- The paper introduces a unified deployment artifact that preserves PyTorch semantics for both software and FPGA-based event-driven SNN inference.
- It demonstrates hardware acceleration with 0.1375 μs latency per image, achieving 7.27×10^6 images/s throughput and 31.6 nJ energy per image.
- Benchmark results show the FPGA is 1.79× faster and 933× more energy-efficient than GPUs while maintaining reproducible 87.40% MNIST accuracy.
Hardware–Software Co-Design for Event-Driven SNN Deployment on Low-Cost Neuromorphic FPGAs
Introduction
This paper presents a hardware–software co-design framework that achieves deterministic deployment of PyTorch-defined spiking neural networks (SNNs) on event-driven FPGA platforms, specifically targeting the low-cost PYNQ-Z2 development board. Existing SNN research pipelines are typically fragmented: hardware-first approaches are efficient but not readily integrated with contemporary machine learning software stacks, while software-first approaches built atop frameworks like PyTorch rarely progress beyond simulation or GPU-bound execution. The work addresses this disconnect via a semantics-preserving deployment path grounded in a single artifact that is reused without modification between both software and hardware inference, enabling reproducible, event-driven execution and explicit separation of measurement scopes.
Co-Design Framework and Deployment Path
The central innovation is a PyTorch-aligned deployment flow that exports model parameters, thresholds, connectivity descriptors, and grouped time-to-first-spike (TTFS) decoding metadata into a single artifact. This artifact is consumed identically by the software reference and the FPGA runtime, eliminating the divergence often seen in software-hardware co-design—specifically, it ensures that model semantics are consistent throughout the workflow and preserves PyTorch-like invocation patterns on the board.
The hardware architecture leverages the Xilinx Zynq-7020 SoC's programmable logic for the event router, core groups, connectivity table, grouped TTFS decoder, and latency counters. Up to 2,048 neurons are supported in the default RTL event-processing pipeline, with the system ultimately limited by BRAM occupancy. Timing closure is achieved at 80 MHz, with the hardware path designed specifically for event-driven, TTFS SNN inference.
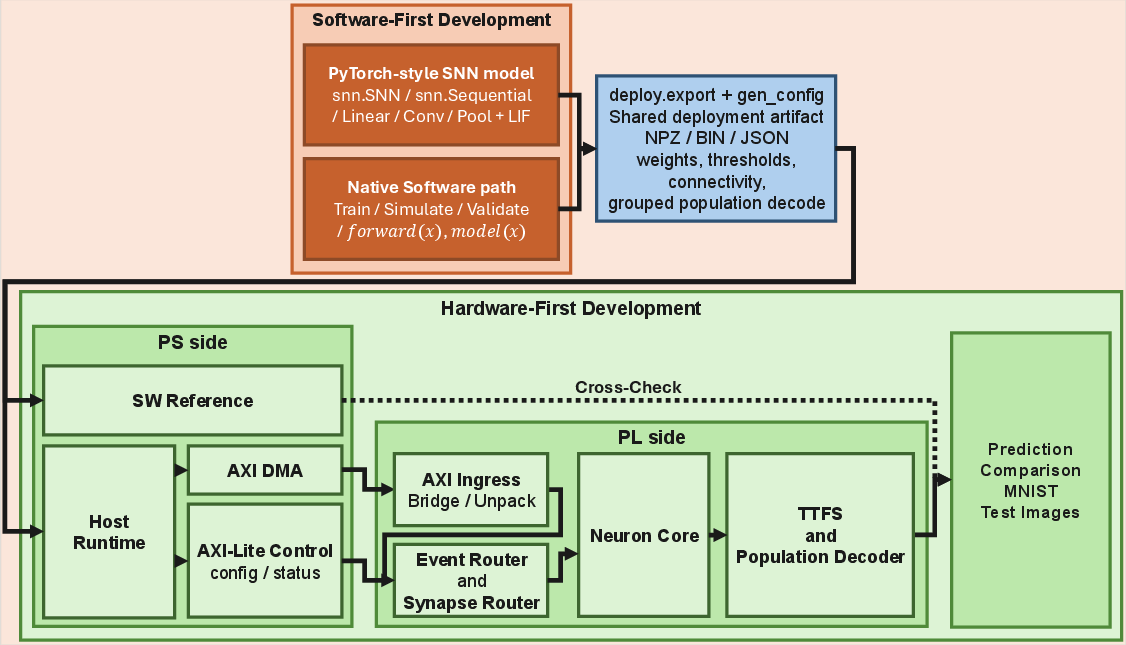
Figure 1: The architecture bridges PyTorch-style development and neuromorphic FPGA inference with a single deployment artifact and shared semantics for both paths.
System-Path Latency Profiling
A key aspect of the framework is its scope-aware benchmarking. System-level latency is decomposed into software reference execution, spike packing, hardware execution, and synchronization/readback. Accelerator-only latency and host-inclusive latency are reported separately to allow fair cross-platform comparisons. On the PYNQ-Z2, accelerator-only (PL) service latency for one image is 0.1375μs, yielding throughput of 7.27×106 images/s, with a dynamic energy estimate of 31.6nJ per image. The design achieves 87.40% accuracy on MNIST, precisely matching the software reference output for all 10,000 test images—a strict metric that emphasizes decision traceability rather than mere aggregate accuracy.
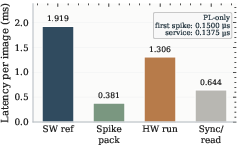
Figure 2: System-path latency analysis: the breakdown clarifies runtime cost distribution across reference computation, data marshaling, hardware execution, and I/O orchestration.
Cross-platform benchmarks using the same (exported) model on GPU (RTX 3080, both INT8 and FP32) and CPU (INT8/FP32) baselines reveal that the FPGA implementation is 1.79× faster and 933× more energy-efficient than the best GPU configuration (INT8), while the CPU is slower by more than two orders of magnitude.
To evaluate robustness, the impact of input spike sparsity is systematically quantified. Progressive random spike-drop stress degrades accuracy gradually instead of causing abrupt failures: from 87.40% with no drop, to 86.31% at 25% spike drop, 82.38% at 50%, and 69.74% at 75%. Across five full-test-set runs (50,000 image-run pairs), no prediction mismatches were observed, and performance remained consistent, indicating high determinism and stable runtime characteristics.
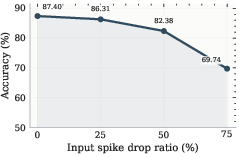
Figure 3: Classifier accuracy as a function of controlled spike input sparsity, demonstrating graceful degradation under adversarial input conditions.
Practical and Theoretical Implications
Practically, the proposed framework democratizes neuromorphic hardware research by making event-driven SNN deployment accessible on widely available, affordable FPGA hardware, removing reliance on proprietary digital neuromorphic systems (e.g., Loihi). The use of a unified deployment artifact not only ensures reproducibility and functional equivalence across software and hardware but also streamlines system integration for closed-loop and hardware-in-the-loop experiments. By precisely delineating accelerator-only versus host-inclusive measurements, the work sets a rigorously fair standard for future benchmarking.
Theoretically, the deterministic mapping of PyTorch-defined TTFS SNNs to low-cost digital event-based hardware provides an extensible foundation for elaborating more complex architectures (e.g., convolutional SNNs, deeper multi-layer networks) on BRAM-constrained platforms. The methodology’s strong results under input sparsity stress position it as a practical vehicle for research in robust neuromorphic processing. However, scalability is ultimately limited by on-chip BRAM and synaptic routing overhead; overcoming these will require architectural and routing optimizations.
Future Directions
Opportunities for further research include:
- Scaling to complex networks: Extending support to deeper and convolutional SNN architectures constrained by BRAM and routing fabric.
- Hardware optimizations: Implementing more aggressive synapse routing and compression techniques to increase neuron and synapse capacity per design.
- Generalization: Porting the flow to other low-cost FPGA families and supporting richer on-chip learning rules.
- Application scope: Deploying real-time closed-loop or hardware-in-the-loop neuromorphic systems for edge sensing, control, and robotics exploitation.
Conclusion
The presented hardware–software co-design path establishes a reproducible, deterministic workflow for deploying PyTorch-defined, event-driven SNNs onto low-cost FPGA hardware. Full-test-set output agreement, explicit separation of measurement scopes, and high parallel throughput with low dynamic energy position the framework as a reference model for semantics-preserving neuromorphic deployment. The approach offers a rigorously transparent and replicable foundation for both SNN hardware research and applications requiring event-driven, energy-efficient computation.
Reference: "Hardware-Software Co-Design for Event-Driven SNN Deployment on Low-Cost Neuromorphic FPGAs" (2604.22179).

