- The paper introduces a novel hybrid framework that synergistically integrates CNN and transformer architectures to enhance joint spatial-spectral feature extraction in HSI classification.
- It employs specialized modules—twin-branch feature extraction, hybrid pooling attention, and cross-layer feature fusion—to achieve state-of-the-art accuracy on multiple benchmark datasets.
- Empirical results show significant improvements in overall accuracy and robustness over traditional CNN and transformer models, setting a new standard in remote sensing.
Introduction
The paper "A Synergistic CNN-Transformer Network with Pooling Attention Fusion for Hyperspectral Image Classification" (2604.23622) introduces a hybrid deep learning framework integrating convolutional neural networks (CNNs) and vision transformers (ViTs), targeting efficient and robust classification of hyperspectral imagery (HSI). The method explicitly addresses two core obstacles in HSI classification: effective joint spatial-spectral feature integration and mitigation of information loss across network layers. The architecture is composed of three essential modules: Twin-Branch Feature Extraction (TBFE), Hybrid Pooling Attention (HPA), and Cross-layer Feature Fusion (CFF), each playing a distinct role in enhancing representation fidelity and classification accuracy.
Architectural Overview
The network processes HSI data through a pipeline of sequential modules—initially leveraging dimensionality reduction via principal component analysis (PCA), followed by spatial-spectral feature extraction using TBFE, spatial context aggregation through HPA, and global modeling with a stack of transformer encoders, finalized by the CFF for efficient layer-wise information propagation.
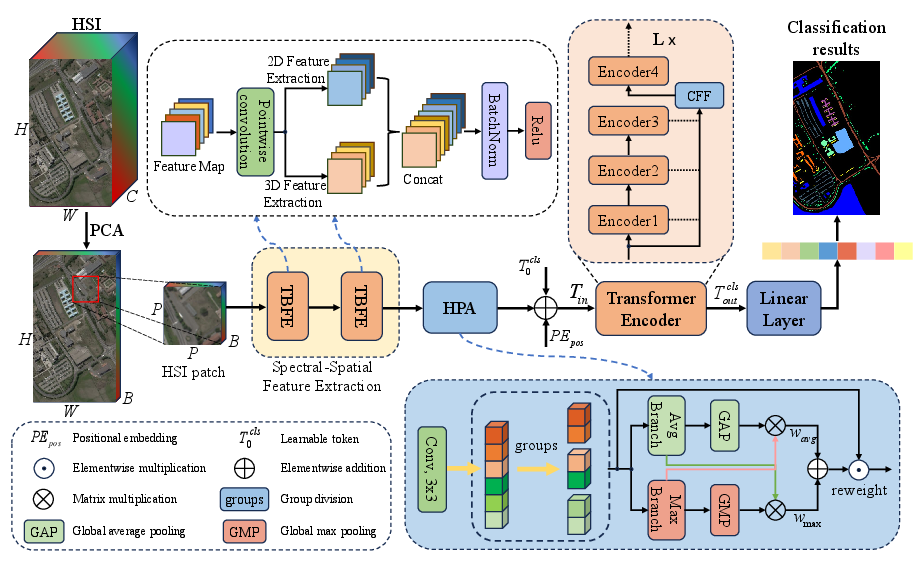
Figure 1: Overview of the synergistic CNN-Transformer network, highlighting the interplay between TBFE, HPA, and CFF modules.
TBFE operates by parallelizing 2D and 3D convolutional paths. The 3D path is specialized for extracting rich spectral features by utilizing depthwise convolutions over the band dimension, while the 2D path emphasizes local spatial patterns. The outputs are concatenated, promoting integration of joint spatial-spectral representations. Initial pointwise convolutions adjust the channel dimensionality, enhancing efficiency and compatibility between subsequent modules.
Hybrid Pooling Attention (HPA)
HPA modulates feature maps at the spatial level via group-wise partitioning and combines average and max pooling across both spatial dimensions. This multi-path pooling channel recalibrates feature attention maps, integrating both global context and fine-grained local information without dimensionality reduction. Parallel pooling operations encode spatial dependencies, and a combination of GroupNorm and Softmax ensures adaptive, scale-aware recalibration.
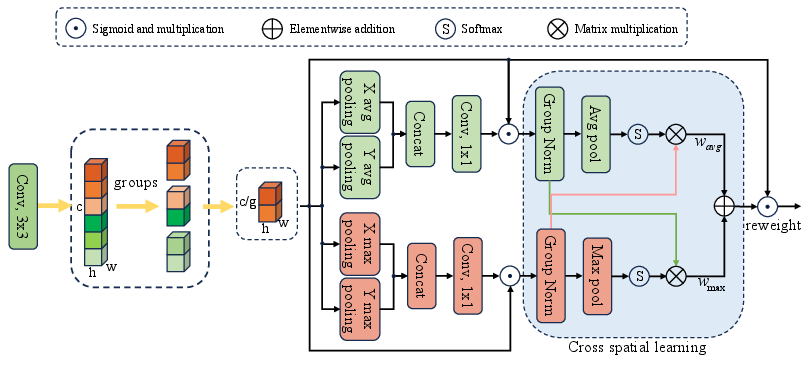
Figure 2: Schematic of the hybrid pooling attention module, illustrating dual-path, group-based pooling operations.
Subsequent to HPA, transformer encoders receive tokenized feature sequences. Positional embeddings preserve spatial correspondence, and multi-head self-attention layers capture long-range dependencies across spatial and spectral axes. The sequence is processed through a multi-layer perceptron (MLP) and normalization layers, optimizing the mapping from encoded representations to classification logits.
Cross-Layer Feature Fusion (CFF)
CFF implements skip connections by concatenating intermediate encoder outputs with current representations, followed by adaptive fusion via learnable parameters. This procedure reduces representational bottlenecks and enhances gradient flow, manifestly improving network stability and information retention.
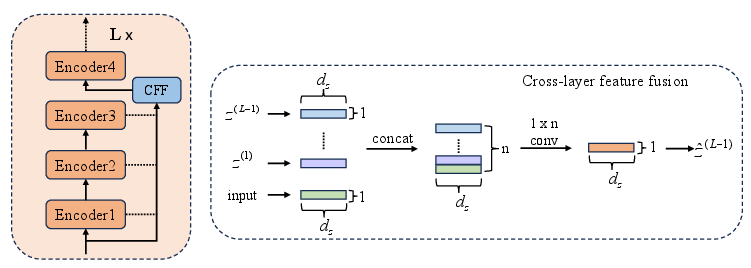
Figure 3: Cross-layer feature fusion module, fusing multi-stage features for robust representation.
Experimental Protocol and Results
The model is evaluated on five benchmark HSI datasets: Salinas, Pavia University, Houston2013, WHU-Hi-HanChuan, and Houston2018. Datasets are partitioned following standard protocols, maintaining category balance and controlling for data complexity (number of classes and spectral dimension).
Hyperparameters are extensively analyzed, including retained spectral bands, patch sizes, learning rates, attention heads, and encoder depth. Optimization leverages Adam with a learning rate of 1e-3, and empirical results dictate three or four transformer encoders as optimal, contingent on dataset size.
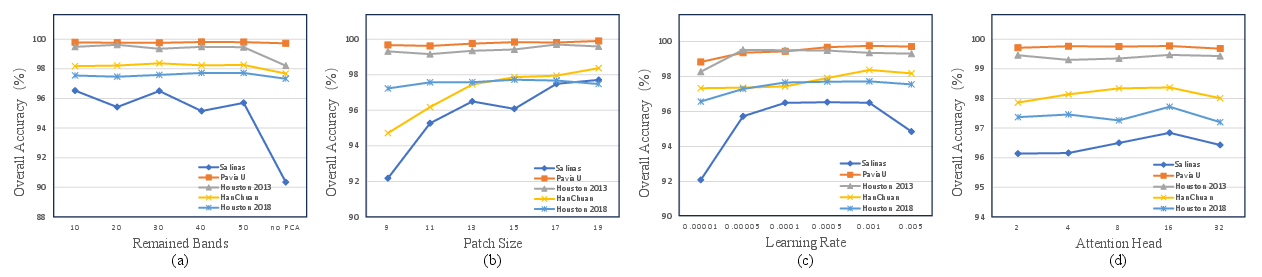
Figure 4: OA impact curves illustrating sensitivity to reduced bands, patch size, learning rate, and attention head count.
The method consistently outperforms SVM, vanilla CNN/3D-CNN, HybridSN, and state-of-the-art transformer and SS-Mamba-based models.
- Salinas: OA = 98.67%, AA = 98.64%, Kappa = 98.52. Gains over MASSFormer and SS-Mamba in both OA and Kappa.
- Pavia University: OA = 99.92%, AA = 99.88%, Kappa = 99.89. Four classes achieve 100% class-wise accuracy.
- Houston2013: OA = 99.65%, AA = 99.52%, Kappa = 99.62. Outperforms in highly imbalanced settings.
- WHU-Hi-HanChuan: OA = 98.37%, AA = 96.15%, Kappa = 98.09; robust in high-class cardinality scenarios.
- Houston2018: OA = 97.72%, AA = 95.04%, Kappa = 96.99; significant ~30% OA advantage over SS-Mamba.
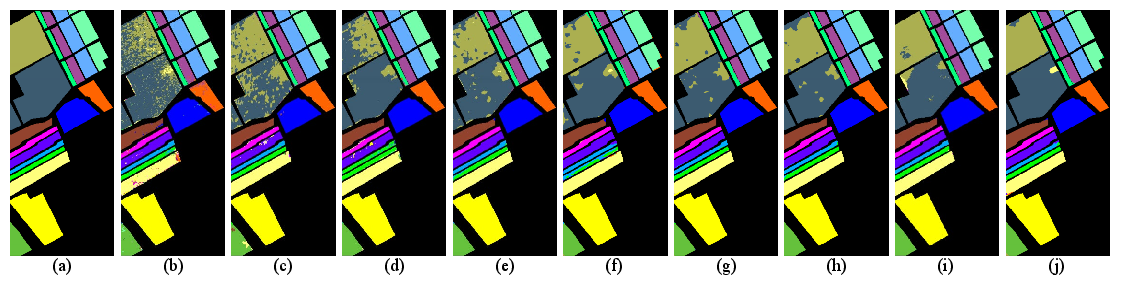
Figure 5: Salinas dataset classification maps: ground truth, baseline models, and Ours, demonstrating error suppression and smooth class boundaries.
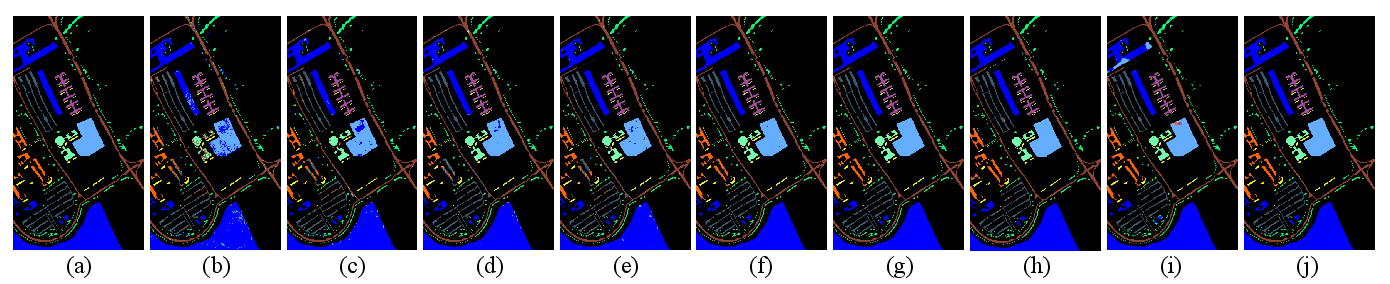
Figure 6: Pavia University classification visualizations; Ours result shows minimized fragmentation and high spatial consistency.

Figure 7: Houston2013 classification visualizations; Ours maintains superior homogeneity and complex region accuracy.
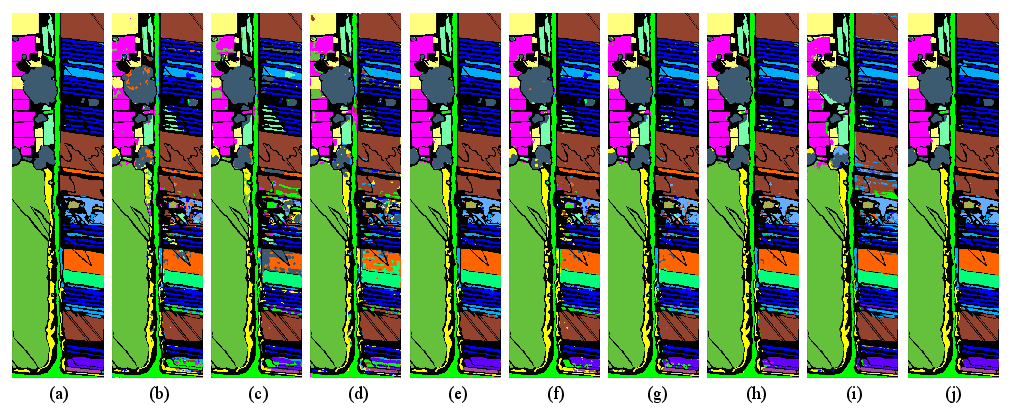
Figure 8: WHU-Hi-HanChuan visualizations; Ours captures intra-class variability, particularly in tree regions.
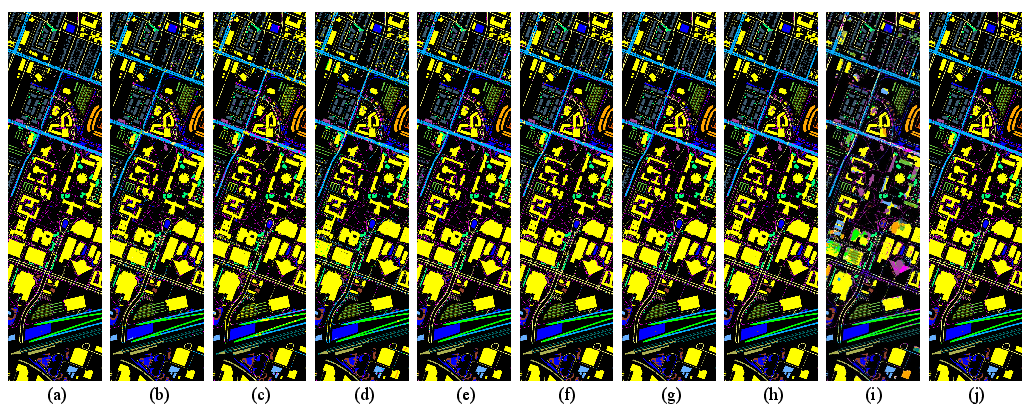
Figure 9: Houston2018 classification; Ours achieves high-fidelity correspondence even in dense urban structure.
Ablation and Efficiency Studies
Ablation experiments on Salinas delineate contributions of TBFE, HPA, and CFF. Each module produces incremental OA improvements (up to +2.66%). CFF demonstrates orthogonality and complementarity with HPA, as evidenced by the additive performance when modules are combined.
Testing time and parameter count reveal that the proposed network achieves superior accuracy with moderate computational overhead (parameter count substantially lower than hybrid transformer models, and inference time slightly above lightweight CNNs).
Theoretical and Practical Implications
This work empirically validates that fine-grained spatial-spectral feature extraction (TBFE), spatial attention reweighting (HPA), and structured cross-layer fusion (CFF) in a hybrid CNN-Transformer pipeline are synergistic for HSI. The results indicate that direct concatenation or naive skip connections in previous architectures are suboptimal, and the designed modules each fulfill non-redundant representational and regularization roles. This architectural template can be readily extended to other multi-dimensional, high-sample-complexity tasks in remote sensing, bioinformatics, and medical imaging.
Furthermore, the model’s modularity (plug-and-play TBFE/HPA/CFF) allows for straightforward adaptation for multimodal fusion (e.g., LiDAR + HSI) and may inspire future work on jointly-learned attention or shared representations across tasks such as semantic segmentation or object detection in remote scenes. The principled reduction of information loss via CFF in deep transformer stacks is directly relevant for large-scale sequential modeling, offering insights relevant for both spatial vision and sequence learning domains.
Conclusion
The synergistic CNN-Transformer network with pooling attention fusion provides strong evidence for the efficacy of spatial-spectral hybridization in HSI classification. Through architectural innovations in multi-branch convolutions, hybrid attention, and adaptive cross-layer fusion, the model attains state-of-the-art accuracy and efficiency. These results contribute a robust blueprint for future research in remote sensing and set a new performance standard for HSI classification frameworks.

