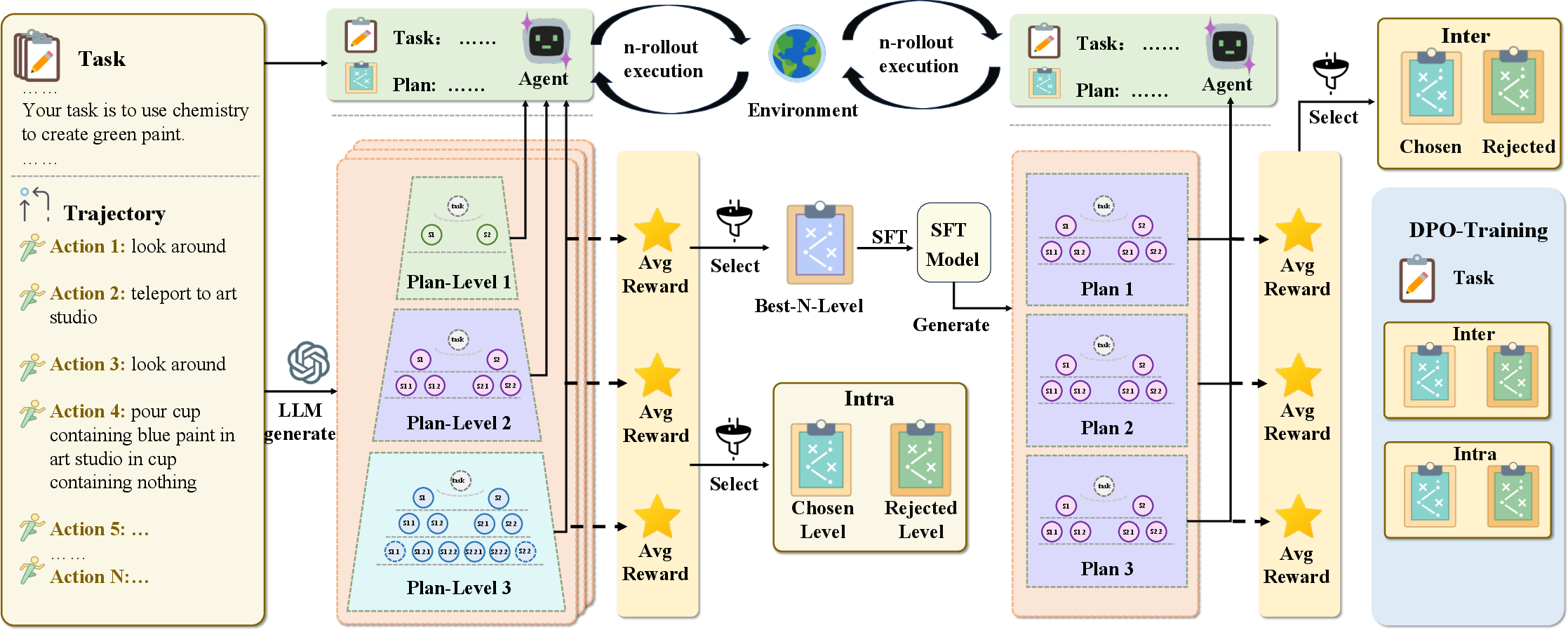
- The paper presents a self-adaptive hierarchical planning framework (AdaPlan-H) that dynamically adjusts plan granularity to match task complexity through iterative refinement.
- It employs a two-stage optimization using imitation learning and Direct Preference Optimization to enhance plan quality, yielding significant performance gains on ALFWorld and ScienceWorld.
- Experimental results confirm that adaptive multi-level planning increases both efficiency and accuracy, supporting robust integration with various LLM agent architectures.
Self-Adaptive Hierarchical Planning for LLM Agents: AdaPlan-H
Motivation and Problem Statement
Advances in LLM agent architectures have focused on explicit task planning to increase action consistency and success rates in dynamic, multi-step environments. However, most prior methods utilize fixed-granularity plans, which either lack sufficient detail for complex tasks or provide unnecessarily fine granularity in simple scenarios, causing inefficiency. This fixed granularity precludes optimal adaptation across diverse task complexities. AdaPlan-H, inspired by progressive refinement in cognitive science, addresses this gap by enabling dynamic, hierarchical plan generation that matches task complexity. The approach empowers agents to begin with high-level macro plans and iteratively refine them, yielding flexible plans tailored to specific task demands.
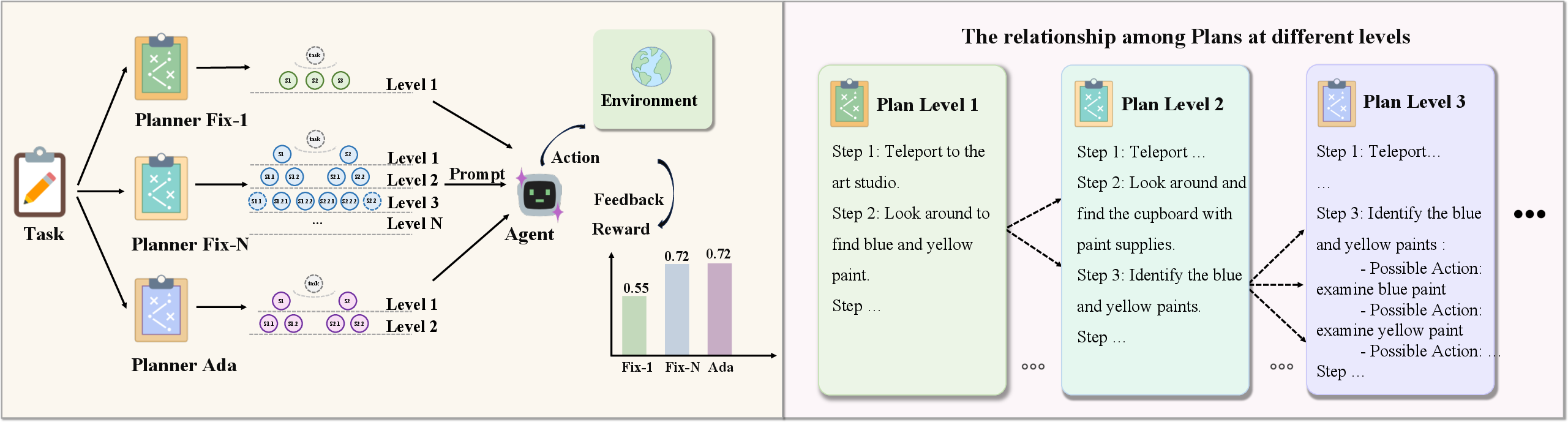
Figure 1: Hierarchical plans facilitate agent-environment interaction with reward feedback, and the degree of detail distinguishes hierarchical levels with inheritance across levels.
Methodological Framework
Hierarchical Planning Architecture
AdaPlan-H models the plan generation process as a sequence of progressively refined plans, each representing a level in the hierarchy. At every planning stage, the planner produces a plan pi conditioned on the task instruction and all prior plan levels:
pi=fp(u,pi−1,…,p1,θp)
where u is the task instruction, m is the number of plan levels (adaptively chosen based on task complexity), and θp denotes planner parameters. The concatenated plan across all levels provides both global and local guidance for the actor. The granularity of planning is thus dynamic: number of levels and detail per level are tuned to task difficulty.
Two-Stage Optimization
AdaPlan-H is trained using a two-stage process:
- Imitation Learning (SFT Initialization): Hierarchical plans are generated by GPT-4o using correct task execution trajectories, with N candidate plans per instruction. The optimal plan granularity and corresponding hierarchy level are selected via a Monte Carlo method, maximizing the average reward in simulated task completion with Llama-3.1-8B as actor. This selected plan and its hierarchy level serve as supervised signals for SFT initialization.
- Capability Enhancement (DPO Training): AdaPlan-H further leverages preference datasets:
Experimental Evaluation
Datasets and Metrics
Experiments are conducted on ALFWorld (embodied household tasks) and ScienceWorld (text-based scientific tasks), with both seen (in-domain) and unseen (out-of-domain) splits. Task success rates and average reward are measured, with explicit plans provided as prompts to various actor backbones.
Main Results
AdaPlan-H achieves substantial improvements in task execution across all actor models, outperforming baseline planning methods and meta-plan optimization (MPO), particularly in ALFWorld (0.8500 on seen, 0.8881 on unseen with Qwen2.5-7B actor) and ScienceWorld (0.7349 seen, 0.6766 unseen with Qwen3-8B actor). The method mitigates overplanning, maintaining efficiency while maximizing success rates. When planner-actor backbone consistency is preserved in Monte Carlo plan evaluation, performance increases further.
Ablation and Analysis
Ablation studies confirm the necessity of both intra- and inter-dataset preference optimization within DPO. Removing either impairs plan adaptability and quality, underscoring AdaPlan-H's dual-stage paradigm. Fixed-level planning variants demonstrate that excessively granular plans can degrade performance, validating the adaptive hierarchy hypothesis.
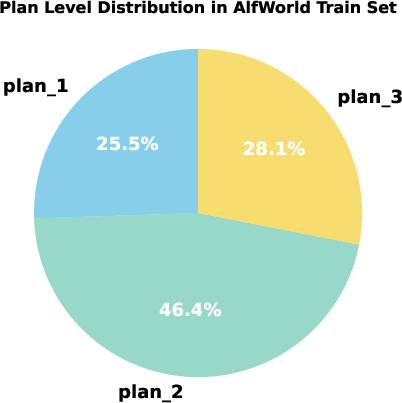
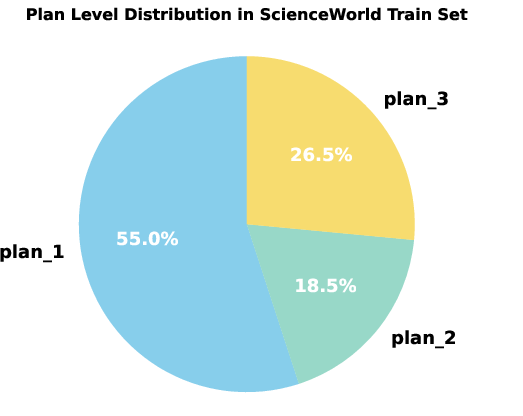
Figure 3: Distribution of optimal hierarchical plan levels for tasks in ALFWorld, illustrating task-dependent granularity requirements.
Hierarchical prompts, as opposed to using only the lowest level, significantly enhance agent alignment and task accuracy, substantiating the inheritance mechanism between levels and the utility of global guidance in plan execution.
Practical and Theoretical Implications
AdaPlan-H establishes a scalable framework for modular agent planning: planners can be fine-tuned independently of the actor, rendering the approach compatible with diverse open-source models and future large-scale deployments. Hierarchical plans are structurally aligned with human cognitive strategies, offering interpretability and robustness. The adaptive mechanism avoids token wastage and increases generalization in long-horizon tasks.
Theoretically, AdaPlan-H highlights the importance of plan structure in sequential decision-making, suggesting that explicit multi-level representation can counteract challenges of long-range dependencies and environmental uncertainty. The framework’s adaptability paves the way for extensions into complex, multi-modal or real-world environments.
Future Directions
Future research could probe deeper hierarchies beyond three levels, adapt AdaPlan-H to more complex or multi-modal environments (e.g., vision-language tasks), and explore richer actor-planner interactions for improved grounding and robustness. Leveraging stronger backbone models for plan generation and evaluation can further refine plan quality and agent performance.
Conclusion
AdaPlan-H introduces a self-adaptive hierarchical planning framework that integrates progressive refinement into LLM agent architectures. It dynamically matches plan detail to task complexity via imitation learning and preference optimization. Empirical results validate its superiority over fixed-granularity methods and single-level planners, demonstrating versatile improvements in efficiency and accuracy. AdaPlan-H’s modularity and adaptive design signal key directions for future LLM agent research in hierarchical and dynamic planning.