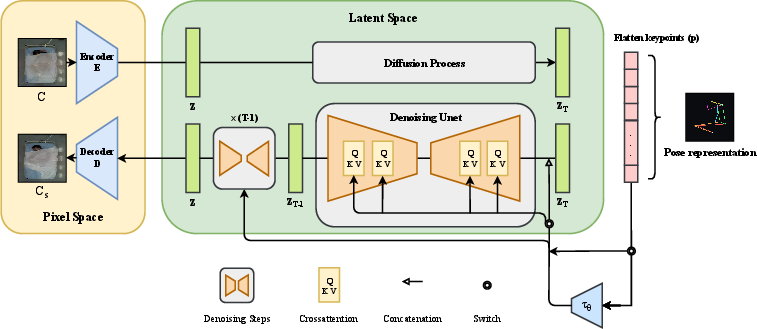
Figure 4: Pose-LDM maps skeletal keypoints to pose embeddings for latent-space diffusion, entirely decoupling synthesis from source images.
Pose-LDM diverges from classical image-to-image models by enabling sample generation for arbitrary or unseen poses, overcoming pose bias inherent in dataset-limited translation methods. The diffusion process, performed in a compressed latent representation, yields computational efficiency and high-fidelity outputs.
Experimental Setup and Results
Experiments are conducted on the SLP dataset, a large-scale benchmark for in-bed pose estimation under diverse occlusion conditions. A fixed backbone YOLOv11-Medium keypoint detector is used to isolate augmentation-induced improvement, and performance is evaluated via PCK@0.1 and AP50−95.
Main Findings
- Pose-LDM attains the highest strict joint localization accuracy under severe occlusion ([email protected] = 0.93) among all augmentation baselines, closely approximating the performance of a fully supervised (oracle) model trained on real covered samples.
- Its overall detection performance (AP50−95 = 0.75) is competitive with paired BBDM (AP50−95 = 0.76), despite not requiring any paired uncovered-covered images, visible source conditioning, or supervision beyond pose.
- Heuristic masking and CycleGAN suffer reductions in geometric fidelity and detection robustness, with significant lags in both PCK and AP metrics.
- The conditioning design in Pose-LDM plays a critical role: cross-attention based fusion of pose embeddings with the diffusion backbone yields measurable gains over spatial concatenation, as affirmed by a comprehensive ablation study.
Ablation Study
The study demonstrates:
- Cross-attention mechanisms outperform spatial concatenation for injecting pose information into the diffusion model, enhancing both localization and detection metrics.
- The use of raw 2D joint coordinates as conditioning inputs suffices; explicit occlusion priors or visibility flags (e.g., joint-wise binary occlusion indicators) provide marginal benefit or potential degradation, particularly in cross-attention settings.
Qualitative Comparison
Diffusion-based augmentations (Pose-LDM, BBDM) yield more anatomically plausible and stable pose predictions than heuristic or unpaired GAN-based methods, with Pose-LDM demonstrating superior preservation of structure under high occlusion regimes, even in the absence of paired supervision.

Figure 5: Qualitative pose estimation results show increased anatomical consistency and stability using diffusion-based augmentation, especially in severe blanket occlusion scenarios.


Figure 6: Samples generated with Pose-LDM under different conditioning variants and bedsheet types, reflecting flexible, structure-preserving synthesis.
Theoretical and Practical Implications
The implications of geometry-conditioned diffusion are manifold:
- Annotation Efficiency: Direct synthesis from pose geometry obviates manual annotation of covered samples, which is both laborious and error-prone due to occlusion ambiguity.
- Source-Free and Privacy-Respecting Generation: As synthesis is decoupled from appearance-level conditioning, the framework mitigates privacy concerns, crucial in sensitive patient monitoring and healthcare deployments.
- Pose Space Expansion: Arbitrary pose conditioning supports the generation of unseen body configurations, prioritizing diversity and model generalization beyond the limits of collected datasets.
- Modularity and Transferability: The approach can be decoupled from sensing modality (provided pose information is available) and integrated into pipelines requiring occlusion-robust supervision, including gesture recognition, surveillance, and robotics.
Future Research Perspectives
Promising directions include:
- Incorporation of more expressive pose representations, such as 3D keypoints or parametric body models, to enable high-fidelity, volumetric occlusion synthesis.
- Extending geometry-conditioned diffusion to multi-modal inputs, leveraging the intrinsic structure of non-RGB data (e.g., pressure, thermal) to further enhance occlusion robustness.
- Adapting the framework to other application domains where occlusion impedes supervision, such as multi-person pose estimation in dense crowd scenarios or sports analytics with frequent self-occlusion.
Conclusion
Geometry-conditioned latent diffusion is empirically validated as an effective and efficient augmentation paradigm for occlusion-robust in-bed pose estimation. Synthesis from raw keypoints enables high joint localization accuracy and competitive detection scores without paired or pixel-level supervision. The work establishes the primacy of pose-based conditioning, dynamic fusion via cross-attention, and the sufficiency of geometry-only input in guiding occlusion synthesis. This decouples the generation pipeline from both annotation bottlenecks and appearance-specific artifacts, paving pragmatic avenues for synthetic data scaling, model generalization, and privacy-preserving learning in human pose estimation tasks.