Learning to Drive is a Free Gift: Large-Scale Label-Free Autonomy Pretraining from Unposed In-The-Wild Videos
Abstract: Ego-centric driving videos available online provide an abundant source of visual data for autonomous driving, yet their lack of annotations makes it difficult to learn representations that capture both semantic structure and 3D geometry. Recent advances in large feedforward spatial models demonstrate that point maps and ego-motion can be inferred in a single forward pass, suggesting a promising direction for scalable driving perception. We therefore propose a label-free, teacher-guided framework for learning autonomous driving representations directly from unposed videos. Unlike prior self-supervised approaches that focus primarily on frame-to-frame consistency, we posit that safe and reactive driving depends critically on temporal context. To this end, we leverage a feedforward architecture equipped with a lightweight autoregressive module, trained using multi-modal supervisory signals that guide the model to jointly predict current and future point maps, camera poses, semantic segmentation, and motion masks. Multi-modal teachers provide sequence-level pseudo-supervision, enabling LFG to learn a unified pseudo-4D representation from raw YouTube videos without poses, labels, or LiDAR. The resulting encoder not only transfers effectively to downstream autonomous driving planning on the NAVSIM benchmark, surpassing multi-camera and LiDAR baselines with only a single monocular camera, but also yields strong performance when evaluated on a range of semantic, geometric, and qualitative motion prediction tasks. These geometry and motion-aware features position LFG as a compelling video-centric foundation model for autonomous driving.
























Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper shows a new way to teach a computer to understand driving scenes just by watching lots of regular driving videos from the internet. The method is called LFG, short for “Learning to drive is a Free Gift.” Without using special sensors (like LiDAR) or human-made labels, LFG learns to:
- understand what’s in the scene (roads, cars, people, buildings)
- build a 3D map of the scene
- figure out where the camera (the car) is moving
- spot which things are moving (like other cars and pedestrians)
- predict what the scene will look like a few moments into the future
The big idea is to make use of the huge amount of unlabeled dashcam-style videos online to pretrain a strong “video brain” for self-driving.
Key Questions
To keep things simple, the researchers wanted to answer:
- Can a model learn useful driving skills from unlabeled videos alone?
- Can it understand 3D structure and motion using only a single camera view?
- Can it predict the very near future (the next few frames) to help with safe planning?
- Will this kind of pretraining help real driving tasks, like choosing a safe path?
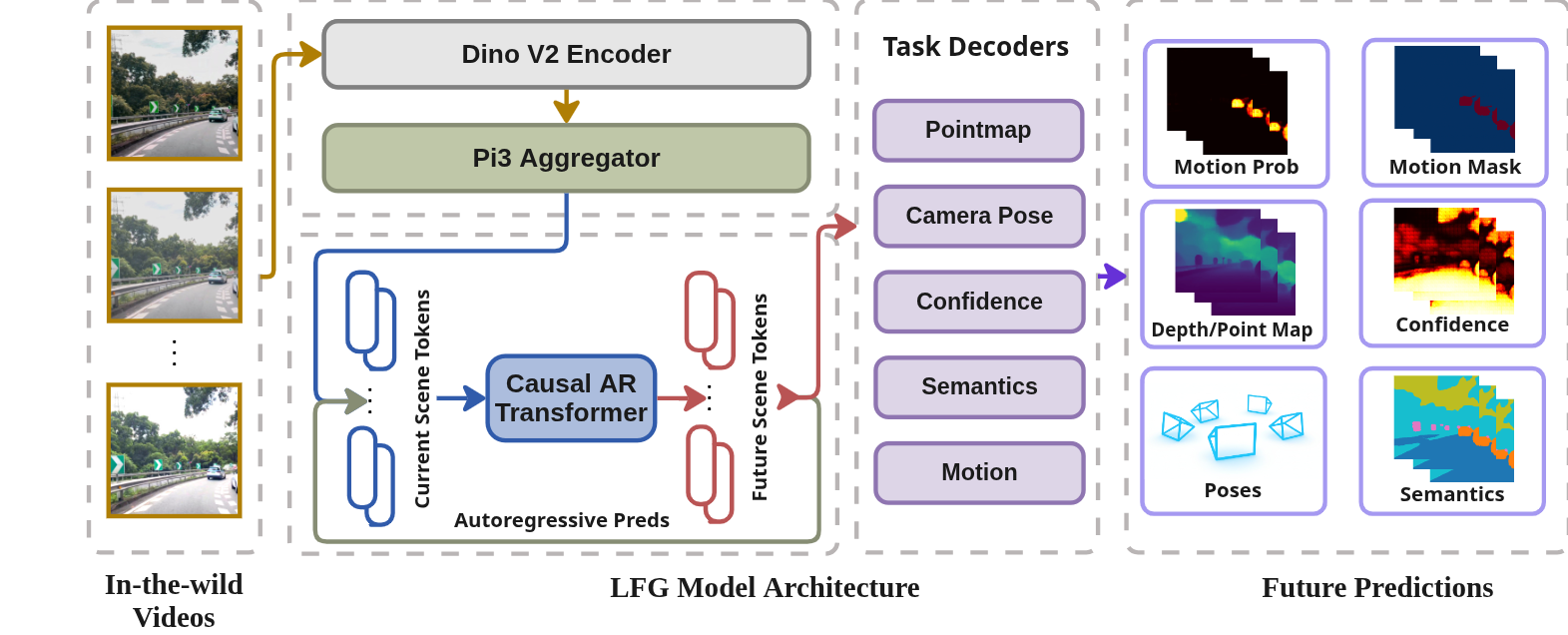
How LFG Works (Methods in everyday language)
Think of LFG like a student learning from multiple expert coaches (teachers), but only by watching videos:
- Single-camera input: The model watches a short video clip from a front-facing camera, like a dashcam.
- What it tries to predict:
- 3D point map: For each pixel, “where is that point in the real world?” Imagine coloring every pixel with its 3D location—this becomes a point cloud of the scene.
- Camera pose: Where the camera is and the direction it’s pointing. This is like knowing the car’s position and heading.
- Semantic segmentation: Labeling each pixel as road, car, person, building, sky, etc. Think of it as coloring the scene with meaningful categories.
- Confidence map: How sure the model is about each prediction (high confidence vs. low confidence).
- Motion mask: Highlighting which pixels belong to moving objects (other cars, people), not just the static background.
- Short-horizon future: It doesn’t stop at the current frame; it also guesses what the next few frames will look like.
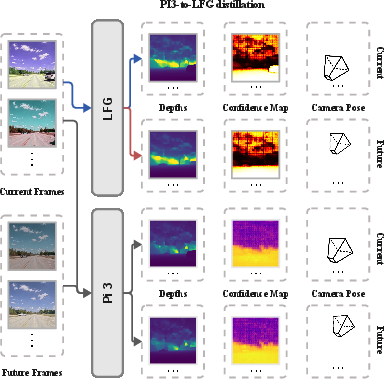
- Teacher–student training:
- Teachers are existing models that are good at specific tasks:
- A geometry teacher (called π³) provides 3D points and camera movement.
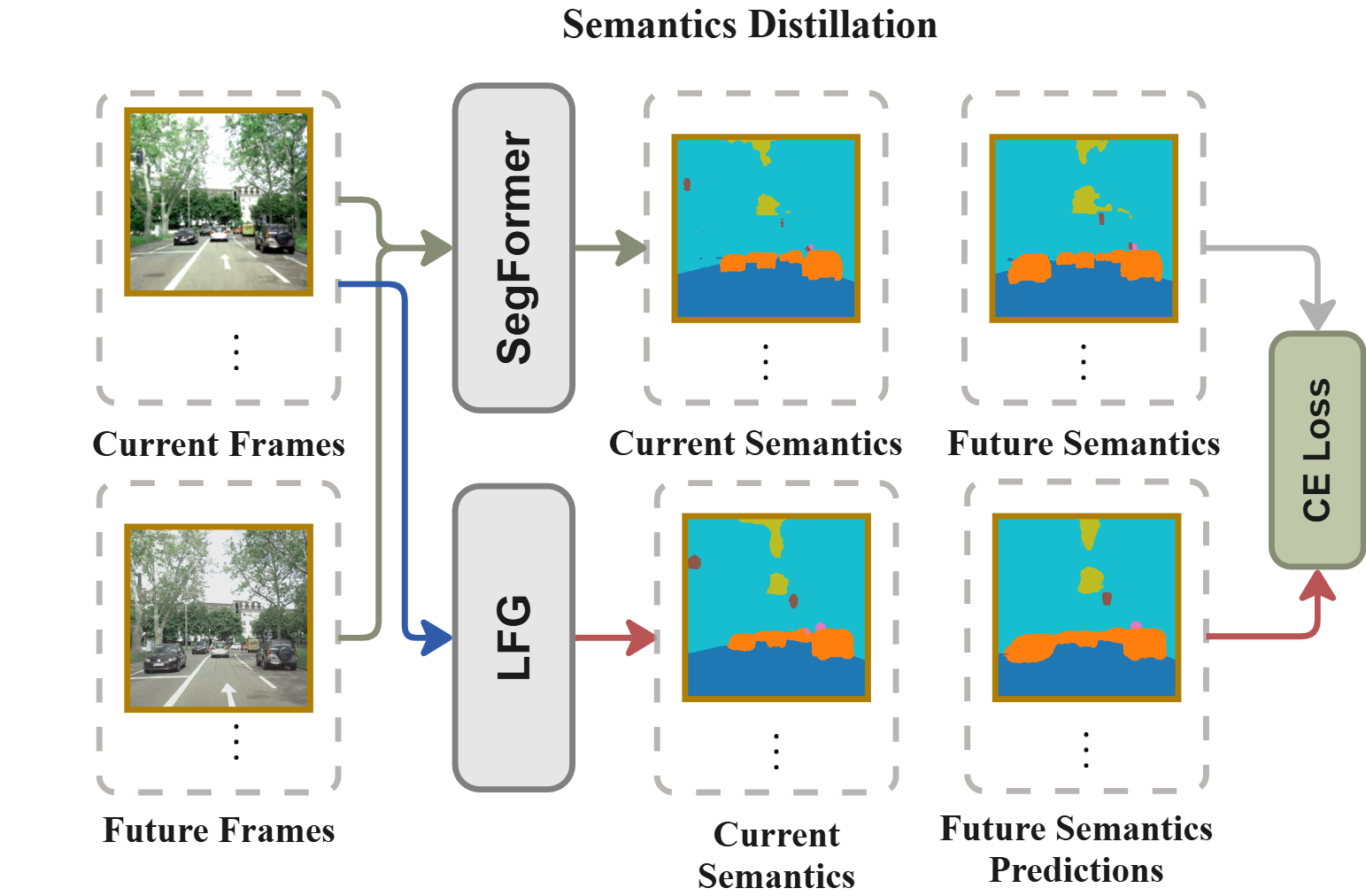
- A segmentation teacher (SegFormer) provides scene labels like road/car/person.
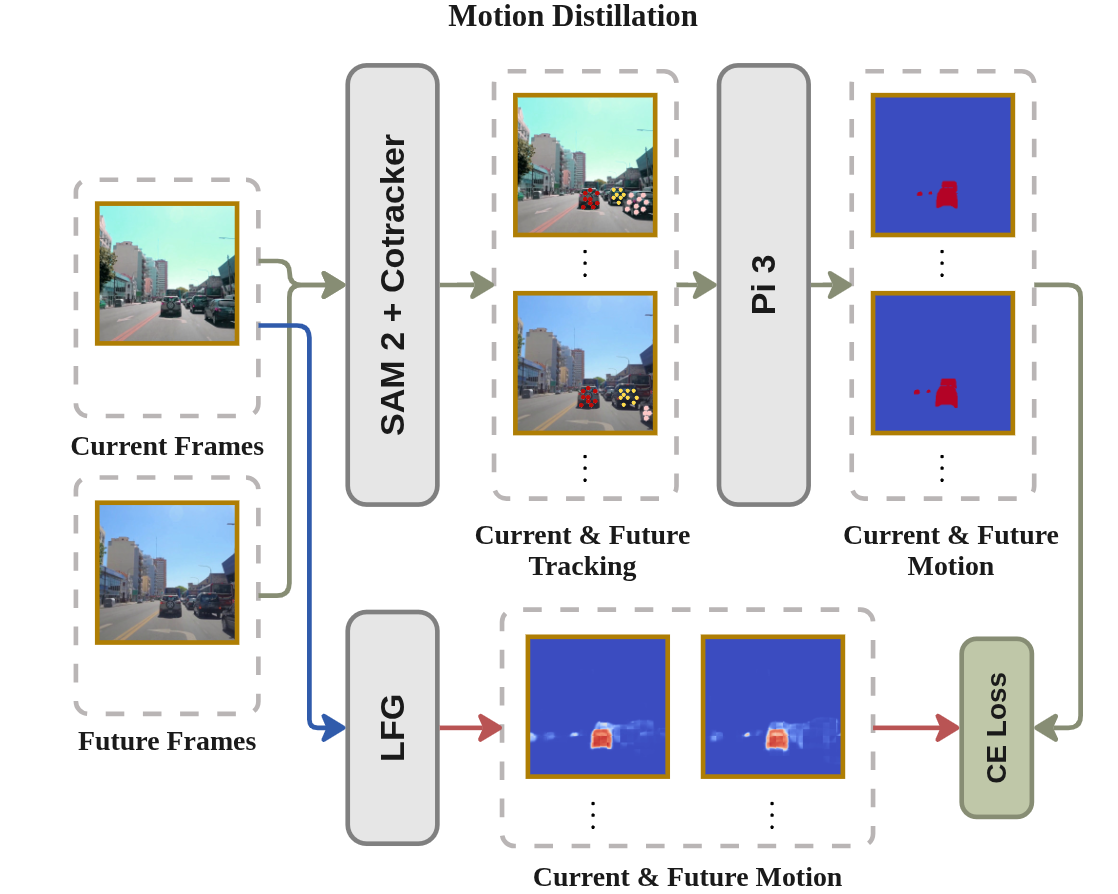
- Motion teachers (SAM2 and CoTracker3) help identify moving objects by tracking them across frames.
- The teachers see the whole video clip and produce “pseudo-labels” (automatic hints). The student (LFG) only sees the first part and has to predict the rest. This teaches LFG to think ahead.
- Architecture in simple terms:
- A fast “encoder” first turns the video frames into meaningful tokens (compact features).
- A lightweight “future predictor” (an autoregressive transformer) then rolls the scene forward, like guessing the next sentence in a story, but for video frames.
- A shared decoder turns these tokens into the outputs: 3D maps, poses, labels, confidence, and motion masks.
- Why this is clever:
- No human labels are needed.
- It uses just a single camera view.
- It learns to predict the near future, which is essential for safe driving decisions.
Where the training data comes from
Millions of in-the-wild (internet) driving videos with no labels. These videos are varied—different roads, weather, and traffic—so the model learns to handle lots of situations.
What “unposed” means
“Unposed” means the videos do not come with camera position information. The model has to figure out where the camera is and how it moves just from the pixels.
Analogy for the future predictor
The future predictor is like finishing a comic strip when you only see the first few panels. It uses what it learned to guess the next panels, including which characters move and where the scene goes.
Main Findings and Why They Matter
Here are the main takeaways, explained simply:
- Strong planning with just one camera:
- On a driving benchmark called NAVSIM, LFG used only a single front camera and still beat or matched methods that use multiple cameras and LiDAR. That’s impressive because LiDAR is an expensive sensor.
- Data efficiency:
- After pretraining on unlabeled videos, LFG needs far fewer labeled examples to perform well. With just 10% of labeled data, it reaches performance similar to models trained on full labeled data. This saves time and money.
- Good at multiple tasks:
- LFG doesn’t just plan. It also does well at:
- Semantic segmentation (labeling the scene)
- 3D geometry (depth and point maps)
- Short-term motion prediction (spotting moving objects)
- This means LFG’s features are useful across different driving problems.
- Future-aware:
- The model predicts what happens next in the scene briefly into the future, which is exactly the kind of context a car needs to be safe and reactive.
Implications and Potential Impact
- Cheaper training, broader coverage:
- Using unlabeled internet videos means we can train on huge amounts of data without hiring people to label everything. This could speed up progress in self-driving while lowering costs.
- Less reliance on expensive sensors:
- Because LFG works with just a single camera, it could make autonomous systems more affordable and easier to deploy.
- A strong foundation for many tasks:
- LFG acts like a video-centric “foundation model” for driving. You can fine-tune it for planning, detection, mapping, or motion forecasting, making it a flexible base for future systems.
- Better safety through anticipation:
- Understanding short-term future motion helps cars be more cautious and react quickly—important for preventing accidents.
In short, LFG shows that “learning to drive” can come as a free gift from the internet’s massive supply of driving videos. By predicting 3D structure, semantics, and near-future motion from a single camera, it sets a promising path toward scalable, cost-effective, and safer autonomy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that the paper leaves unresolved, aimed to guide follow-up research:
- Teacher dependence and “label-free” claim: The approach relies on teachers trained with labeled data (SegFormer on Cityscapes; Grounded SAM2; CoTracker3), so it is not fully label-free. Quantify how much each teacher contributes to performance, and evaluate alternatives that avoid labeled pretraining or use self-supervised teachers.
- Domain mismatch in semantic supervision: SegFormer is trained on Cityscapes (European urban scenes) while pretraining uses in-the-wild YouTube videos. Measure domain shift effects and test teachers trained on broader or unlabeled corpora; evaluate on diverse geographies and conditions.
- Potential future information leakage in pseudo-labels: Teachers see the full sequence while the student sees only the first N frames. Run causal-teacher controls (teachers restricted to ≤ t frames) to ensure no leakage biases the supervision, especially for “future” semantics and geometry.
- Pseudo-motion labeling limitations: Motion pseudo-labels are generated from first-frame instance detection and tracking of only vehicles/humans, with thresholds (τ_motion, K_min). Assess sensitivity to these heuristics, extend to more classes (e.g., cyclists, motorbikes), handle late-appearing objects, occlusions, and background motion, and provide quantitative motion GT evaluation.
- Binary motion masks only: The motion head predicts binary masks, not per-pixel flow, instance-level trajectories, or 3D velocities. Investigate richer motion representations (vector fields, instance kinematics, uncertainty over motion) and their impact on planning.
- Short prediction horizon and drift: The autoregressive module handles only a short horizon M. Analyze how horizon length affects performance, error accumulation, and temporal drift; explore mechanisms (e.g., closed-loop rollouts, scheduled sampling) to mitigate exposure bias.
- Scale ambiguity and metric accuracy: Depth evaluation uses scale/shift alignment; absolute metric scale is not guaranteed. Examine methods to recover or stabilize metric scale (e.g., weak priors, self-calibration, sparse GPS), and quantify absolute depth/pose accuracy over longer sequences.
- Confidence calibration: Confidence supervision is thresholded from point error, but calibration is not evaluated. Measure and improve calibration (e.g., ECE, selective risk, proper scoring rules) and propagate uncertainty into planning.
- Intrinsics, stabilization, and compression in YouTube videos: The method assumes unposed, single-view data but does not analyze robustness to unknown intrinsics, rolling shutter, stabilization, or compression artifacts. Provide ablations and intrinsics-estimation strategies.
- Frame-rate variability: Training uses 2/5/10 Hz without conditioning; no analysis of generalization to unseen frame rates. Test time-conditioned architectures or continuous-time models and report sensitivity.
- Single monocular view only: The method is not evaluated for multi-camera, 360° coverage, or sensor fusion. Extend LFG pretraining to multi-view and assess benefits relative to BEV-centric methods under the same unlabeled-data scale.
- Compute and real-time constraints: The 1.45B model runs at ~5 Hz on an RTX 5090, below typical AD real-time requirements. Study compression/distillation, token pruning, and latency-throughput trade-offs for deployment on automotive hardware.
- Frozen geometry heads ambiguity: The paper states point/confidence/pose heads are frozen in implementation, potentially limiting adaptation to unlabeled driving videos. Clarify and ablate freezing vs. fine-tuning of these heads.
- Long-range mapping and loop closure: The model operates on short clips; global consistency and loop-closure performance are not studied. Evaluate over longer trajectories, measure drift, and integrate global constraints.
- Planning evaluation scope: Results are limited to NAVSIM PDMS, with no closed-loop simulation or real-world testing. Provide closed-loop metrics, intervention rates, and robustness under rare events, adverse weather, and heavy traffic.
- Fairness of comparisons and data scale: LFG benefits from large-scale unlabeled pretraining; several baselines may not. Normalize pretraining scale across methods, report variance over seeds, and include stronger BEV pretraining baselines under identical unlabeled data.
- Limited semantic taxonomy: Only 7 classes (no traffic lights/signs, lane markings, cyclists, motorcycles). Expand taxonomy and test impact on planning and safety-critical behaviors.
- Lack of quantitative motion benchmarks: Motion evaluation is largely qualitative with pseudo-GT. Add quantitative evaluations against datasets with ground-truth motion/flow/instance dynamics.
- Rare/long-tail scenarios: No explicit stress testing (e.g., emergency vehicles, construction zones, unusual maneuvers). Curate and evaluate on long-tail benchmarks; analyze failure modes and data coverage needed.
- Integration of uncertainty into planning: Although LFG predicts confidence, downstream planning does not leverage uncertainty. Investigate uncertainty-aware decoding, risk-sensitive objectives, and safety constraints.
- Teacher quality ablations: No systematic study of replacing or degrading teachers (e.g., different geometry or segmentation backbones) to assess robustness to teacher errors and biases.
- Sensitivity to hyperparameters: Thresholds (τ_motion, K_min), future-frame weighting (ω), and loss weights lack sensitivity analysis. Provide systematic ablations to guide stable training.
- Legal/ethical/PII considerations: Using YouTube videos raises licensing and privacy issues (faces/plates). Document data governance, anonymization, and compliance practices.
- Path to full autonomy stack: LFG is a perception- and short-horizon prediction-focused foundation. Explore coupling with forecasting (instance-level), map priors, and control modules; evaluate end-to-end closed-loop performance.
Practical Applications
Immediate Applications
These applications can be prototyped or deployed with the paper’s current methods and demonstrated performance, particularly the LFG encoder’s ability to learn geometry-, motion-, and semantics-aware features from unlabeled, single-view driving videos and its strong transfer to planning (e.g., NAVSIM, single-camera, low-label regimes).
- Single-camera planning and perception for autonomy (Automotive, Robotics)
- Use LFG as a drop-in, pretrained video-centric backbone to power trajectory planning from just a front-facing monocular camera, reducing sensor costs and label requirements while retaining strong performance (e.g., PDMS gains and low-label efficiency reported).
- Potential tools/products/workflows: “Pretrain-to-plan” SDK that ingests video, runs LFG to produce autonomy tokens and short-horizon future predictions, and feeds a lightweight anchor-based trajectory decoder; ROS2 nodes publishing point maps, poses, semantics, motion masks; deployment on RTX-class edge GPUs.
- Assumptions/dependencies: Access to large unlabeled fleet/dashcam video; GPU capacity (LFG ~1.45B params, 5 Hz on RTX 5090); safety validation and redundancy for production; domain coverage for camera intrinsics and conditions.
- Automated dataset enrichment and label cost reduction (Software/ML Ops, Academia)
- Use LFG outputs to auto-label or pseudo-label existing datasets with point maps, poses, motion masks, and semantic maps, accelerating curation of training corpora and enabling human-in-the-loop QA for critical classes (e.g., road users).
- Potential tools/products/workflows: Batch inference pipeline with confidence maps to triage frames; labeling UIs that overlay LFG predictions; data governance policies for pseudo-label acceptance thresholds.
- Assumptions/dependencies: Quality control on pseudo-labels; teacher ensemble availability (SegFormer, SAM2, CoTracker3, π3); procedures to handle pseudo-GT failure cases highlighted in the paper.
- Traffic analytics from CCTV/dashcam streams (Public Sector/Smart Cities)
- Deploy LFG to extract per-pixel motion masks and short-horizon trajectories for traffic flow estimation, near-miss detection, and hazard forecasting using existing monocular infrastructure.
- Potential tools/products/workflows: City-scale dashboards that compute TTC, dynamic-agent heatmaps, and incident flags from motion-aware features; batch processing of historical feeds for “near-miss” safety programs.
- Assumptions/dependencies: Camera viewpoint variability; calibration-free operation is feasible, but performance depends on distributional similarity to training videos; privacy and data retention compliance.
- Fleet safety and insurance risk scoring (Finance, Logistics)
- Leverage LFG’s motion and future geometry predictions to compute risk indicators (e.g., short-horizon TTC, dynamic-object proximity) from dashcam footage for driver coaching and claims triage.
- Potential tools/products/workflows: Telemetry pipelines combining dashcam video with LFG motion masks to score events; automated incident summaries with confidence-weighted evidence.
- Assumptions/dependencies: Regulatory approval for driver monitoring; acceptable latency with available edge hardware; mitigation of pseudo-label errors via confidence maps.
- Simulation scenario generation and augmentation (Software/Simulation)
- Convert unlabeled in-the-wild videos into pseudo-4D scenes (geometry + semantics + motion) and short-horizon futures to seed simulation scenarios, diversify training distributions, and augment planners without hand-labeling.
- Potential tools/products/workflows: NAVSIM-compatible scenario exporters; dynamic 4D Gaussian splatting assets derived from LFG; automatic trajectory anchor initialization.
- Assumptions/dependencies: Sufficient geometric fidelity for downstream simulators; workflows to validate realism and remove artifacts.
- Low-cost mobile robots in structured environments (Robotics/Warehouse/Industrial)
- Use LFG’s monocular, motion-aware perception to bootstrap navigation for forklifts, floor cleaners, or delivery carts where LiDAR is cost-prohibitive.
- Potential tools/products/workflows: Edge inference stack streaming per-frame semantics and motion masks to local planners; confidence-gated maneuvering policies in structured indoor/outdoor spaces.
- Assumptions/dependencies: Domain adaptation from driving to indoor or mixed environments; short-horizon planning sufficiency; fallback sensors for occlusion and edge cases.
- Academic course labs and benchmarks on label-free video pretraining (Academia/Education)
- Integrate LFG into coursework and research to study geometry-motion representations learned from unlabeled data; reproduce NAVSIM and depth/segmentation experiments; compare teacher ensembles and autoregressive horizons.
- Potential tools/products/workflows: Modular training scripts; teacher-student ablation notebooks; reproducible benchmark suites with PDMS and related metrics.
- Assumptions/dependencies: Compute access (multi-GPU training noted); rights to use public video datasets (OpenDV/YouTube) for educational purposes.
- Visual digital twins and VFX pre-visualization from consumer video (Media/Entertainment)
- Generate pseudo-4D reconstructions from handheld or vehicle-mounted footage to prototype scenes with dynamic agents for visualization or pre-viz.
- Potential tools/products/workflows: Tools that export LFG point maps and motion masks into 3D engines; quick-turn scene blocking based on short-horizon predictions.
- Assumptions/dependencies: Acceptable geometric accuracy; camera motion stability; non-driving scenes may require adaptation.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or regulatory approvals. They build on LFG’s core innovations—label-free, single-camera pretraining; unified geometry/semantics/motion; short-horizon autoregressive prediction.
- Production-grade monocular autonomous driving (Automotive)
- Transition from prototypes to safety-certified, monocular-first autonomy stacks that leverage LFG for perception and planning in diverse conditions, potentially reducing dependency on multi-camera/LiDAR.
- Potential tools/products/workflows: End-to-end validated pipelines with redundancy (e.g., radar fallback), rigorous safety-case documentation, dataset expansion for rare events, continuous monitoring via confidence maps.
- Assumptions/dependencies: Robustness under adverse weather/night; regulatory approvals; comprehensive validation beyond NAVSIM; runtime optimization for automotive-grade hardware.
- Map-less navigation and generalization to unseen geographies (Automotive/Robotics)
- Use LFG’s short-horizon, geometry-aware predictions to navigate without HD maps, relying on video-centric features and ego-motion for local planning and localization.
- Potential tools/products/workflows: Visual odometry integration; dynamic occupancy prediction; local map-on-the-fly built from point maps and motion.
- Assumptions/dependencies: Strong domain generalization; robust pose estimation amid sensor noise and occlusions; multi-agent interaction modeling.
- Foundation model for general mobile robotics and aerial platforms (Robotics/Drones)
- Adapt LFG to drones, delivery robots, and micromobility by retuning teachers, expanding datasets, and extending the autoregressive horizon for agile maneuvers.
- Potential tools/products/workflows: Cross-domain teacher ensembles; sim-to-real transfer toolchains; domain-specific motion heads (e.g., aerial dynamics).
- Assumptions/dependencies: Significant domain shift (altitude, viewpoint, dynamics); additional sensors for safety; environment diversity in pretraining corpora.
- Continual self-training on fleet video (Software/ML Ops)
- Create a closed-loop system that ingests fleet dashcam video, updates the foundation model via pseudo-label teachers, and incrementally improves planning while maintaining safety gates.
- Potential tools/products/workflows: Data pipelines with quality/novelty scoring; teacher orchestration and versioning; confidence-aware deployment and rollback.
- Assumptions/dependencies: Scalable infrastructure; robust detection of pseudo-label drift; stringent rollout criteria.
- Consumer-grade ADAS via dashcam or smartphone (Consumer Electronics/Automotive)
- Offer lane-keeping, collision warnings, or hazard anticipation on commodity cameras and mobile devices using LFG-derived features.
- Potential tools/products/workflows: Mobile inference accelerators; on-device safety checkers; subscription apps connected to telematics dashboards.
- Assumptions/dependencies: Real-time performance on mobile SOCs; liability and regulatory compliance; calibration across diverse devices.
- Smart-city digital twins with predictive safety (Public Sector/Urban Planning)
- Maintain city-scale digital twins updated from monocular traffic cameras, forecasting near-term risks and informing adaptive signal control or emergency response.
- Potential tools/products/workflows: Integration with traffic management centers; APIs exposing motion-aware indicators; scenario planning tools using pseudo-4D reconstructions.
- Assumptions/dependencies: Access to camera networks; privacy-preserving analytics; validation of forecasts for policy decisions.
- Multi-agent behavior modeling and long-horizon planning (Autonomy Research)
- Extend LFG’s autoregressive module to predict intent and multi-agent interactions over longer horizons, feeding planners with richer uncertainty-aware futures.
- Potential tools/products/workflows: Probabilistic trajectory heads; uncertainty calibration; causal prediction modules blending geometry and semantics.
- Assumptions/dependencies: Additional supervision or weak labels for agent intent; computational scaling; careful evaluation to avoid overconfidence.
- Standards and governance for label-free pretraining (Policy/Standards)
- Develop guidelines for using public internet videos in safety-critical ML, covering consent, licensing, privacy, dataset bias auditing, and pseudo-label quality criteria.
- Potential tools/products/workflows: Auditing toolkits for teacher-student pipelines; standardized reporting of PDMS-like planning metrics; certification readiness checklists.
- Assumptions/dependencies: Multi-stakeholder coordination; legal frameworks for data use; mechanisms to detect and mitigate demographic and geographic biases.
- Energy and cost efficiency in autonomy stacks (Energy/Operations)
- Optimize feedforward, video-centric backbones to reduce inference compute and sensor costs across fleets, balancing training-time scale with inference-time savings.
- Potential tools/products/workflows: Model compression and distillation of LFG; hardware-aware architectures; cost dashboards quantifying sensor, label, and compute trade-offs.
- Assumptions/dependencies: Effective compression without degrading safety; thorough measurement of operational savings vs. training costs.
- Integrated “LFG pretrain-to-plan” product suite (Software/Platform)
- A full-stack platform from video ingestion, teacher-guided pretraining, pseudo-4D feature extraction, to planning fine-tuning and deployment monitoring.
- Potential tools/products/workflows: Teacher ensemble manager; horizon and modality toggles (geometry/semantics/motion); simulation bridges (NAVSIM and beyond); observability with confidence and failure-mode analytics.
- Assumptions/dependencies: Ongoing roadmap investment; cross-org buy-in; compliance and safety engineering embedded throughout.
Glossary
- 3D Gaussian Splatting: A fast differentiable rendering technique that models scenes with Gaussian primitives for efficient view synthesis or reconstruction. Example: "by leveraging efficient 3D Gaussian Splatting and a multi-frame photometric consistency objective"
- Absolute relative depth error (AbsRel): A depth metric measuring the average relative difference between predicted and ground-truth depths. Example: "and absolute relative depth error."
- Absolute Trajectory Error (ATE): A standard metric that quantifies the difference between predicted and ground-truth trajectories after alignment. Example: "We report Absolute Trajectory Error (ATE), rotation error (Rot), and translation error (Trans)."
- AdamW: An optimizer that decouples weight decay from the gradient-based update for better regularization. Example: "We train the model using the AdamW optimizer"
- Alternating attention: An attention scheme that alternates across dimensions or groups (e.g., spatial/temporal) in a transformer-like encoder. Example: "after 's alternating attention module or encoder."
- Amortized reconstruction: Learning a feedforward model that predicts 3D structure and poses directly, instead of solving per-scene optimization. Example: "amortize reconstruction by predicting point maps, confidence maps, and camera poses for unposed image sequences in a single pass"
- Anchor-based trajectory decoder: A planning head that predicts multiple candidate trajectories relative to predefined anchors and selects among them. Example: "a lightweight multi-modal anchor-based trajectory decoder that directly predicts multiple candidate trajectories in a single forward pass"
- Autonomy tokens: High-dimensional latent features representing the driving scene and ego state for planning. Example: "outputs high-dimensional autonomy tokens that encode the ego vehicle's motion state and surrounding context."
- Autoregressive transformer: A transformer module that predicts future representations sequentially, conditioned on past tokens. Example: "A lightweight causal autoregressive transformer rolls out future tokens"
- Backprojection: Mapping image pixels and their depths back into 3D coordinates using camera intrinsics/poses. Example: "we backproject the tracked 2D points into 3D"
- BEV-based (bird’s-eye-view) methods: Approaches that operate in a top-down planar view of the scene for perception or planning. Example: "outperforming multi-view and BEV-based methods such as UniAD"
- BF16 (bfloat16): A reduced-precision floating-point format used to speed up training with minimal accuracy loss. Example: "mixed-precision training (BF16) is enabled."
- Binary cross-entropy (BCE): A loss function for binary classification or per-pixel binary targets. Example: "We use a weighted BCE loss for semantic segmentation"
- Causal attention: Attention mechanism that restricts information flow to past tokens to enforce temporal causality. Example: "add a causal attention autoregressive transformer"
- Cityscapes: A benchmark dataset for urban scene understanding and semantic segmentation. Example: "trained on the Cityscapes dataset"
- CoTracker3: A model that provides dense feature tracks/point correspondences across frames. Example: "CoTracker3 ... provides dense correspondences in image space"
- Cosine annealing: A learning-rate schedule that decays the rate following a cosine curve. Example: "we apply cosine annealing over the remaining training steps."
- DINOv2: A self-supervised vision backbone used for initialization in downstream tasks. Example: "The image encoder is initialized from a DINOv2-pretrained backbone"
- DINOv3: A large self-supervised vision model trained on Internet-scale data. Example: "and DINOv3 trained on massive unlabeled internet corpora"
- Ego-centric videos: First-person videos captured from the viewpoint of the agent/vehicle. Example: "In-the-wild, ego-centric driving videos"
- Ego-motion: The motion of the camera/vehicle itself between frames. Example: "point maps and ego-motion can be inferred in a single forward pass"
- Geodesic distance on SO(3): A rotation error metric measuring the shortest angle between two rotations on the 3D rotation group. Example: "The rotation term penalizes geodesic distance on between predicted and target relative rotations"
- Grounded SAM2: A segmentation tool that combines grounding and segment-anything capabilities to obtain object masks. Example: "by using an off-the-shelf segmentation model, Grounded SAM2"
- Homogeneous transformation matrix: A 4×4 matrix representing rotation and translation in a single linear operator. Example: "a full 4 × 4 homogeneous transformation matrix"
- Huber loss: A robust regression loss less sensitive to outliers than L2. Example: "uses a robust regression loss (Huber) on relative translations"
- LiDAR: A sensor that measures distances using laser light to produce 3D point clouds. Example: "which rely on multiple cameras, LiDAR, or both."
- Motion masks: Per-pixel predictions indicating dynamically moving regions versus static background. Example: "Finally, our model should predict motion masks"
- Multi-View Stereo (MVS): A 3D reconstruction method that builds dense geometry from multiple images with known poses. Example: "Structure-from-Motion (SfM) and Multi-View Stereo (MVS)"
- NAVSIM: A planning benchmark for evaluating autonomous driving policies. Example: "On the NAVSIM planning benchmark"
- Odometry: Estimation of the vehicle’s motion (position and orientation) over time using onboard sensors. Example: "LiDAR scans, odometry, and semantic annotations."
- OpenDV: A large-scale unlabeled driving video dataset used for pretraining. Example: "from the unlabeled OpenDV dataset"
- Photometric consistency: A self-supervision signal enforcing color/appearance consistency across views/frames. Example: "a multi-frame photometric consistency objective"
- Point map: A per-pixel 3D world point representation associated with an image. Example: "First, our model should predict point maps for the ego-view camera over time."
- Pseudo-4D: A unified representation capturing 3D scene structure over time (i.e., 3D + temporal). Example: "learns a unified pseudo-4D representation of geometry, semantics, motion, and short-term future evolution"
- Pseudo ground-truth (pseudo-GT): Automatically generated supervisory labels used when human annotations are unavailable. Example: "we generate pseudo ground-truth (pseudo-GT) labels"
- Pseudo-supervision: Supervision derived from teacher models or heuristics rather than human labels. Example: "Multi-modal teachers provide pseudo-supervision"
- Relative pose consistency: A training signal enforcing consistency of relative transformations between frame pairs. Example: "we supervise the predicted camera poses using relative pose consistency across frame pairs."
- Root mean square error (RMSE): A standard error metric measuring the square root of the average squared differences. Example: "We compute root mean square error in meters"
- SegFormer: A transformer-based semantic segmentation model used as a teacher for pseudo-labels. Example: "A pretrained SegFormer model"
- Semantic segmentation: Per-pixel classification into predefined semantic categories. Example: "predict semantic segmentation with 7 classes"
- Structure-from-Motion (SfM): A technique to reconstruct 3D structure and camera motion from multiple images. Example: "Structure-from-Motion (SfM) and Multi-View Stereo (MVS)"
- Token (latent scene tokens): Discrete feature vectors representing frames or parts of scenes used by transformers. Example: "encodes observed frames into latent scene tokens."
- Volumetric differentiable rendering: Rendering approach that models scenes as 3D volumes and is differentiable for learning. Example: "a self-supervised learning paradigm that uses 3D volumetric differentiable rendering"
- World models: Predictive models that learn to forecast future observations or latent states for planning/control. Example: "Unlike large world models that still require a degree of supervised labels"
Collections
Sign up for free to add this paper to one or more collections.