- The paper introduces a modular RAG pipeline that combines dense and sparse retrieval with cross-encoder re-ranking to achieve high QA accuracy.
- It employs synthetic MCQ data augmentation and efficient model fine-tuning using LoRA and quantization to operate under strict resource constraints.
- The approach demonstrates feasible local deployment for Ukrainian QA and offers a blueprint for adapting RAG to other under-resourced languages.
Efficient RAG for Ukrainian QA Under Local Resource Constraints
This essay provides a comprehensive technical analysis of "An End-to-End Ukrainian RAG for Local Deployment. Optimized Hybrid Search and Lightweight Generation" (2604.22095), focusing on its modular pipeline for Retrieval-Augmented Generation (RAG) in Ukrainian question answering, optimization strategies for resource efficiency, and empirical results from the UNLP 2026 Shared Task.
Context and Motivation
Reliable Question Answering (QA) over extended, domain-specific corpora remains challenging for LLMs due to inherent knowledge boundaries and the frequent emergence of hallucinations, particularly when addressing low-resource languages such as Ukrainian. The RAG paradigm mitigates these issues by grounding generative outputs in retrieved external documents, shifting performance bottlenecks from the generative component to retrieval accuracy. However, the scarcity of language-optimized resources, inefficiency in tokenization, and significant resource constraints for local inference amplify the technical hurdles for Ukrainian RAG systems.
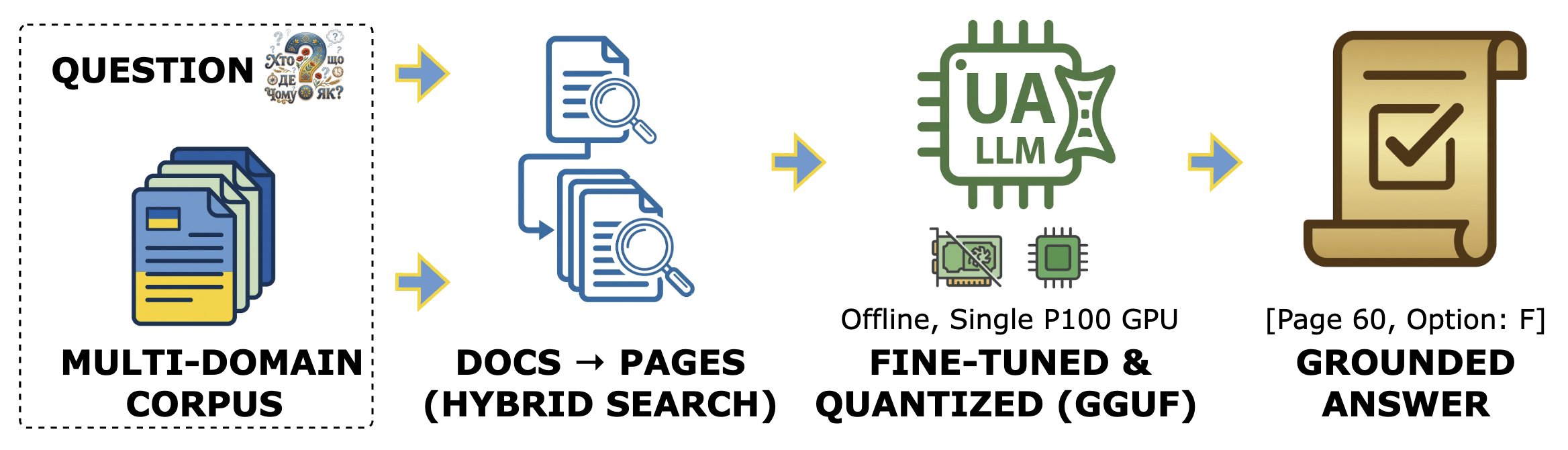
Figure 1: An end-to-end Ukrainian RAG for question answering on local deployment.
System Architecture
Data Preparation
The pipeline initiates with layout-preserving extraction of PDF documents via pymupdf4llm, converting rich text and structure into Markdown for subsequent retrieval-aware chunking. For sparse retrieval, a custom preprocessing filtration using pymorphy3 and domain-specific stop words ensures lexical normalization.
Two-Stage Hybrid Retrieval
The retrieval subsystem is designed as a hierarchical, hybrid architecture:
1. Document-Level Retrieval:
Dense semantic similarity is computed with Perplexity contextual embeddings. Simultaneously, BM25Okapi executes sparse retrieval on the entire preprocessed document corpus. When retrieval rankings from dense and sparse methods diverge, a performant cross-encoder reranker (jina-reranker-v3) is invoked on the top candidates, ensuring robust disambiguation.
2. Page-Level Retrieval:
Documents are chunked along Markdown-defined syntactic boundaries (<500 characters, 10% overlap, single-page confinement), supporting context retention while optimizing embedding calculation. Batched (with overlap) embedding aggregation is used to reduce quantization and memory overhead. Chunk-level similarity rankings integrate both embedding and BM25 scores, fused via Reciprocal Rank Fusion (RRF), and are finalized by a fine-tuned BAAI/bge-reranker-v2-m3 cross-encoder over the top-8 candidates.
Lightweight Generation and Grounding
For answer generation, the MamayLM-Gemma-3-12B model is fine-tuned through LoRA on explicitly grounded synthetic and in-domain MCQ data. Syntactic masking restricts loss propagation to answer tokens. Model quantization (GGUF 4-bit) and deployment via llama.cpp enable high-throughput inference under stringent VRAM and compute ceilings, matching the constraints imposed by the UNLP 2026 Task.
The system prompt design enforces explicit, grounded responses in the form "Letter Page", facilitating verifiable attribution of answers to specific context pages–a critical requirement for trustworthy RAG QA.
Training and Optimization Strategies
Synthetic Data Generation
Due to a dearth of in-domain annotated MCQ data in Ukrainian, a robust synthetic QA augmentation pipeline is constructed using OpenAI's gpt-4o-mini. The synthesis process enforces domain-specific constraints, factual anchoring, and format consistency with task demand, yielding roughly 7,000 additional training items.
Model Fine-Tuning
The reranker model is optimized using a hybrid listwise and pointwise loss function to maximize retrieval precision. For the generative model, progressive fine-tuning—synthetic pretraining followed by adaptation to the true development set—maximizes transfer while retaining in-domain specificity. Efficient optimization techniques are employed, including AdamW in 8-bit, cosine learning rate annealing, Flash Attention 2, and dynamic long-context truncation.
Evaluation and Results
Leaderboard evaluation uses a three-component metric: QA accuracy (0.5 weight), correct document grounding (0.25), and page-level proximity (0.25, credit for close, not just exact, matches). On the hidden-domain private test set, the system achieves a strong numerical benchmark: 0.942, placing second overall under strict 9-hour, single-P100-GPU constraints. Additional metrics include nearly perfect document retrieval accuracy and page-level recall@3 of 0.92 on the development set.
Implications and Future Directions
This work demonstrates that with judicious architectural modularity—namely efficient, hierarchically hybrid retrieval and high-fidelity quantized generation—high-precision RAG QA for a medium-resource language is feasible on modest hardware without licensing closed LLMs or cloud APIs. The synthetic data approach, in combination with task-anchored prompt design, provides a viable template for low-resource language adaptation.
The primary limitations are related to the restricted compute regime: absence of image/chart OCR, rare PDF parsing failures affecting a small corpus subset, and constraints imposed by legacy quantization. With next-generation quantization, further improvements are plausible. Additionally, the approach is extensible to other underrepresented languages, provided sufficient document structure is available for extraction and chunking.
The modular design facilitates future research in adaptive retrieval modeling, cross-lingual transfer for hybrid search, and more advanced hallucination mitigation in grounded generation. For high-stakes verticals (e.g., pharmaceutical QA), ongoing human oversight remains essential to mitigate systemic data or model biases.
Conclusion
The paper provides a rigorous empirical and methodological case study of deploying a RAG QA system for Ukrainian under extreme resource constraints (2604.22095). Its principal contributions include a robust, hybrid retrieval pipeline; synthetic data-driven, precision-adapted generation; and demonstration of state-of-the-art accuracy for both retrieval and generation components. The work lays a foundation for efficient, trustworthy local deployment of RAG models in under-resourced languages and domains.