- The paper presents a novel method using a pretrained LLM (Speech LLaMA) that reduces rare word transcription errors by 17%.
- It employs a decoder-only architecture with audio features and text tokens integrated via LoRa adapters, cutting down trainable parameters.
- The model exhibits robust performance under various noise and context perturbations, outperforming baseline RNN-T systems.
End-to-End Speech Recognition Contextualization with LLMs: A Summary
Introduction
The paper "End-to-End Speech Recognition Contextualization with LLMs" explores the integration of LLMs within Automatic Speech Recognition (ASR), transforming it into a mixed-modal language modeling task. Traditional ASR systems suffer from limited contextual incorporation, often focusing on token-level biasing. This paper counters these limitations by utilizing a pretrained LLM framework, allowing ASR systems to exploit broader contextual inputs like video descriptions or titles to reduce transcription errors, particularly for rare words and domain-specific terminologies.
Methodology
The proposed methodology leverages a decoder-only architecture in a novel approach termed Speech LLaMA. This model is architecturally simplified, employing a pretrained LLaMA LLM as a backbone for decoding. The system integrates audio features and optional text tokens, encouraging the assimilation of unstructured contextual data throughout training. The architecture consists of a layered audio encoder and a pretrained decoder adapted for ASR via LoRa.
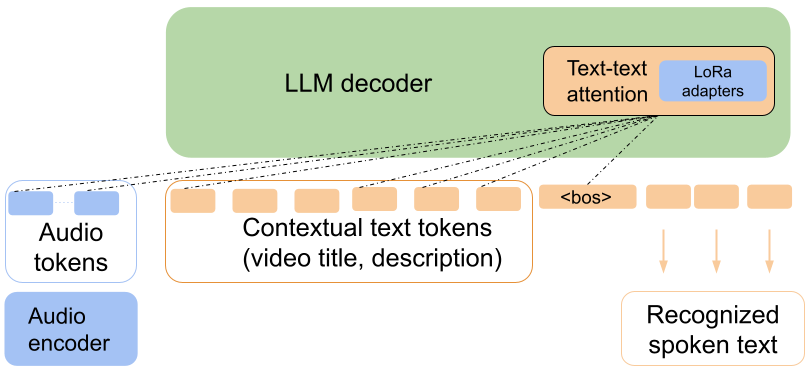
Figure 1: A speech recognition model with mixed-modal context consisting of audio and optional text tokens based on a pretrained LLM backbone. Speech encoder and LLM decoder are both initially pretrained. The LLM weights are frozen (orange blocks), while audio encoder and LoRa adapters are fine-tuned during training (blue blocks).
The paper highlights the significant savings in trainable parameters, noting improvements in word error rate with minimal computational expense by employing adapters instead of retraining the entire model.
Experimental Setup and Results
Extensive experimentation was conducted on a de-identified, speech-augmented in-house dataset derived from public videos, facilitating rigorous testing under variable contexts. The Speech LLaMA model achieves notable performance improvements, surpassing a baseline contextual RNN-T system with a 17% reduction in WER for rare words, despite being trained on a substantially smaller dataset.
The empirical evaluation indicates that even without contextual information during training and evaluation, the Speech LLaMA achieves competitive WER, showcasing its robustness. Detailed ablation studies reveal the model's exceptional ability to leverage context-related prompts effectively, reducing errors by adapting to linguistic cues masked into the input. The model performs commendably across various noise perturbations in context settings, confirming its ability to discriminate relevant text effectively.
Discussion on Context Sensitivity
The model's ability to perform under altered context conditions is analyzed through several perturbation strategies. The findings confirm the robustness of contextual understanding when challenged with both random and phonetically similar substitutions, demonstrating the model's potential for improving recognition of domain-specific and rare terms by emulating context-based bias effectively.
Additionally, evaluations comparing causal and full masking strategies in the architectural setup affirm only marginal performance differences, underscoring the model's inherent design efficiency under varied decoder configurations.
Future Directions
The research suggests multiple avenues for extending context length through innovative attention scaling. Exploring strategies like lower precision training and linear attention mechanisms could alleviate cost constraints associated with the quadratic attention complexity inherent in large sequence processing.
Conclusion
The integration of LLMs within ASR as explored in this paper delineates a promising direction for enhancing ASR systems with unstructured contextual leverage. This work posits that using pretrained LLMs for contextual biasing and speech recognition is inherently viable and advantageous at scale, proving especially effective in rare word recognition. Future research could extend these principles towards more adaptive models supporting an even broader context and multimodal inputs. The proposed method's impressive performance relative to established benchmarks sets a significant precedent for future innovations in speech recognition technology.
