- The paper introduces TraceGuard, a black-box antidistillation method based on a Stackelberg game framework to robustly degrade student model accuracy.
- The methodology employs sparse perturbations on critical reasoning tokens, achieving significant accuracy drops without requiring teacher retraining.
- Empirical evaluations show that targeted removal of thought anchors outperforms random deletion, offering a scalable defense for preserving intellectual property.
Protecting the Trace: A Principled Black-Box Approach Against Distillation Attacks
The increasing availability of reasoning traces from frontier LLMs has inadvertently exposed model providers to distillation attacks, where adversaries replicate or even surpass the capabilities of costly, closed-source models. This presents significant concerns related to intellectual privacy, model theft, and the erosion of safety alignment in distilled models. The paper introduces a rigorous game-theoretic formalization of antidistillation as a Stackelberg game, directly motivating defensive strategies with theoretical guarantees and unifying prior ad hoc approaches under a robust framework.
The authors delineate critical distinctions between classical data poisoning and antidistillation: the defender (teacher provider) lacks prior knowledge of the downstream student architecture, requiring defenses to maximize error across an admissible architectural set. The robust optimization objective guides the defender to seek universally damaging perturbations against all possible adversarial student instantiations, rather than exploiting idiosyncrasies of known targets.
Theoretical Foundations and Analysis
A formal bi-level optimization setup is presented, where the defender maximizes the minimum population loss among all feasible student models trained on the poisoned traces. The paper generalizes prior methods—such as Antidistillation Sampling (ADS) and Defensive Output Generation (DOGe)—within this robust Stackelberg framework, rigorously demonstrating their equivalence to specific architectural assumptions and constraint sets.
A key theoretical contribution is the detectability analysis. The authors show, via KL-divergence bounds, that sparse perturbations—modifying a limited number of critical tokens—are substantially less detectable than uniformly distributed perturbations, supporting the principle that judicious token selection is imperative for practical defense.
Sparse Perturbations and Critical Reasoning Steps
Practical implementation of sparse perturbations faces obstacles, notably the challenge of identifying which tokens or sentences in a reasoning trace warrant intervention. The literature in LLM interpretability reveals that "thought anchors"—structurally significant planning or uncertainty sentences—are disproportionately important for both teacher output and downstream student learning (Bogdan et al., 23 Jun 2025). Targeting these branching tokens provides an efficient and theoretically justified means of degrading student distillation, avoiding the combinatorial complexity of arbitrary token selection and minimizing grammatical incoherence.
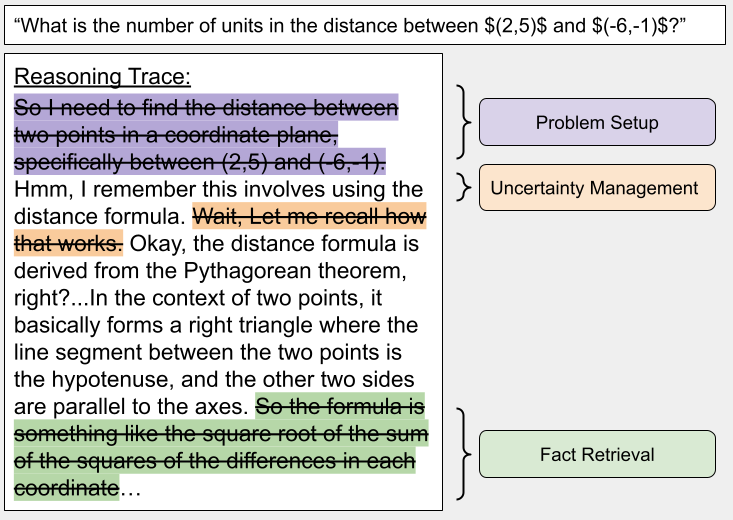
Figure 1: Example trace poisoning with the TraceGuard method, where each removed sentence corresponds to a thought anchor.
TraceGuard: Efficient Antidistillation Without Retraining
The authors introduce TraceGuard, a post-generation, black-box antidistillation technique that removes sentences flagged as thought anchors via lightweight keyword heuristics. By excising only the most consequential branching sentences, TraceGuard achieves substantial degradation of student model accuracy while maintaining teacher performance and coherence. No proxy models or teacher retraining are required, making the method scalable and robust in settings where architectural information about the adversary is unavailable.
Empirical Evaluation
The paper demonstrates that distillation performance degradation is positively correlated with the number of poisoned tokens in branching sentences. For teacher DeepSeek-R1-Distill-Qwen-7B and various 1–3B parameter student models, TraceGuard causes notable accuracy drops in the student models proportional to the poisoned anchor tokens.
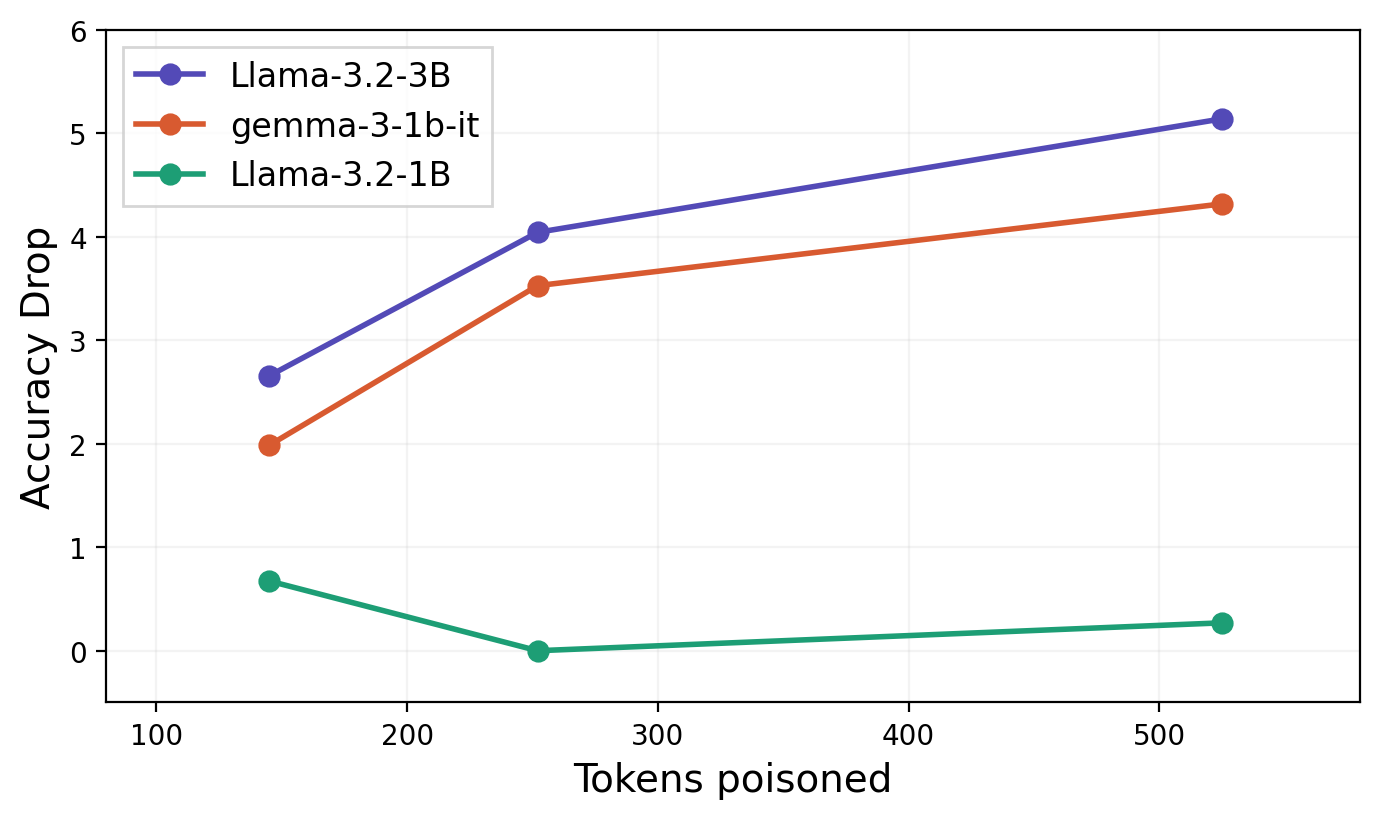
Figure 2: Accuracy drop between baseline and poisoned reasoning trace distillation as a function of the number of tokens removed from branching sentences.
Comparative experiments indicate that random sentence removal is largely ineffective, confirming the pivotal role of thought anchors in the distillation process, and validating the theoretical and empirical efficacy of TraceGuard.
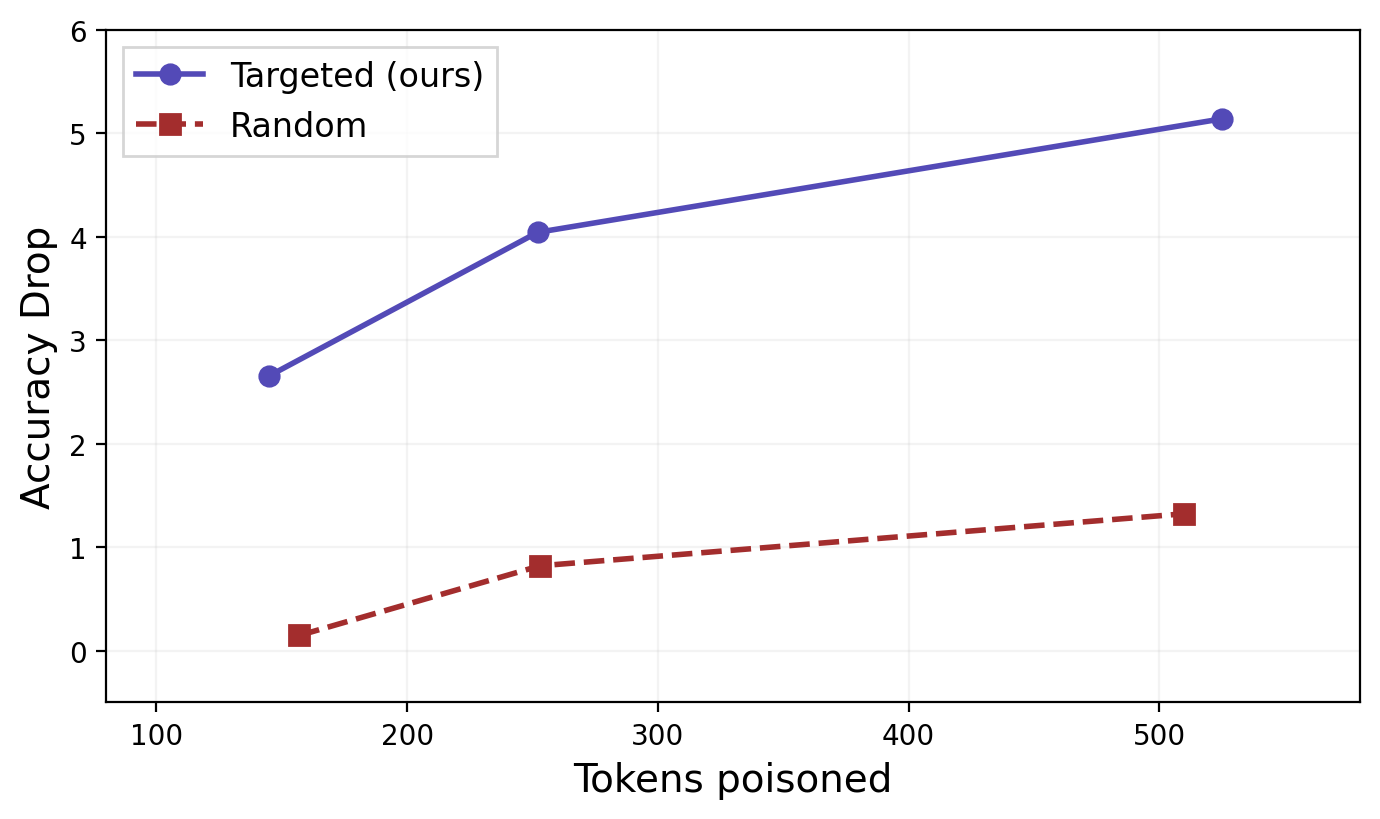
Figure 3: TraceGuard significantly outperforms random sentence removal in suppressing student distillation accuracy for equivalent token removal budgets.
Practical and Theoretical Implications
The formalization and empirical results highlight several consequences:
- AI Safety and Policy: Distillation attacks threaten intellectual property, safety, and compliance with evolving legal regulations (e.g., US H.R. 8283 [HR8283]), suggesting the need for robust antidistillation protocols in model deployment pipelines.
- Alignment Preservation: Loss of safety alignment following distillation is a major risk (Jahan et al., 10 Dec 2025, Li et al., 7 Jan 2026). TraceGuard presents a lightweight, theoretically justified method for mitigating this risk without sacrificing teacher performance.
- Defensive Strategy Design: The Stackelberg game perspective introduces new avenues for cryptographically-grounded defenses, Bayesian architectural priors, and modular composition of poisoning strategies.
Limitations and Future Directions
TraceGuard leverages keyword heuristics for thought anchor identification, which may lack precision compared to attention-based methodologies. The KL-divergence bounds assume token independence, an idealization. Further research is warranted to develop computationally efficient, accurate identification of functional reasoning steps and to extend detectability analyses to more complex dependency structures.
Future lines include modeling side-information about attack attempts, dynamically adjusting poisoning budgets, and integrating interpretability research to refine defense targeting. The framework also motivates the development of broader, architecture-agnostic defense strategies relevant to both policy and technical deployment.
Conclusion
The paper advances antidistillation defense by establishing a principled, robust formulation, demonstrating that sparse, critical interventions are theoretically optimal for detectability and effectiveness. TraceGuard offers a practical, scalable solution for protecting reasoning traces, countering unauthorized distillation attacks, and supporting the ongoing evolution of secure, safe AI deployment.