- The paper introduces a repair-and-augment paradigm that combines neural representations with a single-step conditioned diffusion model (SliceFixer) for effective artifact correction in sparse-view CT.
- It demonstrates significant improvements, with notable PSNR gains and efficient runtime, outperforming traditional iterative reconstruction methods on benchmarks like ToothFairy and LUNA16.
- The approach enhances volumetric consistency and downstream segmentation accuracy, paving the way for safer, low-dose CT imaging and hybrid inverse imaging solutions.
DiffNR: Diffusion-Enhanced Neural Representation Optimization for Sparse-View 3D Tomographic Reconstruction
Introduction
DiffNR addresses an acute challenge in sparse-view computed tomography (CT): accurate volumetric reconstruction from limited X-ray projections without sacrificing anatomical fidelity or efficiency. Traditional iterative reconstruction methods or neural representations (NRs) are highly susceptible to artifacts under severe data sparsity. Prior diffusion priors have advanced artifact suppression yet suffer from computational inefficiency and limited volumetric coherence. DiffNR proposes a repair-and-augment paradigm leveraging a single-step conditioned diffusion model (SliceFixer) for artifact correction, inherently improving the optimization and generalization properties of NRs in sparse-view 3D CT.

Figure 1: DiffNR schematic, demonstrating (a) the cone-beam CT geometry, (b) the pipeline overview, and (c) comparison with baseline NR methods.
Methodology
SliceFixer: Conditioned Single-Step Diffusion for Slice Repair
SliceFixer is a single-step diffusion model built on SD-Turbo, adapted via LoRA and zero convolution layers for artifact correction in NR-reconstructed CT slices. Conditioning integrates biplanar X-ray projections and text prompts through RAD-DINO encoders for enhanced global structural guidance. The loss regime includes L2, LPIPS, CLIP, GAN, and SSIM losses, with SSIM explicitly targeting perceptual improvements and structural coherence.
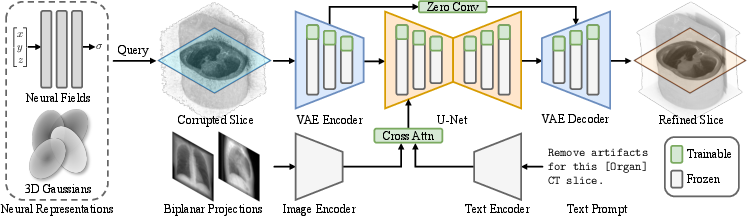
Figure 2: SliceFixer architecture showing the integration of CT slice latents, projection encodings, and text-based conditioning.
Data Curation and Diversity
SliceFixer finetuning leverages synthetic artifacted and clean slice pairs generated by underfitting various NR backbones (neural fields, 3D Gaussians) with randomized sparse-view distributions. This strategy enforces robustness to diverse artifact patterns and prevents overfitting to specific NR-induced degradations.
DiffNR Optimization Pipeline
DiffNR interleaves conventional NR optimization (with L1, SSIM, and TV losses) and periodic augmentation via SliceFixer, producing pseudo-referenced volumes for regularization. This pipeline mitigates slice jitter and diffusion hallucination by integrating 3D SSIM supervision (across axial, sagittal, and coronal planes) between the current volume and SliceFixer-augmented reference, substantially enhancing volumetric consistency.
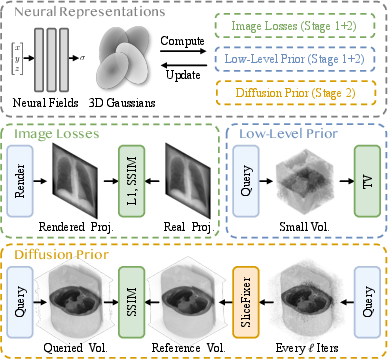
Figure 3: DiffNR pipeline showing two-stage optimization, with periodic pseudo-reference generation and SSIM-based perceptual regularization.
Experimental Results
Quantitative and Qualitative Comparisons
DiffNR achieves substantial gains across ToothFairy and LUNA16 benchmarks, improving NR PSNR scores by 2.19 dB (NAF backbone) and 5.79 dB (R2-Gaussian backbone). On out-of-distribution (OOD) datasets, DiffNR maintains superior artifact suppression and generalization. Notably, DiffNR's runtime is an order of magnitude lower than prior diffusion-based iterative methods, owing to its efficient repair-and-augment design.
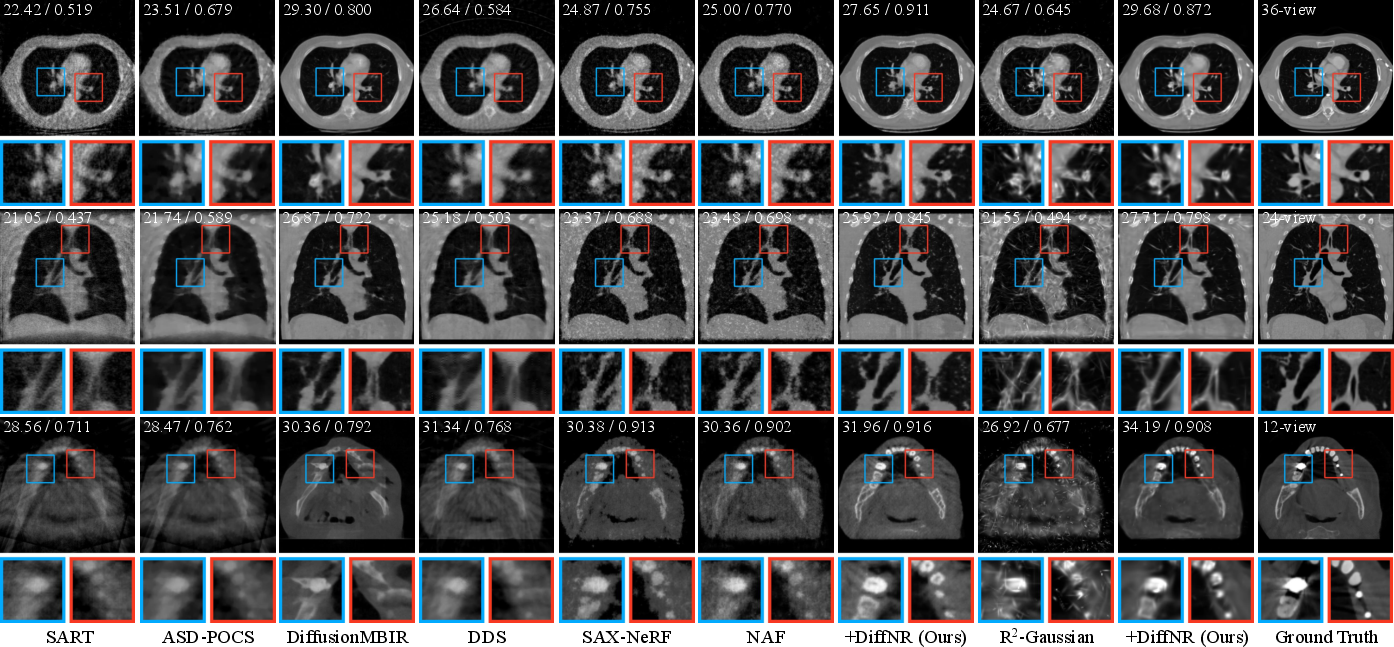
Figure 4: Qualitative reconstruction results showing superior detail recovery and artifact suppression from DiffNR on multi-view CT slices.
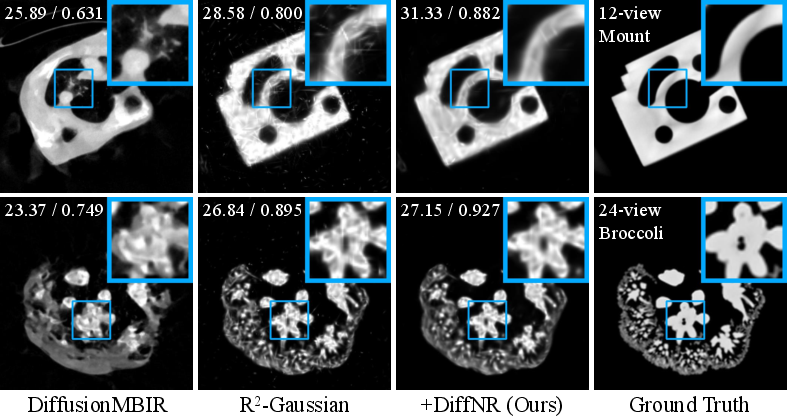
Figure 5: DiffNR’s qualitative performance on challenging OOD datasets, demonstrating robust artifact correction and anatomical fidelity.
DiffNR-enhanced volumes facilitate improved downstream medical segmentation, with lung Dice scores up to 93.74 (36-view). The integration of SSIM loss and biplanar projection conditioning in SliceFixer is empirically validated as critical for volumetric quality and segmentation stability.
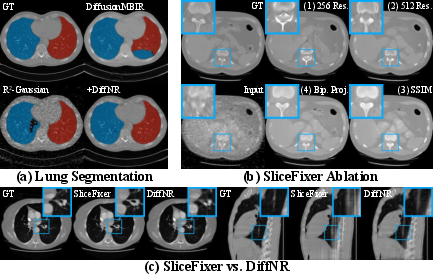
Figure 6: Downstream lung segmentation, ablation analyses of SliceFixer, and comparison of standalone post-processing versus deep pipeline integration.
Ablation Analyses
Key architectural choices include SliceFixer resolution upsampling, SSIM loss inclusion, and biplanar conditioning—all yielding positive PSNR/SSIM shifts. Integrating SliceFixer directly into NR optimization outperforms standalone post-processing, as shown in ablations. Augmentation via slice supervision, rather than projections, is established as more effective for CT volumes, given the cumulative nature of projection errors.
Implications and Future Directions
Practically, DiffNR enables safer CT imaging by reducing exposure while preserving diagnostically relevant structures. Theoretically, the repair-and-augment strategy offers a generalized pathway for integrating powerful diffusion priors with global neural representations across inverse problems. Its demonstrated generalization across anatomical and OOD datasets, combined with computational efficiency, sets a precedent for future hybrid reconstruction paradigms. Further developments should explore cross-modal conditioning, direct 3D diffusion frameworks, and adaptive data curation tailored to non-medical domains and novel scanning geometries.
Conclusion
DiffNR presents a principled, efficient, and generalizable approach for sparse-view CT reconstruction by bridging neural representations and conditional diffusion priors. Its architecture, data synthesis, and optimization strategies collectively suppress artifacts, enforce volumetric consistency, and accelerate inference without succumbing to hallucination or slice jitter. The repair-and-augment methodology introduced by DiffNR is likely to inspire subsequent research in hybrid optimization and inverse imaging, particularly for regimes where measurement constraints necessitate learned regularization and computational scalability.