- The paper introduces an affordance-driven pipeline that maps human demonstration videos to robot manipulation policies without relying on robot data.
- It uses multimodal vision-language models and a diffusion-based motion generator to predict task-conditioned 3D flows with superior success across varied tasks.
- The framework generalizes robustly across novel objects and scenes, enabling scalable human-to-robot policy transfer for both single-object and object-to-object interactions.
The acquisition of robotic manipulation skills from human demonstration videos represents a scalable paradigm for robotics, leveraging the vast diversity and ease of collection inherent in human-centric datasets. However, direct transfer from human videos to executable robot policies is impeded by embodiment gaps, absence of robot demonstration data, and inadequate affordance representations that often remain at perception-level or lose actionable geometric specificity. Most prior approaches either necessitate robot data for adaptation, rely on 2D perception-level cues lacking controllable geometry, or focus on post-grasp object-centric flows, failing to capture complex interaction structure.
BridgeACT introduces an affordance-driven solution that obviates the requirement for robot data, modeling affordances as embodiment-agnostic intermediate representations that explicitly organize tool-target relationships. The framework decomposes manipulation into two sub-problems: localizing task-relevant grasp regions and predicting task-conditioned 3D motion affordances. This affordance-centric pipeline enables direct mapping from human demonstrations to robot actions and robust generalization across diverse tasks, entities, and scenes.
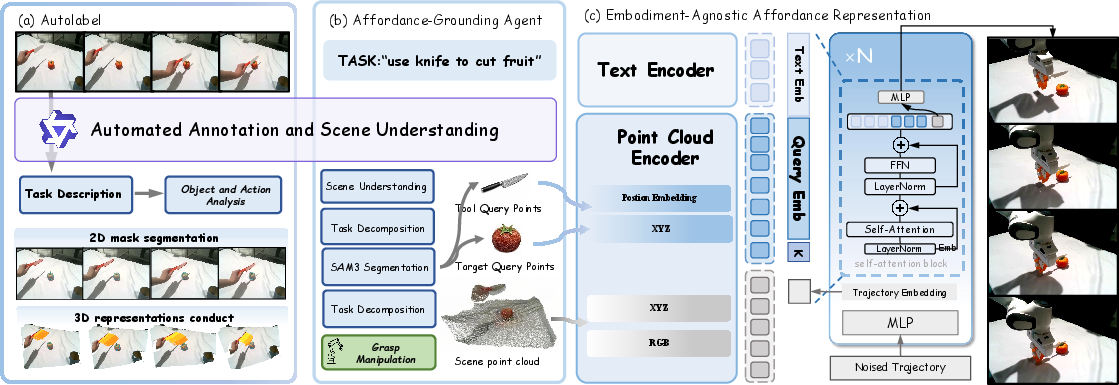
Figure 1: Pipeline schematic of BridgeACT, comprising automated extraction and annotation from raw human videos, affordance grounding by localizing tool-target regions, and embodiment-agnostic prediction of interaction-centric 3D point flows via diffusion modeling.
Data Construction and Representation
BridgeACT leverages a scalable automated pipeline for constructing a motion point-flow dataset from multimodal human demonstration sources. The process integrates VLM-based task understanding, object-action annotation, 2D mask segmentation, pointwise tracking, and 3D trajectory reconstruction, amalgamating egocentric and third-person videos into a unified supervision format. Each sample is represented by scene point clouds, tool and target geometric anchors, and language instructions—explicitly retaining both tool and target queries to enable stable relative motion modeling, particularly critical for object-to-object (O2O) manipulation.
The role specification distinguishes the executor (human hand or tool object) and manipulated entity, ensuring compositionality across single-object and O2O tasks. Point-based representations of operable regions facilitate geometric localization, while the system robustly handles camera motion, occlusion, and annotation heterogeneity.
Affordance Grounding and Motion Generation
The affordance grounding agent utilizes multimodal LLMs and vision-LLMs to parse task instructions, extract semantic descriptions of operable regions, and generate prompt-conditioned segmentation masks. Verifiers assess functional validity of proposed masks, with recovery strategies to mitigate unstable segmentation. Final masks yield 3D query points via projection onto scene geometry.
The 3D affordance representation employs separate embedding of scene points and query anchors, followed by PointNeXt encoding and late fusion with CLIP-extracted language features. Downstream motion generation is realized with a transformer-based diffusion model, predicting temporally coherent 3D displacement sequences for query points. The design preserves pointwise correspondence and integrates robust losses, including min-SNR weighting, motion-aware reweighting favoring high-displacement queries, and accumulative trajectory penalties to enhance temporal stability and mitigate static-point bias.
Robot Execution and Closed-Loop Control
Affordance predictions, represented as explicit geometric flows, are directly compatible with control primitives. Grasp affordances are handled by off-the-shelf modules for pose generation, while motion affordances drive closed-loop end-effector control via rigid alignment strategies (ICP registration). The robot iteratively estimates transformations from live observations, enabling adaptation to dynamic scene changes and maintaining execution reliability across manipulation trials.
Experimental Evaluation
BridgeACT was evaluated on a suite of real-world manipulation tasks—open/close, pickup/place, pour, and cut—each comprising both grasp and motion stages. Performance was benchmarked against ReKep, General Flow, and Track2Act. BridgeACT achieved consistently superior success rates across all tasks, especially demonstrating robustness in O2O scenarios and superior executability on novel objects and backgrounds.

Figure 2: Visual comparison of trajectory predictions: BridgeACT (left) and General Flow (right), on in-domain (close oven) and out-of-domain (pickup basket) tasks.
Notably, BridgeACT maintained correct spatial geometry and motion semantics under domain shifts, while baselines suffered from trajectory inversion, drift, or lateral flow mispredictions. The diffusion-based motion generator exhibited greater expressivity and stability than CVAE baselines and handled distributional shifts in object identity, scene clutter, and viewpoint variations.
Generalization and Ablation
Zero-shot generalization experiments assessed cross-object and cross-scene performance on pickup, open, and cut tasks. BridgeACT consistently matched or outperformed baselines, retaining functional motion direction and interaction structure despite environmental and entity changes.

Figure 3: Trajectory visualizations under cross-object and cross-scene settings, demonstrating BridgeACT’s generalization in cluttered scenes and with unseen objects.
Ablations revealed that adaptive motion-aware weighted loss is necessary for optimal trajectory accuracy, with removal resulting in increased displacement errors. PointNeXt backbone achieved preferable trade-offs in model complexity and throughput compared to Point Transformer v3, and late fusion of language features outperformed early fusion, confirming the geometric specificity of backbone encoders.
Theoretical and Practical Implications
BridgeACT advances an affordance-driven methodology for human-to-robot policy transfer, emphasizing embodiment-agnostic representations and explicit interaction-centric modeling. By unifying single-object and O2O tasks, and leveraging scalable vision-language automation in dataset construction, it provides a flexible interface for future large-scale internet-based robot learning. Explicit 3D affordances enable direct integration with diverse planning and control architectures, reducing reliance on robot demonstration data and increasing applicability in open-world settings.
Challenges persist in rotational motion inference and fine-grained contact modeling due to inherent ambiguities in human demonstration videos. Further research is warranted to incorporate dynamics modeling, physics priors, and rotational precision into the affordance learning framework.
Conclusion
BridgeACT demonstrates that embodiment-agnostic, interaction-centric affordance representations learned from human videos are sufficient for robust robotic manipulation policy transfer. The framework surpasses baselines in executability, generalization, and stability, offering a scalable route toward foundation models in robotics that operate exclusively from human demonstration data. Future directions include refinement for rotational and fine-grained interaction tasks and expansion to broader cross-domain internet-scale sources.