- The paper presents DisambiguSLM, a modular framework that preprocesses and clarifies ambiguous prompts using small language models.
- The methodology employs dual-path verification and conflict resolution to reduce attention dispersion and improve reasoning accuracy by up to 8 points.
- Empirical results demonstrate significant attention reallocation from non-informative tokens to key semantic anchors, enhancing LLM stability and robustness.
Semantic Disambiguation of LLM Prompts with Small LLMs
Motivation and Problem Statement
Semantic ambiguity in user-supplied prompts fundamentally impairs the reliability and stability of LLMs in reasoning-intensive tasks. In naturalistic usage, prompts are replete with underspecified references, implicit assumptions, and logical gaps that LLMs must implicitly resolve, often leading to high attention dispersion, stochastic reasoning paths, and variable output quality. Prior prompt optimization methods—including Chain-of-Thought (CoT), self-consistency, agent-based search, and automatic prompt engineering—offer gains but treat ambiguity as a downstream issue, relying on the LLM’s internal mechanisms to resolve risks at inference time. This approach does not explicitly detect, verify, or rectify semantic uncertainty at the prompt level, leaving LLM behavior sensitive to prompt formulation idiosyncrasies.
The paper "Small LLM Helps Resolve Semantic Ambiguity of LLM Prompt" (2604.23263) addresses this deficiency by proposing an upstream, cost-efficient prompt optimization mechanism—DisambiguSLM—that explicitly resolves semantic ambiguities before LLM inference. The innovative element is the use of small LLMs (SLMs) not to solve target tasks directly, but to proactively identify, verify, and reconcile semantic risk points in prompts, resulting in semantically clarified inputs with minimized reasoning path entropy.
DisambiguSLM Framework and Design
DisambiguSLM is organized as a modular, multi-layered pipeline that leverages SLMs for prompt preprocessing across distinct semantic harmonization stages.
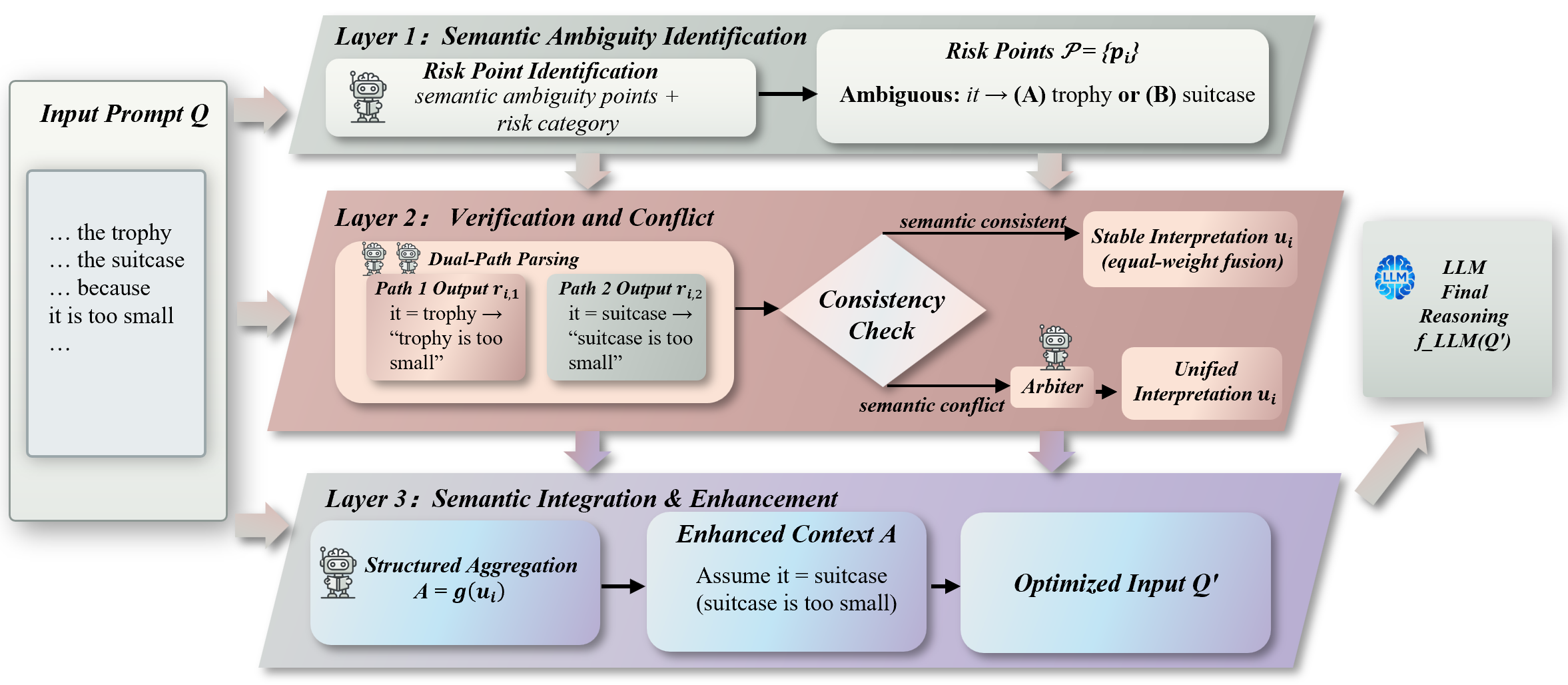
Figure 1: Framework of DisambiguSLM: identification of semantic risks, dual-path verification and conflict resolution, and semantic integration to produce a non-ambiguous prompt.
1. Semantic Risk Identification
An SLM is used as a global semantic scanner to perform fine-grained analysis of the input prompt, identifying spans with ambiguity, missing assumptions, or temporal uncertainty. Each risk point is formalized with its position and risk type, ensuring the upstream localization of instability sources without committing to specific interpretations.
2. Dual-Path Consistency Verification and Conflict Resolution
Each risk point is independently passed to two SLM instances, yielding two distinct semantic interpretations. The representations’ similarity is computed in embedding space. If consistent (above a threshold), their explanations are fused; if inconsistent, a further SLM instance synthesizes a logically unified, self-consistent interpretation given both variants and the broader context. This dual-path design reduces hallucination probability through redundancy and cross-verification, suppressing singleton errors and expanding semantic coverage.
3. Semantic Integration and Enhancement
All resolved risk explanations are sent to another SLM, which aggregates and structurally enhances them into a concise semantic representation. This enhanced context, concatenated with the original prompt, serves as a clarified, non-ambiguous input to the downstream LLM.
Attention Dynamics and Entropy Analysis
A central claim is that DisambiguSLM improves LLM attention allocation by concentrating it on semantically critical tokens, suppressing both spurious inference paths and entropy-driven attention diffusion.
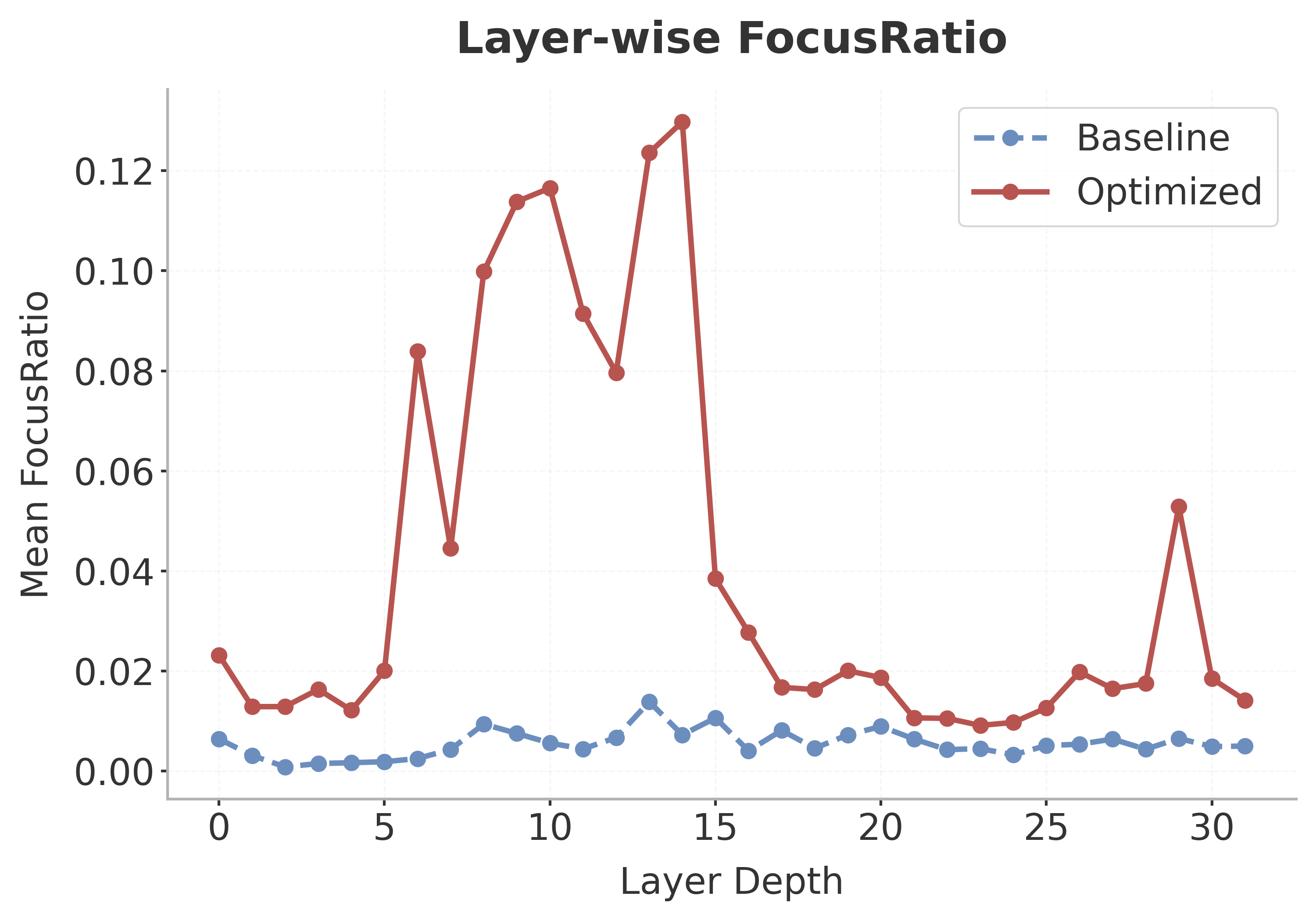
Figure 2: Layer-wise focus ratio comparison between Q (ambiguous) and Q′ (disambiguated); Q′ yields higher attention focus in key reasoning layers.
DisambiguSLM increases the attention focus ratio in LLMs considerably—by up to 8–10× in early reasoning layers—relative to ambiguous prompts, evidencing more efficient resource allocation to crucial semantic anchors.
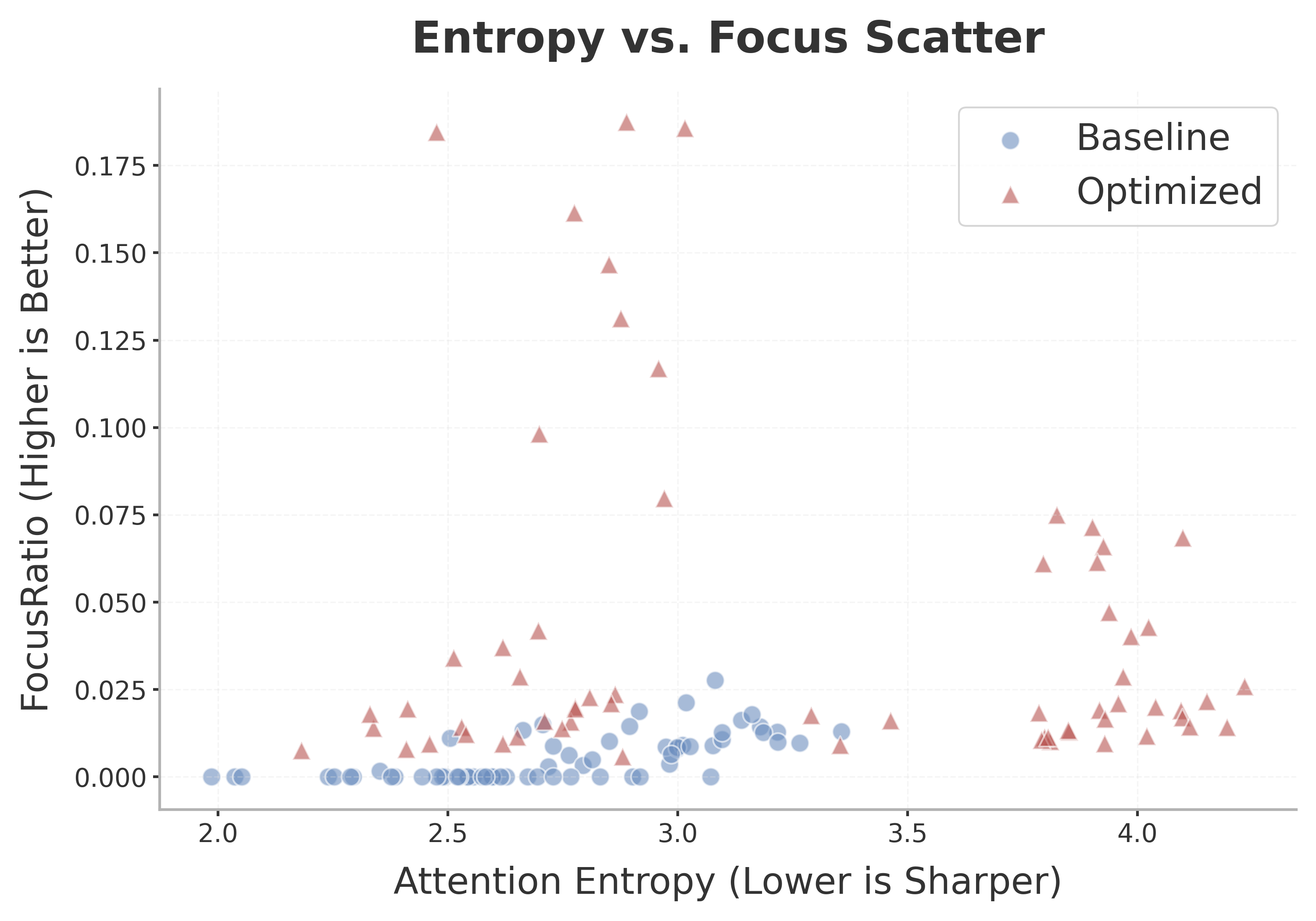
Figure 3: Comparison of entropy-focus ratio joint distributions: Q′ shifts the high-focus region to lower-entropy regimes, confirming reduced reasoning uncertainty.
The joint entropy-focus analysis demonstrates that DisambiguSLM systematically shifts attention to low-entropy, high-focus allocations, minimizing competitive reasoning branches and mitigating uncertainty propagation.
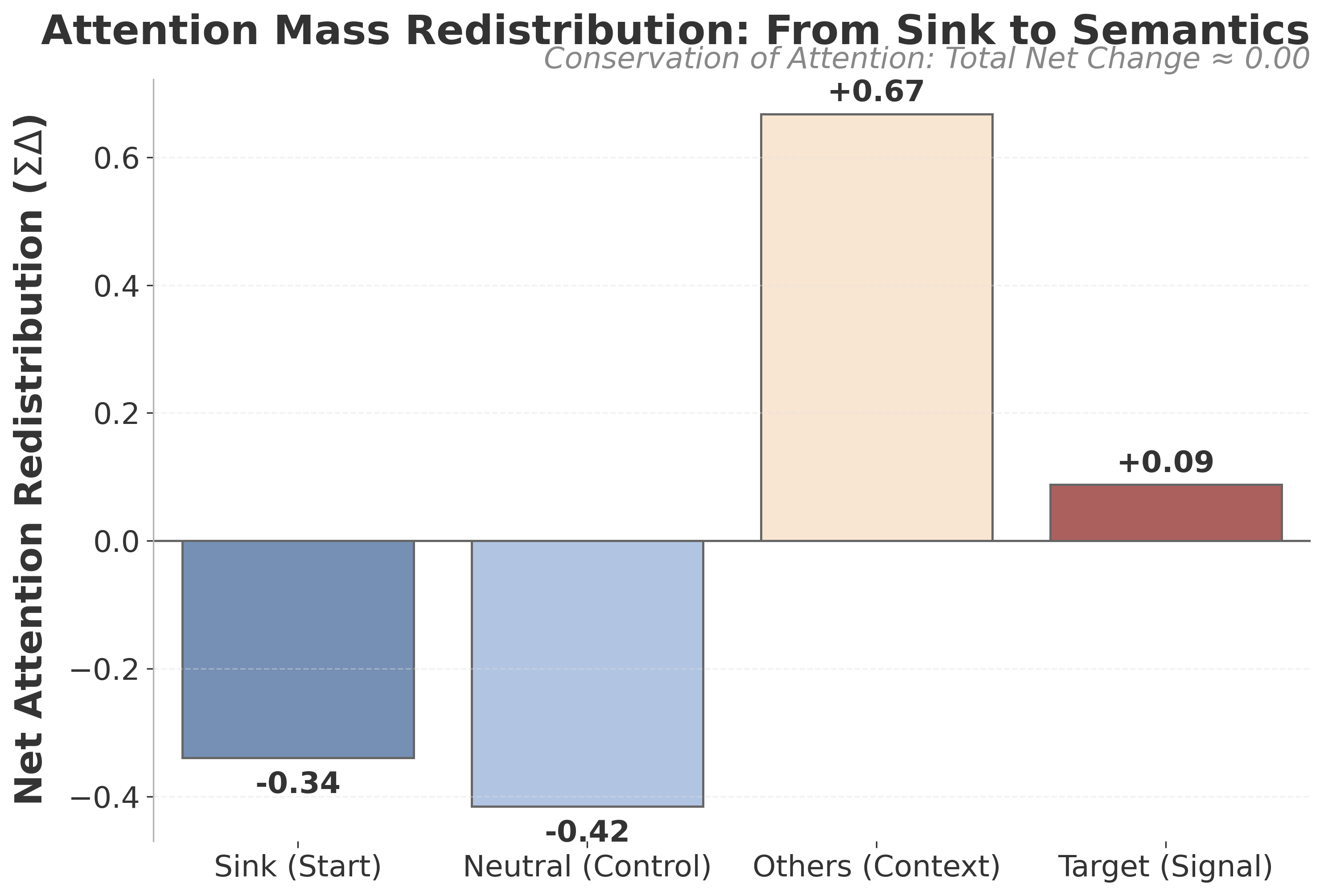
Figure 4: Token-wise attention reallocation; DisambiguSLM moves attention from sink/stopword tokens to semantically meaningful anchors needed for correct task resolution.
Token-level analysis confirms that attention is withdrawn from non-informative tokens and redistributed to target and supporting tokens critical for task success—validating the premise of upstream semantic risk rectification.
Quantitative Results
Empirical evaluations span diverse LLM architectures (GPT-4o-mini, LLaMa-3-70B, DeepSeek-V3) and multiple reasoning-centric benchmarks:
- DisambiguSLM achieves up to +8 accuracy points over naïve prompting and +2.5 points over the best prior prompt optimization methods (e.g., OPRO, SPO, TextGrad) at a negligible computational cost ($\$0.02$ per optimized prompt).
- Largest improvements are observed in tasks sensitive to reference resolution and ambiguity (e.g., Winograd Schema Challenge, LIAR), indicating effective reduction of semantic risk prior to inference.
- DisambiguSLM systematically reduces disagreement rates and output instability, with disagreement rates on ambiguous inputs falling by over 50% compared to all baselines.
- In robustness tests on systematically ambiguity-augmented variants, DisambiguSLM delivers highest accuracy and least degradation, confirming the method’s resilience to escalated semantic uncertainty.
Ablation and Sensitivity Analyses
Ablations show each pipeline stage—risk identification, dual-path verification, conflict resolution, and structured aggregation—contributes nontrivially to performance. Eliminating dual-path verification or conflict resolution causes marked drops, especially on ambiguity-heavy benchmarks.
Increasing SLM size past 1B parameters yields diminishing returns, demonstrating that prompt-level semantic harmonization depends on structured method design, not model scale. Performance is also insensitive to the semantic similarity threshold within reasonable bounds, attesting to the robustness of the pipeline.
Theoretical and Practical Implications
DisambiguSLM redefines prompt optimization as an input-level semantic filtering and compression problem, rather than a mere surface-level rephrasing or model-internal reasoning issue. This externalizes ambiguity management, constrains inference path entropy, and improves interpretability and convergence of LLM behavior. The architecture is cost-efficient and parallelizable; SLMs impose negligible latency or deployment cost and can be deployed on commodity hardware.
From a systems perspective, DisambiguSLM offers a scalable path to robust LLM deployment in safety- and consistency-critical applications, facilitating reliable reasoning under naturalistic, ill-formed prompt conditions. Theoretically, the work aligns with research on semantic risk modeling, attention entropy reduction, and multi-agent collaborative reasoning in LM ecosystems.
Future Directions
Potential extensions include adaptation to multimodal inputs (audio, vision-text), richer taxonomy of semantic risk types, and integration with retrieval or verification pipelines to address factual uncertainty (as opposed to mere semantic ambiguity). DisambiguSLM could also interoperate with modular agent-based LLM systems to partition upstream (semantic) and downstream (factual) risk management, further advancing robust and trustworthy AI reasoning.
Conclusion
DisambiguSLM establishes explicit, structured semantic ambiguity resolution—executed by small, efficient LLMs—as a foundational advance in prompt optimization for LLM-based reasoning. The approach achieves superior reasoning accuracy, stability, and robustness across ambiguous and complex scenarios, cost-effectively externalizing ambiguity management without modifying LLM internals (2604.23263). The work charts a pathway for upstream semantic preprocessing as an essential component of future LLM systems.

