- The paper introduces the BUA framework that aligns behavior event sequences with large language models using a three-stage curriculum, enhancing prediction and generation accuracy.
- The approach achieves a 25.8% average improvement in prediction and a BLEU score of 0.354, outperforming state-of-the-art models on both common and long-tail events.
- The framework offers enhanced interpretability and transferability of user representations, benefiting applications such as personalization, rare-event detection, and regulatory-compliant AI systems.
Behavior Understanding Alignment with LLMs: A New Paradigm for Human Behavior Modeling
Motivation and Challenges
Modeling human daily behaviors as event sequences is foundational for numerous AI applications—personalized assistants, recommender systems, and context-aware services. Mainstream deep learning-based models have advanced this area, particularly via pretraining and transformer architectures, yet persistent obstacles remain: poor handling of long-tail behaviors, lack of interpretability, and rigidly single-task designs that separate prediction from generation. While LLMs have demonstrated remarkable semantic and generative capacities, direct application to structured behavioral data is impeded by modality mismatches—behavior logs and language are fundamentally different.
The work in "LLMs Reading the Rhythms of Daily Life: Aligned Understanding for Behavior Prediction and Generation" proposes the Behavior Understanding Alignment (BUA) framework to address these core challenges using a curriculum-driven alignment strategy (2604.23578). This method brings structure to LLM-based behavior modeling, enabling unified, interpretable, and high-performing behavior prediction and generation from real user event data.
BUA Framework and Curriculum Learning Design
The BUA framework is constructed with two principal innovations: explicit sequence embedding alignment and a three-stage curriculum that progressively advances behavioral semantic understanding within the LLM. Initially, behavior event sequences are embedded using a pretrained behavioral model (e.g., BehaveGPT), projected into a continuous latent space. This embedding is anchored and aligned with the input to a LLM via a lightweight MLP for cross-modal transformation.
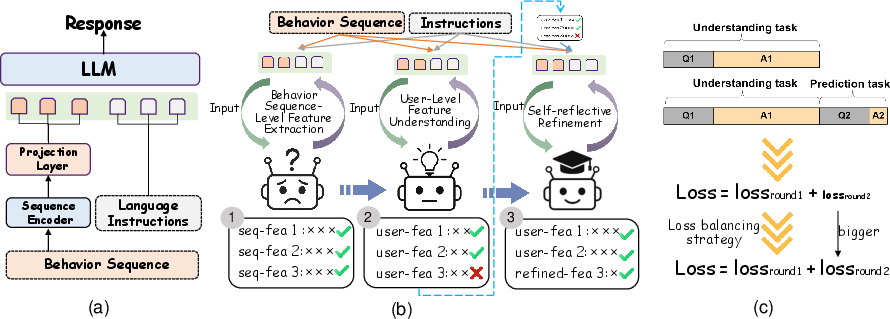
Figure 1: BUA framework overview including (a) modality conversion via sequence embedding, (b) three-stage curriculum (seq-fea, user-fea, refined-fea), and (c) multi-round dialogue for prediction and generation.
The staged curriculum comprises:
- Sequence-Level Understanding: The LLM reconstructs, summarizes, and predicts behavioral context using natural language, building fundamental event-level semantic grounding.
- User-Level Feature Modeling: The model proceeds to infer user-specific behavioral features, discover key behaviors, and abstract high-level patterns that underpin user intent.
- Self-Reflective Refinement: Through iterative review and feedback, the LLM enhances the coherence and abstraction of user profiles, learning to self-correct inaccuracies and generalizations.
A multi-round dialogue framework is introduced during user-level understanding and carries through prediction/generation; the LLM incrementally builds on its comprehension, culminating in precise prediction and robust sequenced behavior generation.
Methodology and Training Dynamics
The core methodological contribution is BUA’s staged, curriculum-based multimodal fusion between behavioral data and LLMs. The alignment is achieved not through item embeddings (which are shown to be insufficient), but through learned sequence-level embeddings that preserve dependence across spatial, temporal, and categorical behavioral axes.
The loss function is adjusted with a round-level balancing weight to address the divergent lengths and informativeness of outputs across understanding and prediction/generation tasks. This ensures prediction does not get underemphasized during joint dialogue-based training.
Ablation experiments confirm that each curriculum stage critically contributes to performance: removal of any stage or replacement of sequence embeddings with item embeddings leads to significant drops in both prediction and generation accuracy.
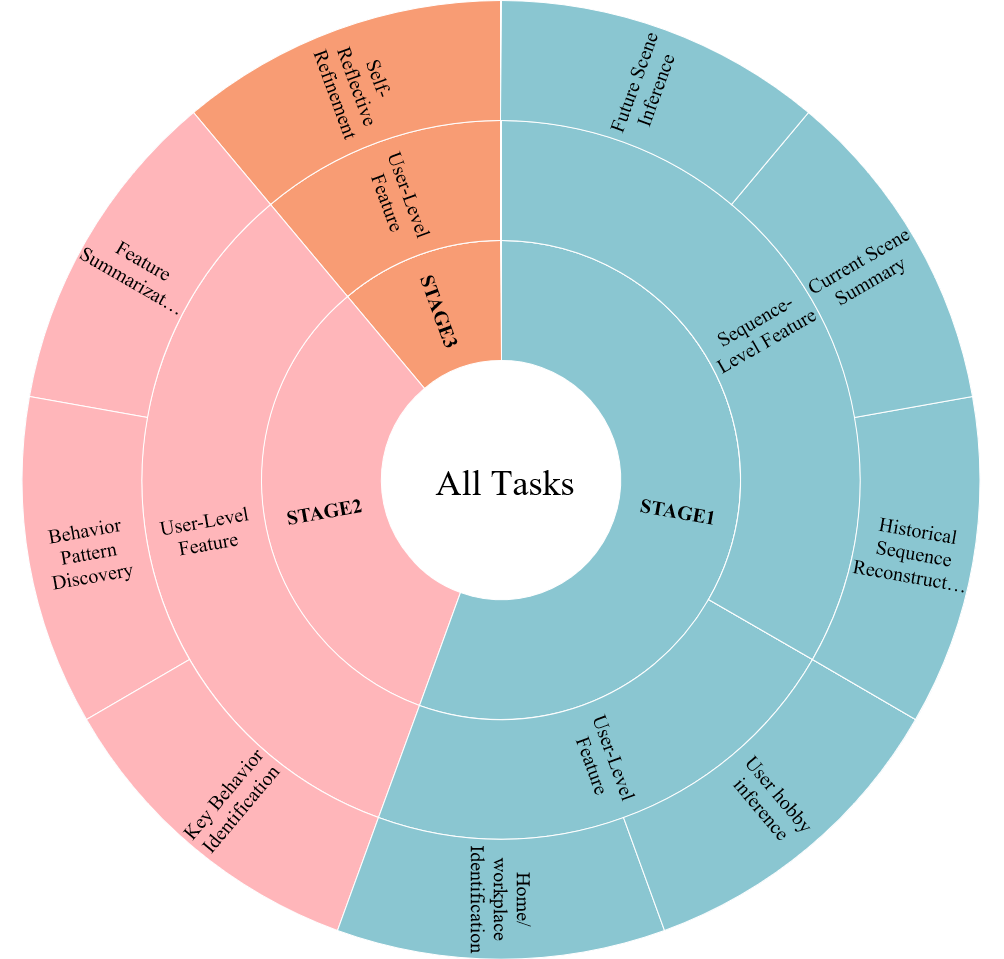
Figure 2: Comprehensive taxonomy of behavior understanding tasks utilized in BUA.
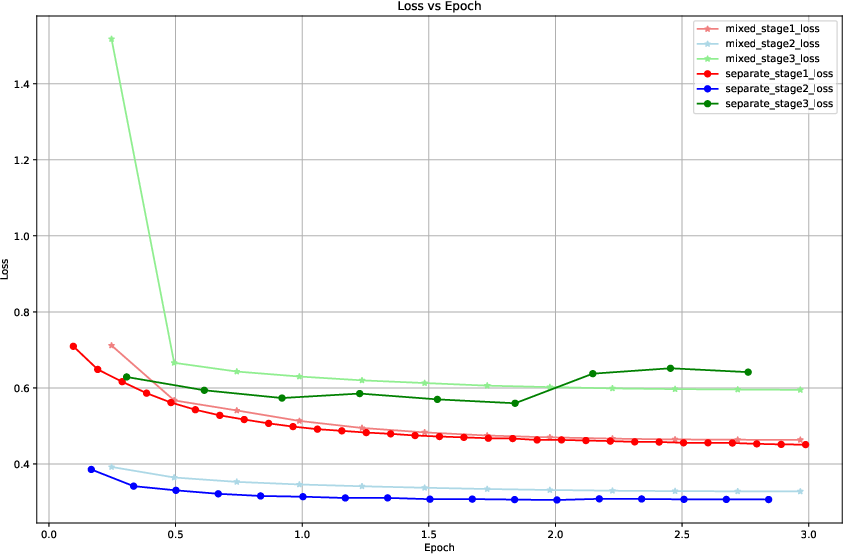
Figure 3: Validation loss comparison showing that the staged curriculum yields lower losses than joint training, especially on higher-order tasks.
Empirical Results and Key Numerical Findings
Extensive experiments were conducted on two real-world datasets: a large-scale mobile behavior log and the Tencent trajectory dataset. The evaluation spans weighted precision and recall, accuracy for head, medium, and long-tail categories, and generation metrics such as BLEU, TVD, and JSD.
- Prediction Task: BUA achieves a 25.8% average improvement over the best baseline across all behavioral frequency classes, including a 22.9% improvement for long-tail events. This outstrips state-of-the-art LLM-based and fusion models such as TALLRec, LLaRA, and CoLLM.
- Generation Task: BUA achieves BLEU of 0.354 (vs. D2A’s 0.315 and SAND's 0.142) and improves distributional matching (TVD/JSD) for event, timestamp, and location metrics.
- Cross-Model Transfer: User representations generated by BUA transferred to other LLM-based models consistently improved their prediction accuracy, with the largest gains observed on long-tail behavior prediction.
- Interpretability: Quantitative human evaluations show BUA’s output achieves interpretability and rationality scores nearly matching human-annotated profiles, well above base LLMs without alignment training.
These results are robust across both in-domain and out-of-domain/cross-cultural datasets, demonstrating strong generalizability. Efficiency is comparable to other LLM-based baselines, albeit with higher inference cost than traditional models.
Theoretical and Practical Implications
The BUA framework reframes LLMs as multimodal, sequence-aware cognitive agents capable of abstracting latent behavioral patterns. This approach not only bridges the modal gap between structured events and language reasoning, but also provides a foundation for interpretable models that can explain their predictions, a requisite for user-facing and regulatory-sensitive applications. The multimodal curriculum learning paradigm signals a broader trajectory for LLM-based sequence modeling—moving beyond language to hybrid understanding and reasoning across diverse data types.
A notable practical implication is BUA’s superior capacity to model long-tail events, a known Achilles' heel in real-world behavior modeling. This opens new possibilities for improved personalization, rare-event detection, and simulation of heterogeneous user populations in both commercial and scientific contexts.
Prospects for Future Research
Future research directions include addressing convergence rate discrepancies between prediction and generation tasks (e.g., through adaptive task weighting or optimizer separation), reducing dependency on pretrained behavior encoders (to mitigate domain transfer limitations), and further optimizing efficiency for on-device and large-scale deployments.
Additionally, advanced reflection mechanisms and further curriculum enhancements could enable even deeper abstraction, transferability, and cross-domain adaptation. The framework’s modularity suggests easy extensibility to other structured modalities, such as interaction graphs or sensor streams, with only minor adjustments in the curriculum design.
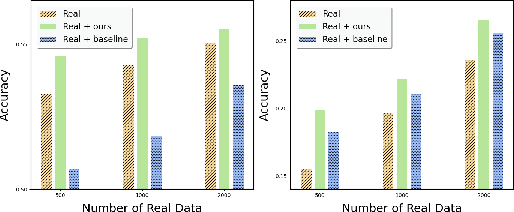
Figure 4: Augmenting real-world data with BUA-generated synthetic behavior sequences enhances downstream prediction task performance.
Conclusion
Behavior Understanding Alignment provides a rigorous and empirically validated pathway for integrating LLMs into human behavior modeling via sequence-level multimodal curriculum learning. This approach marks substantive progress toward unified, interpretable, and robust predictive/generative modeling of human behavior, with practical impact for both academic research and real-world AI systems.