- The paper introduces TEMPO, a transformer-based model that uses simulation-based supervised learning to infer both ordinal event sequences and continuous temporal spacing in disease progression.
- It demonstrates significant reductions in error metrics, including a 52.89% decrease in sequencing Tau distance and a 25.33% reduction in staging MAE relative to benchmark models.
- Also, TEMPO shows improved generalization across synthetic and real-world (ADNI) data, highlighting its scalability and practical utility in neurodegenerative research.
Introduction and Motivation
Event-Based Models (EBMs) have historically provided a foundational approach to inferring temporal biomarker progression in neurodegenerative disease using only cross-sectional data. While EBMs elucidate the ordinal sequence of pathological events, they do not directly estimate continuous temporal spacing between events and impose rigid disease logic constraints (e.g., irreversibility, unimodal trajectory, conditional independence). Recent advances (e.g., SA-EBM, sEBM, TEBM) address scalability and robustness, but all fundamentally rely on bespoke inference algorithms and typically require longitudinal anchors for continuous modeling.
TEMPO introduces a paradigm shift by treating disease progression estimation as a supervised learning problem via simulation-based data generation. The architecture leverages two Transformer modules: a biomarker self-attention module for event sequencing and a patient self-attention module for disease staging. Synthetic data is generated under diverse generative hypotheses with known ground truths, enabling TEMPO to learn robust progression logic across ordinal and continuous domains. This approach provides modeling flexibility, rapid empirical validation, and avoids manual derivations of custom inference algorithms.
TEMPO Architecture and Training Methodology
TEMPO utilizes a dual-branch Transformer architecture, where biomarkers and patients are each treated as distinct tokens. The model standardizes input data and incorporates diagnosis labels as auxiliary features.
Sequencing Branch: Biomarkers as Tokens
Biomarkers are encoded across cohorts, pooled, and passed through a multi-layer Transformer to model contextual dependencies and infer event cascade scores. These scores are sorted to yield the predicted progression sequence. Supervision is enforced using a hybrid loss combining direct timeline alignment (MSE to absolute event scores) and pairwise ranking (either Bradley-Terry binary classification for discrete events or regression for continuous event times).
Staging Branch: Patients as Tokens
Each patient's abnormality profile (probabilities indicating per-biomarker pathological state) is mapped to a latent space and processed with patient-level self-attention. The resulting representations yield continuous stage predictions. Loss is applied using normalized MSE to maintain comparability across varying dimensionalities.
Simulation-Based Supervised Learning
Synthetic datasets are generated to mimic real-world cohort characteristics with systematic variations in event times, stage distributions, measurement model (EBM binary-switch vs. Sigmoid progression), and biomarker distributions (normal, non-normal). TEMPO is trained on millions of synthetic patients under ground-truth labels derived from these diverse generative frameworks.
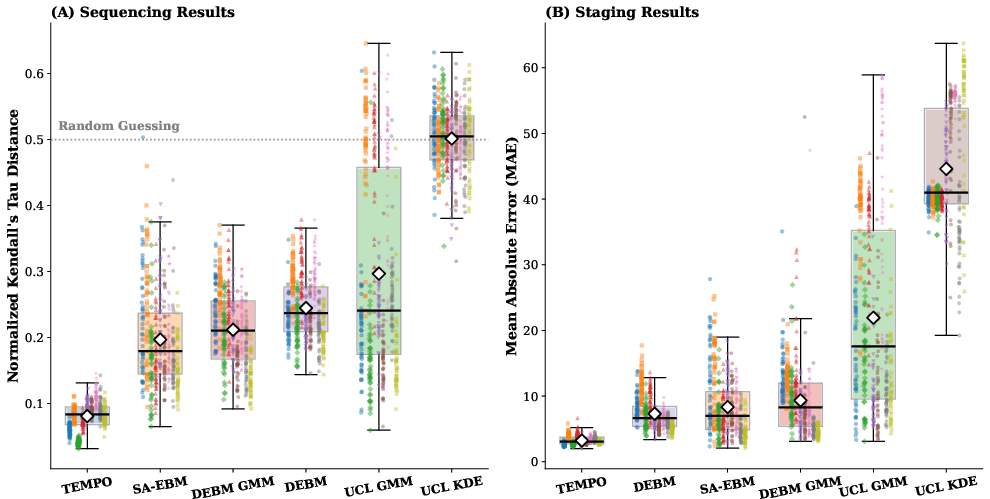
Figure 1: Performance summary in low-dimensional experiments: TEMPO demonstrates reduced Tau distance and MAE, with accuracy and stability surpassing all benchmarking EBMs across all generative conditions.
Synthetic Benchmarking and Numerical Findings
Low-Dimensional Experiments (B=12)
TEMPO achieves a 52.89% reduction in normalized Kendall's Tau distance and a 25.33% reduction in staging MAE relative to SA-EBM in low-dimensional settings. This advantage is consistent across all generative frameworks, including those involving non-normal biomarker distributions and measurement model misspecifications. Variance analysis reveals markedly improved stability and consistency in both sequencing and staging tasks.
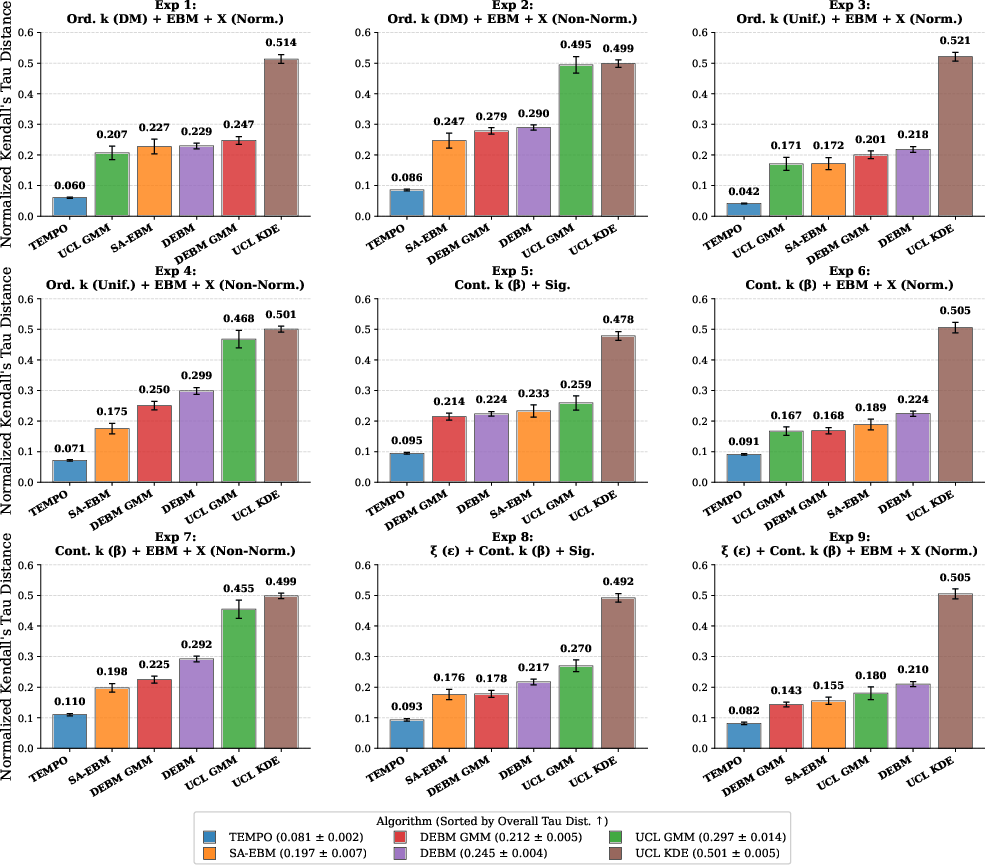
Figure 2: Detailed sequencing accuracy for all nine low-dimensional synthetic frameworks, showing the robustness of TEMPO under varying data misspecification scenarios.
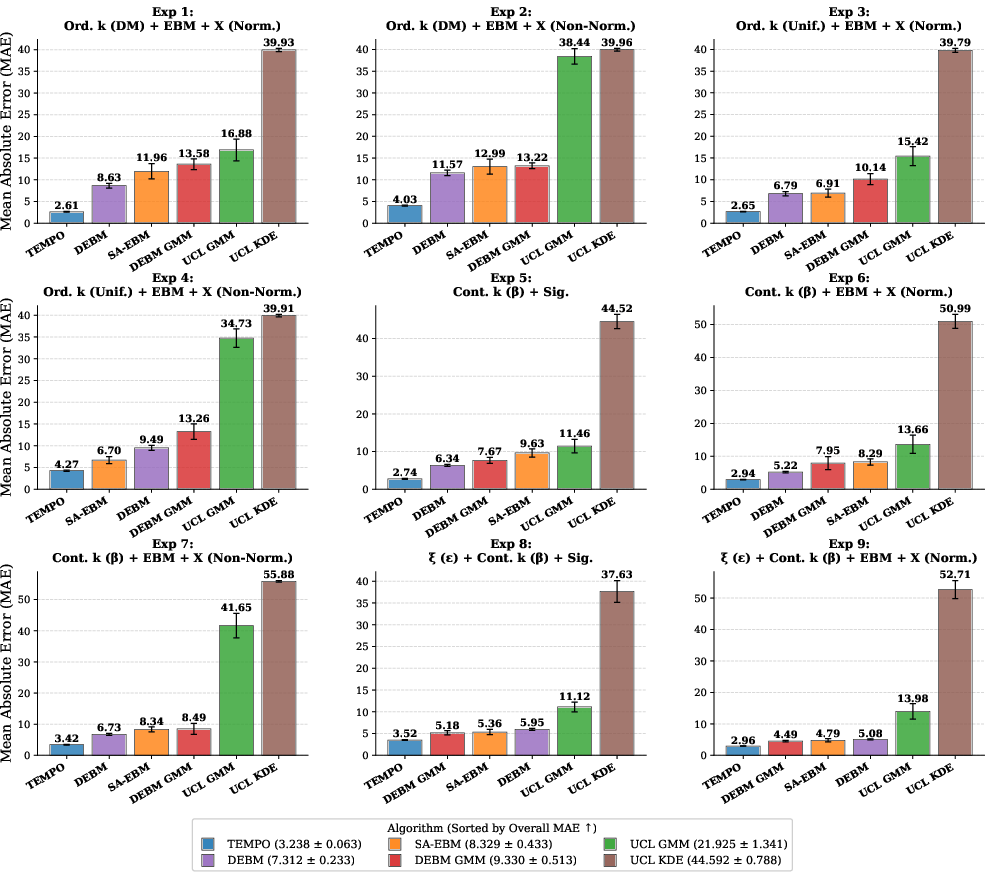
Figure 3: Staging MAE comparison—TEMPO maintains a favorable performance margin and low variability across diverse patient distributions and measurement logics.
Cross-Gene Generalization
Cross-experiment evaluation demonstrates that training on synthetic data with richer generative diversity (e.g., Sigmoid measurement model, non-normal distributions) markedly enhances generalization performance. The model trained on continuous event times and non-normal biomarker distributions generalizes best, confirming that expansive simulation improves robustness to unseen clinical reality.
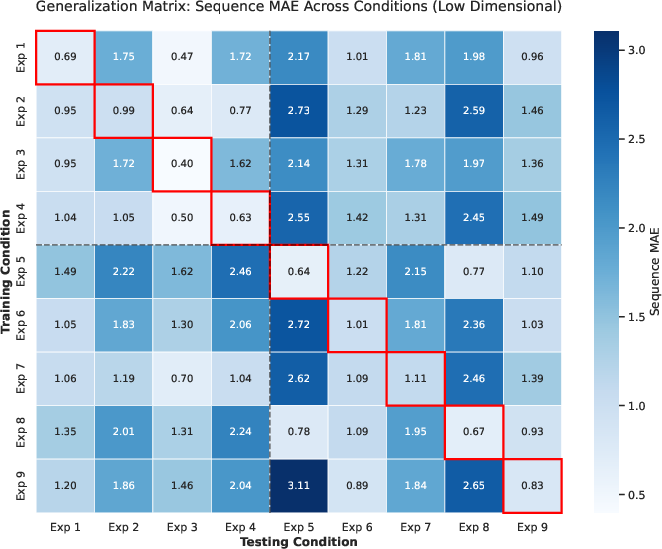
Figure 4: Sequence generalization heatmap across generative hypotheses—Sigmoid frameworks yield superior transferability and lower cross-condition error.
High-Dimensional Results (B=100)
In the high-dimensional setting, TEMPO's sequencing Tau distance and staging MAE are further reduced—58.88% and 61.10% relative to SA-EBM, respectively. Staging error, when normalized per biomarker, decreases from 5.7% in B=12 to 3.2% in B=100, illustrating that the patient-level attention benefits from high biomarker dimensionality, contrary to scaling limitations in classical EBM inference.
Figure 5: Comparison between TEMPO and SA-EBM for event sequencing and staging precision in high-dimensional biomarker space.
Figure 6: TEMPO's sequencing accuracy outperforms SA-EBM under all high-dimensional pathological frameworks, with statistically significant confidence intervals.
Figure 7: Patient staging MAE across all frameworks—TEMPO's error decreases substantially as biomarker dimensionality increases, emphasizing scalability advantages.
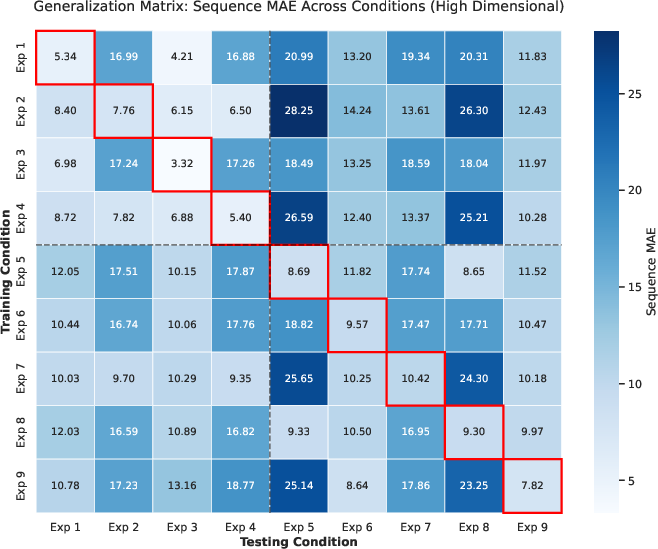
Figure 8: Cross-condition generalization in high-dimensional space—training on Sigmoid models with continuous event times leads to improved generalization.
Application to Real-World Cohorts: ADNI
TEMPO was applied to the ADNI dataset to recover the empirical sequence of Alzheimer's disease biomarker progression. The consensus ordering produced by nine trained models recapitulates a trajectory of early medial temporal atrophy, followed by cognitive decline and amyloid accumulation, progressing to late-stage tau pathology and global neurodegeneration—a pattern broadly consistent with revised "neurodegeneration-first" biomarker models.
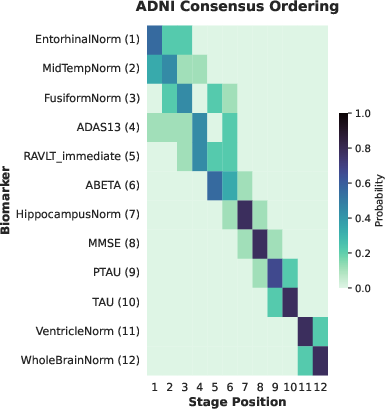
Figure 9: Positional variance diagram of ADNI biomarker progression—cell probabilities reflect ordering frequency across multiple generative assumptions.
Continuous Temporal Spacing
TEMPO estimates not only the event order but also continuous temporal separation between biomarker transitions, revealing distinct clusters (structural onset, preclinical gap, cognitive-amyloid phase, terminal acceleration). This provides granular insights unavailable through traditional EBM approaches, and aligns closely with the latest imaging and neuropathological findings.
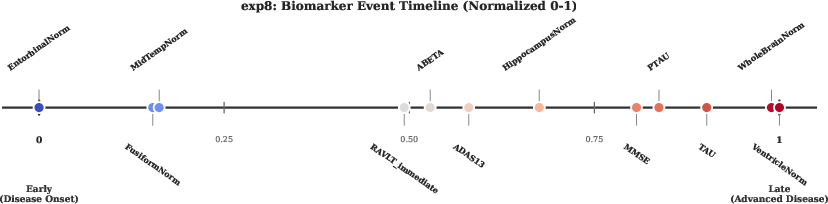
Figure 10: Continuous timeline of ADNI biomarker abnormality—structural onset is followed by prolonged preclinical gap, cognitive decline, and late-stage global degeneration/tau pathology.
Implications, Theoretical Consequences, and Future Directions
TEMPO establishes simulation-based supervised learning as a scalable, flexible, and empirically driven methodology for temporal disease progression modeling from cross-sectional data. Training on synthetic populations mitigates label scarcity and allows rapid evaluation of the impact of generative assumptions. The capability to infer continuous temporal spacing from cohort snapshots extends the utility of statistical disease progression models beyond ordinal ranking.
Theoretical implications include the decoupling of inference from likelihood derivation, enabling researchers to validate multiple generative hypotheses directly against clinical data. Practically, TEMPO's computational efficiency (seconds vs. minutes/hours for classical approaches at scale) democratizes large-scale hypothesis testing in clinical research.
A notable limitation remains TEMPO's dependence on the correctness of the generative simulation framework—model output quality is bounded by the realism of synthetic data. Extending TEMPO to longitudinal data and modeling subtype heterogeneity represents a logical next step. The architecture's token-based design and self-attention mechanisms are well poised for adaptation to longitudinal trajectories and multi-modal integration.
Conclusion
TEMPO provides a principled, performant, and flexible transformer-based approach for inferring temporal disease progression from cross-sectional data. It achieves substantial improvements in event sequencing and staging—both in accuracy and stability—across low- and high-dimensional settings. Its continuous temporal output and simulation-driven methodology fundamentally expand the scope of disease modeling, offering practical advantages for clinical hypothesis testing and theoretical modeling of disease dynamics. The approach represents a significant methodological advance, facilitating empirical alignment of generative models and clinical reality in neurodegenerative disease progression research.