- The paper presents a unified model that jointly predicts depth, pose, and intrinsics from web videos using self-supervised learning.
- It leverages a multi-view signal proxy and curriculum learning to stabilize training across diverse, uncurated video data.
- Expert distillation consolidates domain-specific predictions into a single model, enabling robust zero-shot and fine-tuned performance.
End-to-End Self-Supervised 3D Estimation from Web Videos: An Expert Review of SS3D
Introduction and Motivation
SS3D ("End2End Self-Supervised 3D from Web Videos" (2604.22686)) introduces a unified, web-scale self-supervised 3D estimation pipeline that learns to predict depth, pose, and camera intrinsics from monocular video. The work targets the longstanding bottleneck of requiring curated, annotated datasets with ground-truth 3D geometry, which plagues existing 3D/4D foundation models. SS3D instead leverages large-scale web video data, operationalizing a Structure-from-Motion (SfM) self-supervision paradigm. The approach is characterized by the end-to-end prediction of all relevant 3D cues from a shared model, advanced training stabilization strategies (addressing both scale and domain heterogeneity), and cross-domain generalization capabilities.
System Overview and Core Contributions
At a high level, SS3D consists of three interlocking components: a unified feed-forward model estimating depth, pose, and intrinsics; a web-scale stabilization framework using a multi-view signal proxy (MVS) and a curriculum learning strategy; and a domain-expert distillation methodology that consolidates knowledge from sub-domain experts into a single, deployable student model.
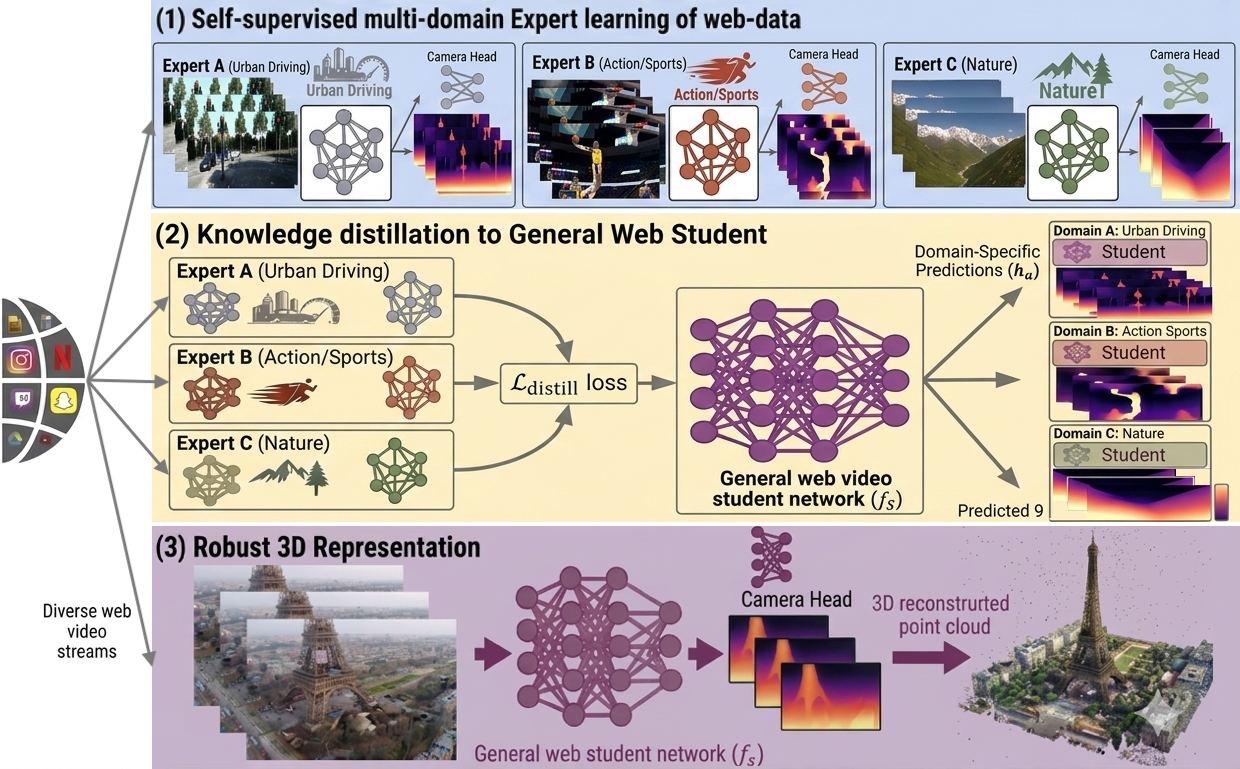
Figure 1: SS3D pipeline: (1) train self-supervised, sub-domain experts on multi-domain web video, (2) distill expert predictions into a student model, (3) at inference, the student predicts depth, pose, and intrinsics for 3D reconstruction.
The principal innovations are:
- Unified 3D Estimation: SS3D trains a single transformer-based network to predict depth, pose, and camera intrinsics jointly, evaluated from a single checkpoint. A two-stage intrinsics-first schedule stabilizes optimization, yielding coherent end-to-end 3D estimators.
- Web-Scale Self-Supervision: Training on unconstrained web videos exposes models to weak geometric cues and semantic heterogeneity. SS3D introduces a Multi-View Signal (MVS) proxy—measuring inter-frame parallax via the ratio of epipolar and homographic errors—to filter and curriculum-sample the corpus, ensuring robust geometric supervision.
- Expert Distillation for Heterogeneity: The mixture of highly diverse domains is addressed by partitioning the corpus into homogeneous sub-domains, training domain-specific expert models, and distilling their predictions (via a scale/shift-invariant loss) into a single student model. This approach mitigates gradient incoherence and enforces domain-agnostic generalization.
Technical Approach
Self-Supervised Multi-Task Learning
Given N consecutive RGB frames {Ii}i=1N, the model predicts per-frame depth Di, pose Ti, and intrinsics Ki. Depth and pose are formulated in classic SfM style, with geometry enforced via differentiable view synthesis (pixel warping via predicted depths and egomotion). The photometric self-supervision objective is robustified via Charbonnier and SSIM penalties (i.e. ρ function), and training applies all possible ordered pairs within each temporal clip for maximum 3D consistency.
The camera intrinsics are predicted per frame under a pinhole model with centered principal point, but the parameters are fixed within each clip for stability. The two-stage optimization involves first updating depth and pose with fixed intrinsics, then freezing intrinsics while optimizing the remaining parameters. All three predictions are obtained via a transformer backbone, yielding fully joint, checkpoint-consistent outputs.
Curriculum Learning via Multi-View Signal Proxy
Web videos often lack sufficient inter-frame translation (parallax), leading to degenerate or misleading geometric supervision when using photometric objectives. SS3D computes a per-video MVS score, Pt,t+1, quantifying the relative explanatory power of epipolar and planar models over matched keypoints. Training begins on a high-MVS subset (high parallax), with the curriculum gradually incorporating lower-MVS (more ambiguous) samples as optimization proceeds. This helps avoid early collapse and ensures high-quality geometric signals.
Expert Distillation and Corpus Clustering
To further counteract domain heterogeneity, the web video corpus is clustered into K sub-domains (empirically, K=5 performs well), partitioned via k-means in CLIP embedding space. Experts are trained per sub-domain; these are then distilled into a student network via soft distillation losses applied to depth, translation, rotation, and intrinsics predictions (invariant under global scale/shift). At inference time, only the student model is deployed.
Experimental Evaluation
Extensive benchmarking is performed across KITTI (outdoor) and NYUv2 (indoor) for depth, Sintel and TUM-RGBD for pose, and synthetic benchmarks for intrinsic parameter estimation. The evaluation uses both zero-shot (direct transfer without target domain exposure) and fine-tuned protocols.
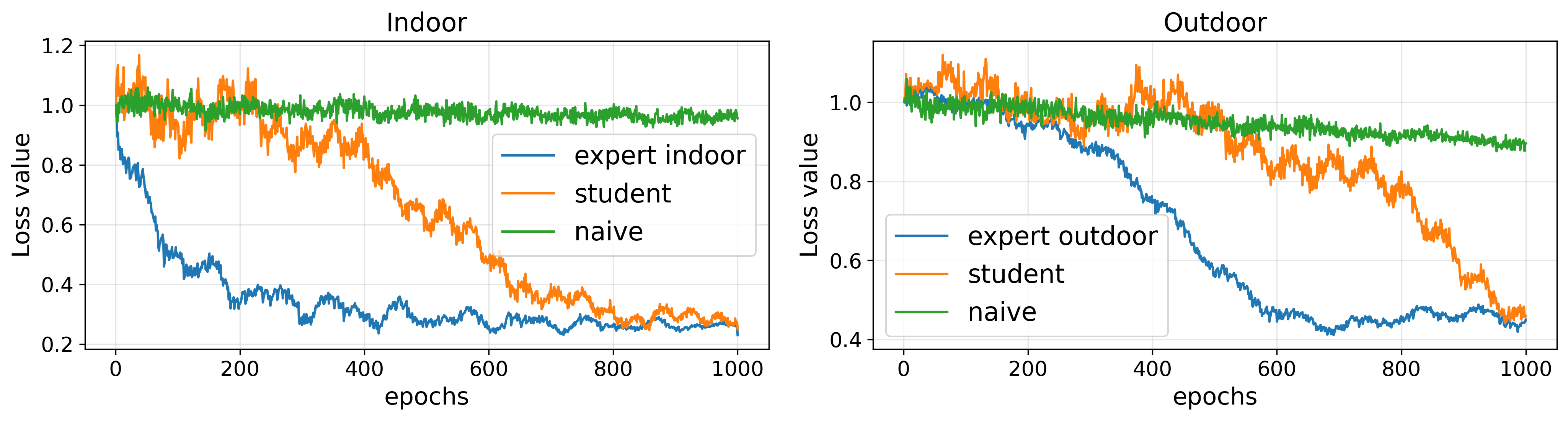
Figure 2: Training dynamics comparing naive large-scale training (blue) and SS3D’s expert-distilled, curriculum-stabilized approach (green) for indoor and outdoor domains.
Ablation studies reveal that both MVS-based curriculum and expert distillation are strictly necessary for stable training and strong zero-shot transfer—naive web-scale mixing fails to realize substantive gains and causes optimization instability. Efficacy increases monotonically as components are added (see main text Table 1).
On KITTI, SS3D achieves an Abs Rel of 0.092 (zero-shot) and 0.064 (fine-tuned), matching or exceeding prior self-supervised methods and approaching fully supervised methods. Comparable trends are observed on NYUv2, with strong cross-domain adaptability. Pose estimation metrics (e.g., ATE, RPE) are competitive with specialized models such as AnyCam, and focal length error for predicted intrinsics approaches supervised baselines.
Qualitative analyses support these findings, showing visually sharp, geometry-consistent depth maps and reconstructions, even in the presence of domain shift.









Figure 3: Qualitative results on KITTI after fine-tuning: input image, induced 3D point cloud, and predicted depth.
Implications and Future Directions
SS3D's results demonstrate that web-scale, uncurated video—when filtered and organized appropriately—can act as a potent supervision signal for learning generalizable 3D priors. The avoidance of any explicit 3D ground-truth or camera calibration is significant: it obviates the need for expensive data collection infrastructure and reduces the dependence on synthetic or hand-annotated benchmarks.
Practical implications include:
- Foundational 3D Models: SS3D provides a scalable template for 3D-centric foundation models capable of zero-shot deployment and rapid fine-tuning, laying groundwork for wide application in robotics, AR/VR, and autonomous navigation.
- Self-Supervision at Web Scale: The stabilization techniques developed for handling low-parallax and domain heterogeneity are generalizable and could influence other self-supervised video learning paradigms, especially those relying on weak geometric or physical signals.
- Unified Perception Stacks: By decoupling 3D understanding from the need for multi-network pipelines, SS3D suggests a transition toward joint, checkpoint-consistent estimators for perception systems beyond depth, encompassing motion, intrinsics, and in principle, semantics.
For future work, further improvement is possible through tighter integration with semantic or temporal cues (e.g., combining with vision-language pretraining), better handling of dynamic object motion, and leveraging higher capacity or hierarchical architectures. Scaling to additional modalities (e.g., event data, LiDAR-augmented bootstrapping) and more granular domain adaptation protocols also present fertile directions.
Conclusion
SS3D establishes a novel paradigm for unified, self-supervised 3D estimation at web scale. The approach demonstrates that, given robust observability-based filtering and expert-based distillation, it is feasible to deliver high-accuracy, generalizable depth, pose, and intrinsics prediction from monocular video alone, without any 3D ground-truth. The empirical performance supports strong claims on both zero-shot transfer and specialization via fine-tuning, validating the curriculum and distillation strategies. This fundamentally shifts scalable 3D learning toward data-centric methodologies and opens new pathways for foundation models in geometric computer vision.