- The paper demonstrates that standard recommendation objectives cause low-frequency explosion, leading to unstable filter learning and degraded performance.
- It proposes a bi-level optimization framework that decouples filter parameter and embedding updates, ensuring stable convergence and adaptive spectral filtering.
- Empirical results across benchmarks show that ASPIRE outperforms tuned baselines with up to 13.9% gains in key metrics such as NDCG@20 and Recall@20.
ASPIRE: Adaptive Spectral Graph Collaborative Filtering via Bi-Level Filter Learning
Introduction
ASPIRE addresses critical limitations in spectral graph collaborative filtering (CF), particularly the instability and performance degradation found in naively learnable spectral filters under standard recommendation objectives such as BPR and CE losses. The work demonstrates that conventional objectives create a pronounced low-frequency preference (low-frequency explosion), undermining filter stability and effective spectral learning. The authors introduce a theoretically principled, bi-level optimization framework that adaptively learns spectral graph filters, thereby reconciling the desirable generalization of learnable filters with the empirical benefits of carefully hand-engineered alternatives.
Analysis of Low-Frequency Explosion in Spectral Graph Filtering
Contrary to expectations that learnable filters would outperform hand-designed ones by maximizing expressive capacity and adaptability, direct optimization leads to severe spectral bias. Specifically, gradients under standard objectives disproportionately amplify low-frequency spectral components while systematically attenuating high-frequency ones, even when these are informative for recommendations. This misalignment results in both metric and filter instability, as evidenced by consistently increasing low-frequency filter magnitudes and performance collapse in naive learnable methods.
Extensive spectral analysis, formalized by Theorem 1 in the paper, proves that these training dynamics are intrinsic to the structure of objectives like BPR. The gradient with respect to the spectral filter g(λk) is modulated by the eigenvalue λk, amplifying low-pass bias as training progresses. This effect is visualized in the filter evolution of naive-learnable models (Figure 1):
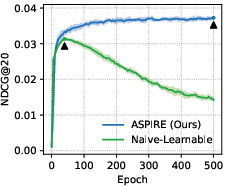
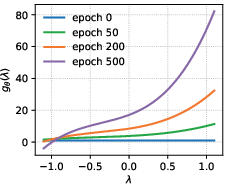
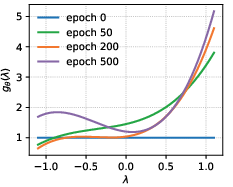
Figure 1: ASPIRE corrects the low-frequency explosion of naive-learnable filters, stabilizing convergence and enabling superior generalization.
The ASPIRE Framework: Bi-Level Adaptive Filter Learning
ASPIRE circumvents spectral imbalance by decoupling the filter optimization from the conventional lower-level recommendation objective. The approach comprises:
- Pre-filter normalization: Embedding matrices are ℓ2-normalized row-wise prior to filtering, mitigating dominance by high-norm nodes and accelerating convergence.
- Adaptive polynomial spectral filter: gθ(Λ)=l=0∑LθlΛl with learnable θ, initialized as a full-pass (identity) filter.
- Bi-level optimization: The filter parameters θ are optimized with respect to a validation loss, while holding the embedding parameters E fixed at the lower level. This separation corrects the frequency bias by ensuring the filter learns properties driving oracle predictive accuracy on validation data.
Empirical results establish that ASPIRE achieves robust metric and filter stability irrespective of initialization, dataset, or graph augmentation, with learned filters converging to similar spectral shapes and consistently outperforming or matching manually tuned baselines.
Across canonical benchmarks (Amazon Baby, Electronics, Ciao, LastFM) and varying graph scenarios (homogeneous, heterogeneous, dual-branch with side information), ASPIRE either matches or surpasses the efficacy of manually crafted filters (Jacobi basis, linear-correction, avg-pooling, etc.), yielding up to 13.9% gains in NDCG@20 and Recall@20 over strong baselines. Figure 2 presents average filter rankings across scenarios, demonstrating ASPIRE's general robustness:
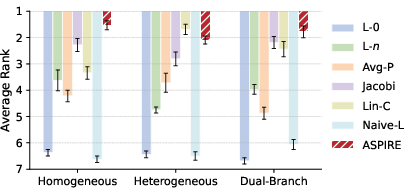
Figure 2: ASPIRE attains top average rankings in both homogeneous and dual-branch settings, validating its generalizability.
The learned spectral filters exhibit strong adaptivity, reflecting structural differences between pure interaction, side-information, and multi-branch graphs. For example, side-information graphs, empirically shown to benefit from more aggressive low-pass filters, are captured by the response of ASPIRE's learned filter (Figure 3).
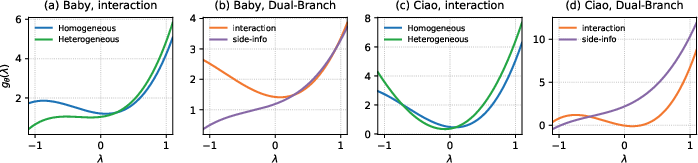
Figure 3: ASPIRE’s learned filters dynamically adjust their spectral shape according to the graph scenario, maintaining informative mid- and high-frequency responses when necessary.
Stability, Convergence, and Robustness to Initialization
A defining advantage of ASPIRE is training and convergence stability. Unlike naive-learnable filters, which suffer abrupt metric degradation (“catastrophic collapse”) and low-frequency explosion, ASPIRE maintains smooth filter trajectory and stable metric improvement throughout optimization. Different initializations (full-pass, low-, mid-, high-pass) converge rapidly to nearly identical filter profiles (Figure 4).
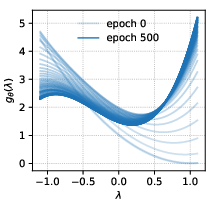
Figure 4: ASPIRE’s learned filter evolution shows insensitivity to initialization, robust convergence to a stable solution.
Extension to LLM-Powered Collaborative Filtering
The efficacy of ASPIRE extends to LLM-augmented CF, where user/item representations are initialized or projected from transformer-based encoders. Extensive experiments with adapters (whitening-init and MLP-projection) and LLMs (MiniLM-L6, Qwen2.5-7B, SFR-Emb) reveal that:
- ASPIRE consistently achieves superior or equal metric and filter stability relative to both avg-pooling and naive-learnable filters.
- Low-frequency explosion persists in naive-learnable models even when LLM embeddings provide strong initialization, further affirming the necessity for the ASPIRE approach.
- ASPIRE naturally mitigates modality forgetting and instability associated with vanilla graph filtering in LLM-powered CF setups (Figure 5).
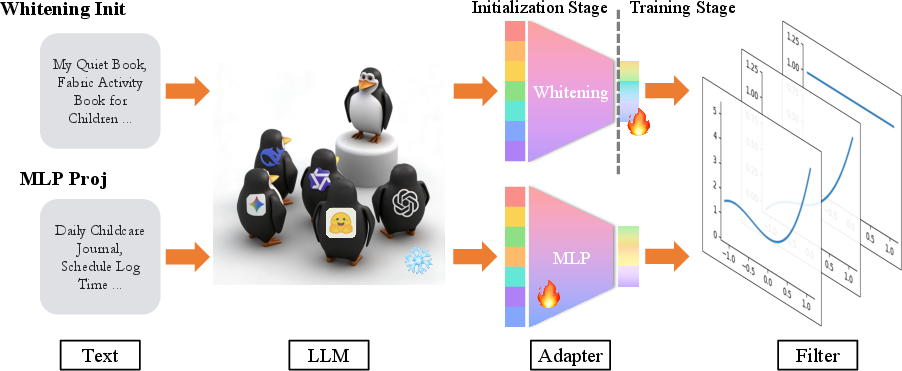
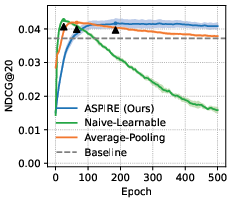
Figure 5: In LLM-powered CF, ASPIRE preserves filter and metric stability under both whitening-init and MLP-projection adapters.
Implications and Future Directions
ASPIRE establishes that adaptive and generalizable spectral filter learning is viable and effective on complex graphs encountered in collaborative filtering, matching or exceeding hand-designed approaches while obviating the need for tedious hyperparameter search. The theoretical diagnosis of objective-induced spectral bias not only guides filter design but also exposes a broader principle: standard recommendation loss functions can misalign model expressivity and learning dynamics by entrenching undesirable spectral biases.
The bi-level optimization framework underscores the potential of nested objectives for mitigating such inductive biases and provides a blueprint for future developments in expressively parameterized GNN architectures. Extensions to deeper or more complex GNNs, temporal/sequential recommendation tasks, and fairness-aware/bias-robust filtering are straightforward directions. Integration with task-specific objectives and broader LLM adaptation frameworks should be further explored.
Conclusion
ASPIRE delivers a validated, theoretically sound method for adaptive, stable, and effective spectral filter learning in collaborative filtering. By exposing and remedying the failures of naive filter parameterization, it broadens the practical adoption of learnable GNNs and spectral analysis tools across modern recommender systems, including those leveraging LLMs.