- The paper presents RAT, a modular framework that fully automates language-agnostic repository environment configuration using LLMs and Docker sandboxing.
- It achieves up to a 29.6% improvement in Environment Setup Success Rate, outperforming traditional and prompt-based methods.
- A comprehensive benchmark, RATBench, validates its scalability and robustness across over 2,000 multilingual repositories with diverse configurations.
RAT: RunAnyThing via Fully Automated Environment Configuration
Motivation and Research Problem
The automation of environment configuration remains a core technical bottleneck in scaling LLM-driven agents to handle repository-level software engineering tasks. While LLMs have achieved proficiency in fragmentary code generation, repository-level automation requires the robust synthesis of complex, interdependent, and often underspecified executable environments. Manual configuration is costly, inconsistent, and impedes reproducibility. Prior approaches suffer from over-reliance on repository-specific configuration artifacts or limited language/domain support, preventing generalizable, scalable deployment across thousands of real-world repositories. RAT (RunAnyThing) addresses these limitations by introducing a fully automated, language-agnostic environment configuration framework, accompanied by a comprehensive and realistic benchmark, RATBench.
RAT Framework: Architecture and Methodological Advances
RAT is a modular agentic system composed of four primary modules: Language-Agnostic Abstraction, ImageRetriever, Agent Planning, and a Specialized Toolset, all operating in a robust and isolated docker-based sandbox.
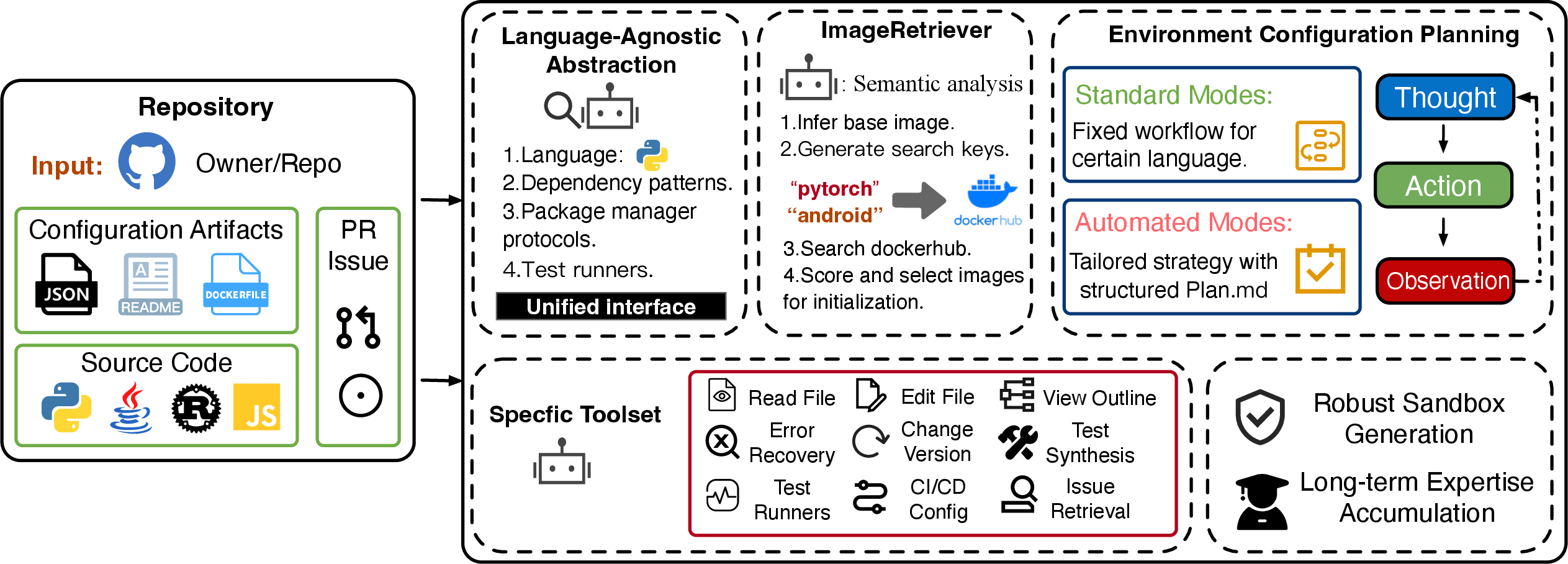
Figure 1: The architecture of RAT (RunAnyThing), with language abstraction, image retrieval, agent planning, and a specialized toolset in a robust sandbox.
- Language-Agnostic Abstraction: The framework detects primary project languages and abstracts language-specific environment setup protocols (e.g., package managers, build manifests, test runners) into a unified interface, enabling cross-language operation.
- ImageRetriever: Applies LLM-driven semantic analysis to select an optimal base image. It utilizes both a default image set and dynamic Docker Hub search, using an LLM-based scoring to maximize environment match, thus improving initialization reliability and reducing misconfiguration overhead.
- Agent Planning: Supports both a Standard Plan Mode (fixed, language-centric) and an Automated Plan Mode leveraging document-based external memory (
plan.md) for long-horizon reasoning and persistent state tracking, crucial for highly heterogeneous or ambiguous repositories.
- Specialized Toolset: Integrates a suite of domain-relevant, contextually abstracted tools for file and dependency graph analysis (e.g.,
Read File, Edit File, Ls Structure, View Outline), environment introspection, dynamic language version switching, CI/CD config parsing, test synthesis, and robust error recovery (including semantic web, issue pool, and StackOverflow search).
Notably, all operations occur inside a rigorously validated sandbox, ensuring repeatability and preventing host contamination. The system accumulates executable trace-based expertise in a serialized schema for continual improvement.
RATBench: Realistic, Multilingual, Large-Scale Benchmarking
RATBench is proposed as a multilingual environment configuration benchmark with over 2,000 repositories sampled for maximal diversity in project size, popularity (measured by GitHub stars), programming languages (Python, Java, Rust, JS/TS), and environment artifact availability. Its construction involves stratified sampling, language-specific inclusion signals, and executability verification, ensuring that the benchmark distribution mirrors real-world software complexity.
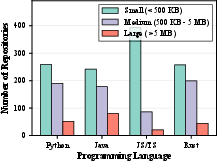
Figure 2: Repository size distribution across languages in RATBench.
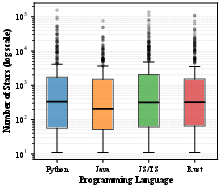
Figure 3: Repository popularity (GitHub stars) distribution by language in RATBench.
This approach solves the limitations of earlier benchmarks, which focused on a single language, static analysis, or trivially configured samples. Diversity in RATBench exposes the full spectrum of environment failure modes across major ecosystems.
RAT is evaluated against state-of-the-art static analysis methods, prompt-based LLM inference (zero-shot), software engineering agents (SWE-agent), and specialized environment configuration agents (Installamatic, Repo2Run). The primary metric is Environment Setup Success Rate (ESSR), defined as the fraction of passing tests or build verifications in the constructed environment.
- RAT achieves a mean ESSR improvement of 29.6% over strong baselines across four languages. On Python repositories, RAT attains 63.2% ESSR, easily surpassing pipreqs (35.8%) and Repo2Run (44.8%). On Rust and JS/TS, the ESSR approaches 99% and 69%, respectively.
- Ablation studies show that removal of the ImageRetriever or the specialized toolset results in large ESSR drops (to 40.5% and 55.7%, respectively), quantifying the importance of semantically optimized image selection and purpose-built agentic tools.
- Scaling analysis indicates that increasing computational budget (interaction steps) leads to a monotonic ESSR improvement, though with diminishing increases in latency and token usage.
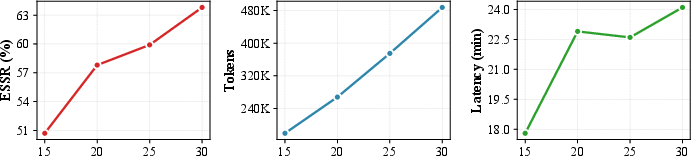
Figure 4: Performance across different execution steps as budget; ESSR increases with steps, at the expense of tokens and latency.
- Latency and Efficiency: Despite higher token usage, RAT maintains competitive execution latency, facilitating practical deployment.
- Model Backbone Sensitivity: The framework exhibits strong robustness: Under weaker backbones (Qwen3-Coder-30B), RAT still outperforms Repo2Run. With high-end LLMs (Claude 4.5 Sonnet, GPT-5.2), ESSR further scales up to 86.8%, illustrating backbone-agnostic architectural advantages.
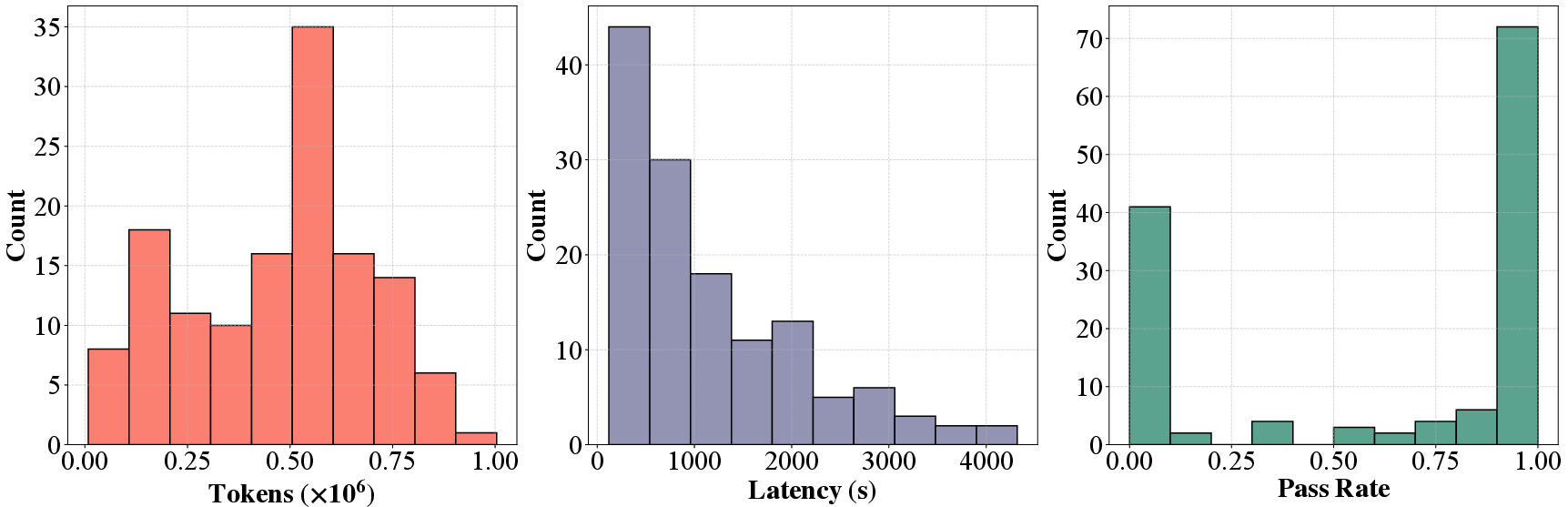
Figure 5: Distributions of tokens, latency, and pass rates across repositories.
- Comparison to Human Engineers: On representative Python repositories, RAT's ESSR surpasses that of senior human engineers (91.5% vs. 89.4%), though requiring approximately 2.25x more time—offset by full automation and horizontal scalability.
Failure analysis reveals that most unsolved configurations involve system-level dependencies (e.g., missing shared libraries, network/API constraints), external service unavailability, or hardware-bound requirements (e.g., CUDA). RAT's architecture provides partial remedies via error recovery tooling and version management but leaves multi-service orchestration and hardware handling for future extensions.
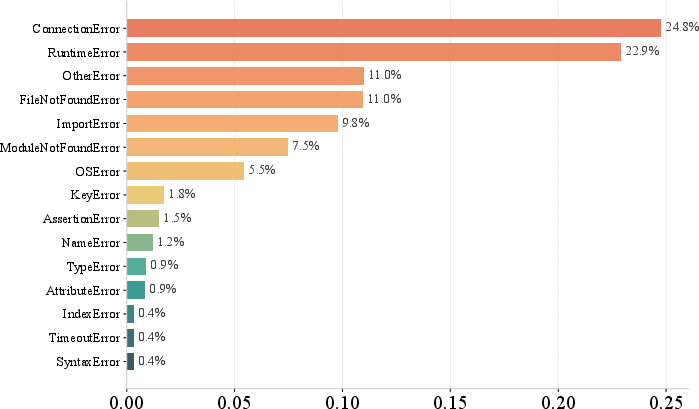
Figure 6: Breakdown of pytest error types for Python repositories where RAT fails to solve.
Trajectory studies demonstrate that RAT, unlike Repo2Run, strategically exploits repository CI/CD pipelines and auxiliary documentation, leading to more convergent, holistic configuration paths—especially salient on repositories requiring complex service dependencies.

Figure 7: Trajectory comparison between RAT and Repo2Run on a challenging repository.
Tool usage analytics further indicate that most operations are concentrated on file analysis and test synthesis, with error recovery tools invoked on demand, reflecting effective agentic modularization.
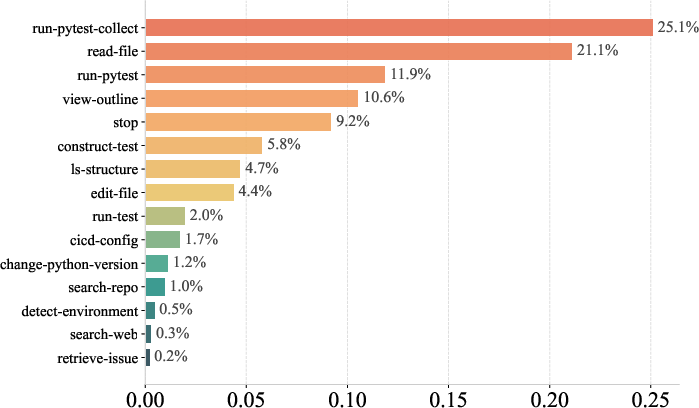
Figure 8: Tool calls distribution of RAT across Python repositories.
Limitations and Pathways for Future Research
RAT currently assumes single-container environments. It does not handle multi-service deployments (e.g., docker-compose orchestration), hardware-dependent environments (e.g., GPUs), or dynamic human-in-the-loop scenarios (e.g., API keys, credentials). Enriching agentic reasoning to encompass service orchestration, hardware integration, and interactive human input remains an open challenge, calling for advances in both LLM planning and OS-level virtualization interfaces.
Theoretical and Practical Implications
The demonstrated scaling law for ESSR and the superior generalization under diverse backbones suggest that agentic, tool-augmented planning can yield robust environment configuration even under severe information ambiguity. The approach scales data synthesis and executable trace acquisition for LLM RL training. Practically, RAT enables reliable and reproducible deployment automation at scale, mitigating the primary bottleneck in repository-level LLM evaluation and application.
Conclusion
RAT establishes a new state of the art in automated, language-agnostic environment configuration for software repositories. Through its modular and agentic design, semantically optimized base image selection, dual-mode planning, and comprehensive tooling, it sharply outperforms both traditional and LLM-centric baselines, approaching or surpassing human expert performance. The release of RATBench ensures fair, realistic, and scalable evaluation for future research. Extending RAT's capabilities to handle multi-service, hardware-aware, and interactively conditioned environments constitutes a promising direction for advancing fully autonomous software engineering agents.
Reference: "RAT: RunAnyThing via Fully Automated Environment Configuration" (2604.23190)