- The paper introduces a novel dataset (EVENT5Ws) that uses the 5Ws paradigm to enable open-domain event extraction from 10,000 diverse news reports.
- The methodology employs phased manual annotation with iterative coder training, achieving high inter-coder reliability (α ≥ 0.80) even on challenging event aspects.
- LLM benchmarks reveal strong performance on entity-based Ws while extracting abstract concepts like 'What' and 'Why' remains challenging, highlighting the need for improved contextual models.
EVENT5Ws: A Large Open-Domain Event Extraction Dataset for Document-Level NLP
Motivation and Dataset Design
Automatic event extraction from documents is a fundamental task in NLP, with direct implications for information retrieval, situational awareness in emergencies, and various downstream tasks. Prevailing datasets for event extraction are limited either by closed-domain schemas or constrained annotation scale. The "EVENT5Ws: A Large Dataset for Open-Domain Event Extraction from Documents" (2604.21890) introduces a comprehensive, manually annotated dataset using the classical 5Ws paradigm (“where”, “when”, “what”, “who”, “why”) for main events within documents, addressing the deficiencies of prior resources in diversity, generality, and scale.
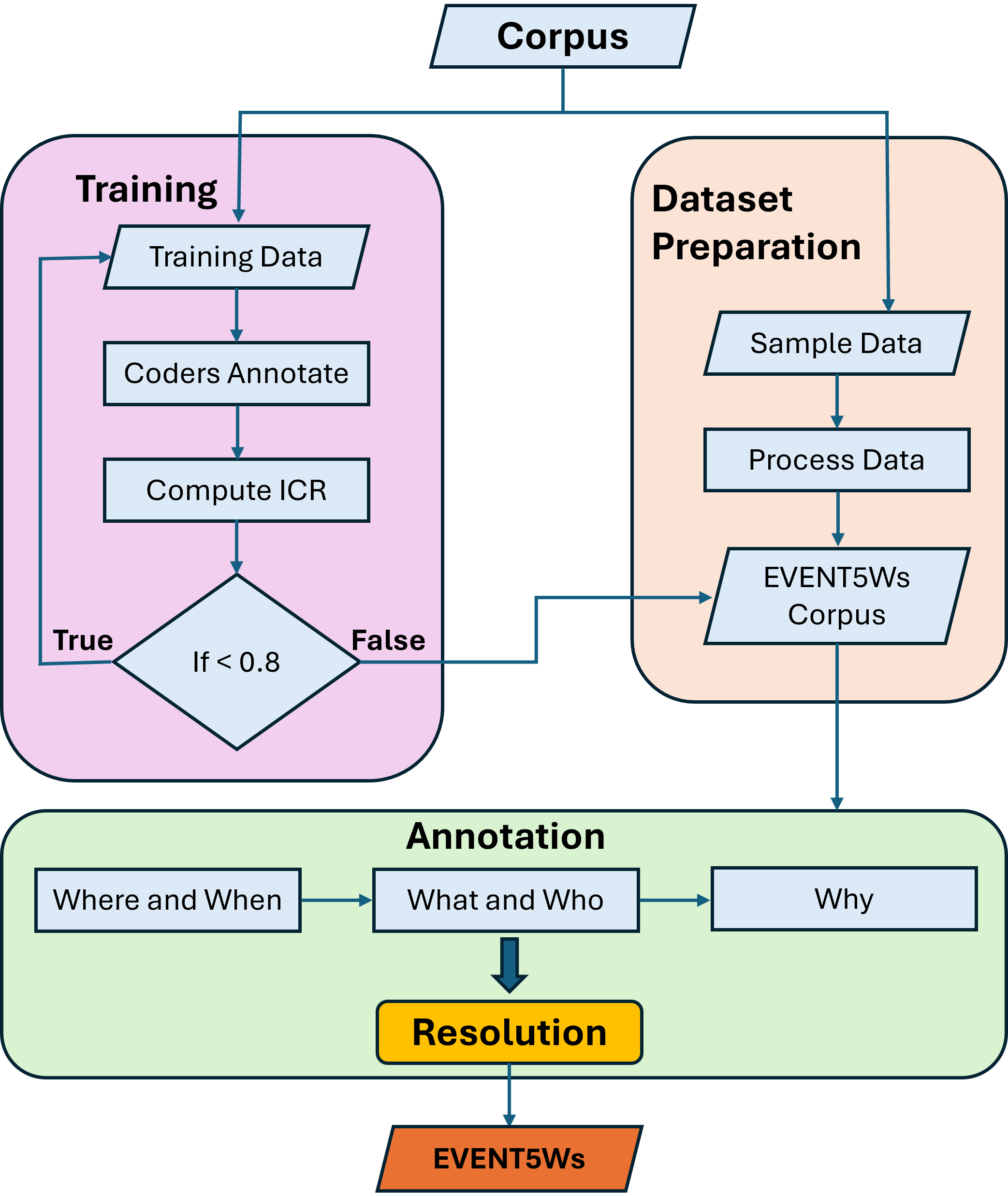
Figure 1: The overall schematic of the EVENT5Ws dataset development workflow, from document selection to annotation and resolution.
EVENT5Ws is constructed from a diverse corpus of 5.24 million news reports from seven Indian newspapers (national and regional). A stratified random sample yields 10,000 reports spanning 2015–2019, each truncated to the title and first five sentences (empirically demonstrated to capture 97.3% of main events). Annotation is executed in three phases by recruited university students familiar with the local context, and validated using Krippendorff’s alpha (α), achieving α≥0.80 for all 5Ws after iterative training and resolution.
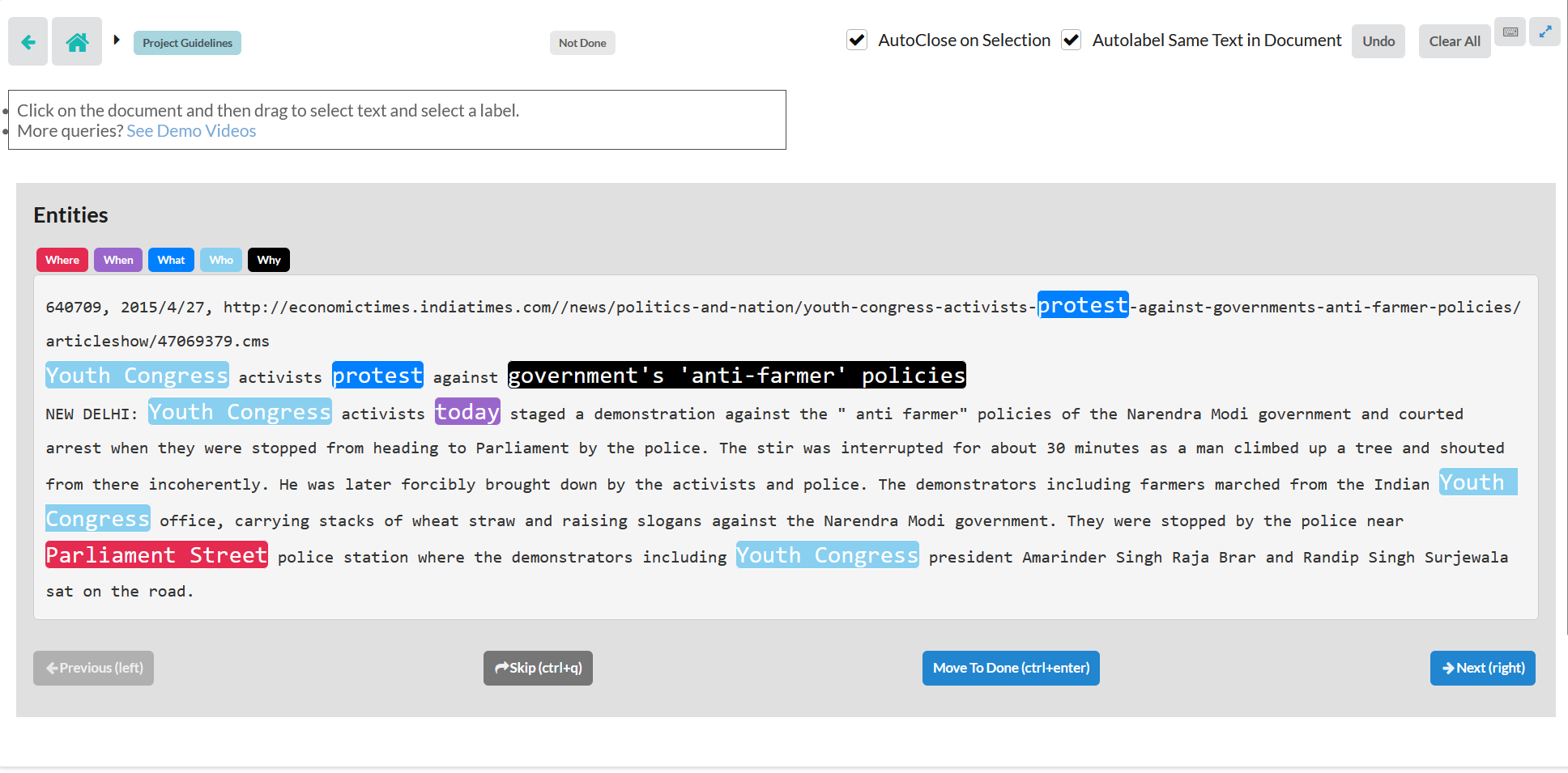
Figure 2: Snapshot of Dataturks annotation platform, showing 5Ws annotated for the main event in a sample document.
Dataset Characteristics and Annotation Complexity
The dataset exhibits high lexical diversity and variable annotation complexity between the Ws. "Where", "When", and "Who" are predominantly short, entity-based spans with high coder agreement and reduced annotation time; "What" and "Why" are longer, more descriptive, and often implicit or absent, leading to increased disagreement and annotation complexity. Semantic similarity (computed via spaCy) supplements exact match metrics for measuring inter-coder reliability in these cases.
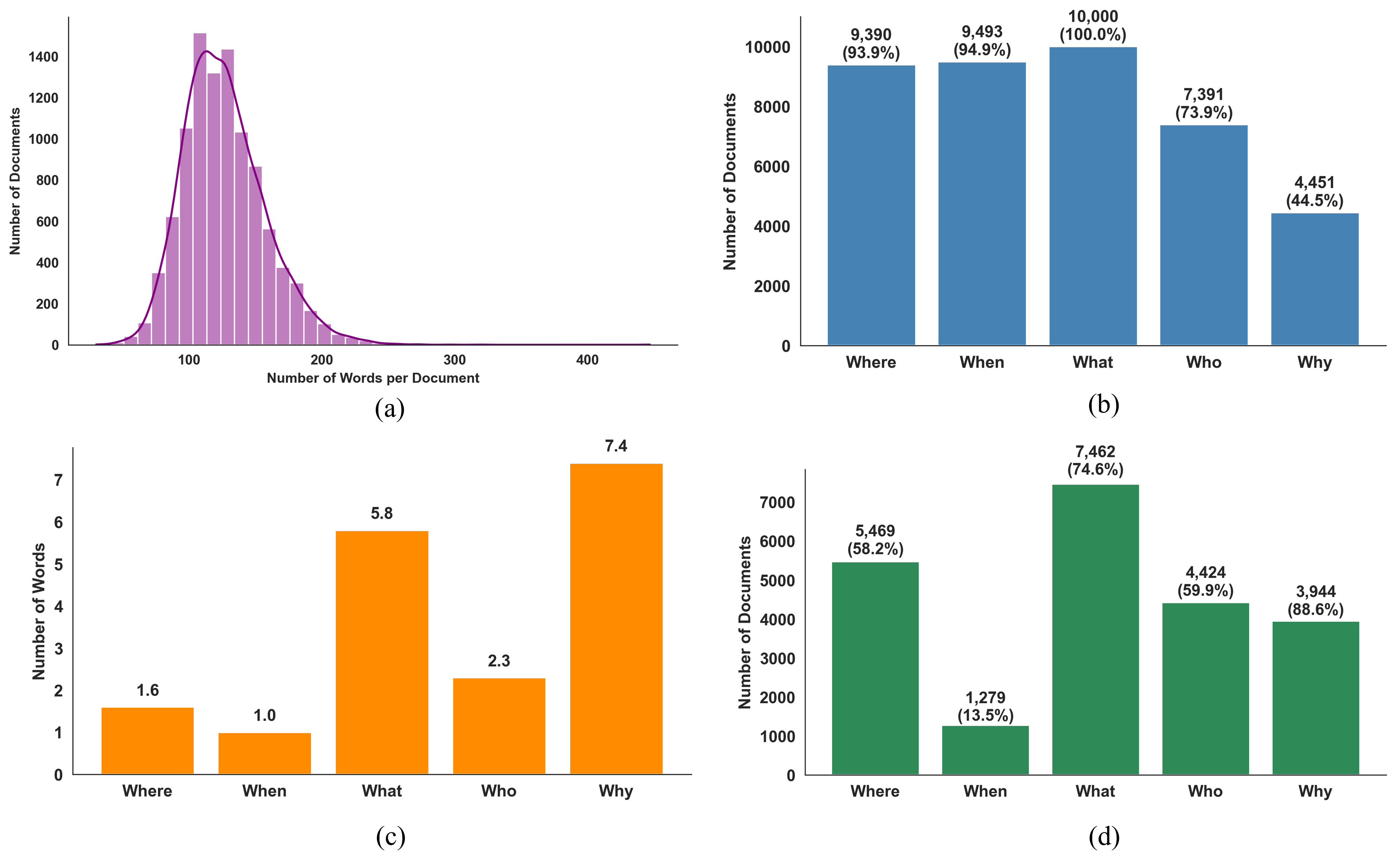
Figure 3: Summary statistics for document length, frequency of each W, span length distribution, and lexical diversity for annotated Ws.
Background and main events are distinguished by global document context and centrality, leveraging discourse analysis literature for annotation guidelines. Preference is given to specific entities over generic groups for "Who", and concise, semantically complete nuggets for "What" and "Why".

Figure 4: Illustration highlighting the main event (in red) and background events (in other colors) within a document.
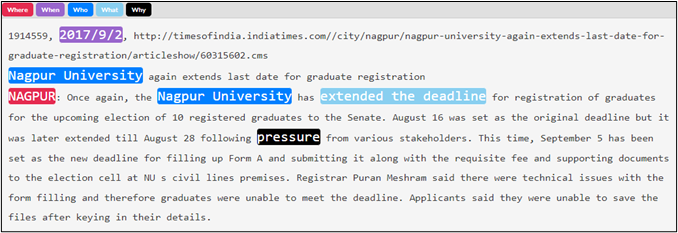
Figure 5: Example of "What" annotation in a document; the event nugget is highlighted.
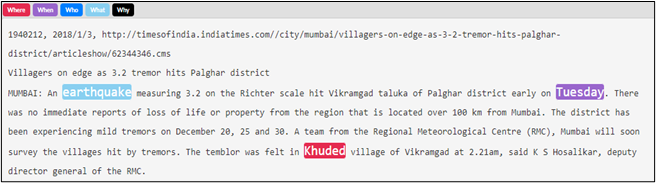
Figure 6: Example of "Where" annotation for an earthquake event, with the most precise place name labeled.
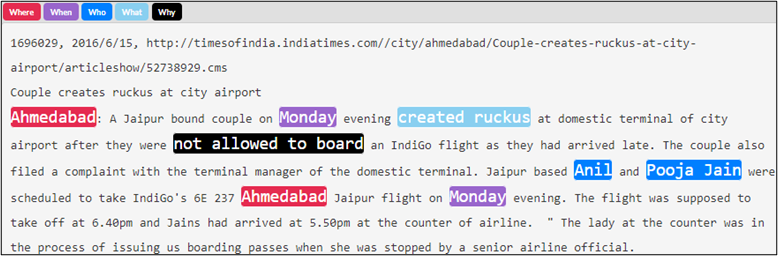
Figure 7: Example of "Who" annotation, showing precise identification of actors preferred over generic descriptions.
Benchmarking LLMs: Results and Analysis
A suite of SOTA LLMs (Gemma, Llama, Qwen, Mistral, T5 Large) is benchmarked for 5Ws extraction via zero-shot and five-shot prompting. Precision, recall, and F1 are reported via exact match (EM) and ROUGE-L. Models consistently perform better on "Where", "When", "Who" (mostly entity types), while performance on "What" and "Why" remains low across all models and prompting paradigms. Five-shot prompting yields modest improvements; neither increased model scale nor reasoning-oriented architectures mitigate the extraction difficulty for conceptually challenging Ws.
The best exact match F1 achieves only 36.5 ("Who", Gemma 5-shot) and 51.4 ("When", Llama 70B 5-shot). ROUGE-L scores are systematically higher, indicating frequent generation of partial or semantically similar (but non-matching) outputs. T5 Large underperforms across all benchmarks. These findings indicate that direct prompting of off-the-shelf LLMs does not suffice for high-fidelity document-level event extraction, especially for open schema concepts.

Figure 8: Zero-shot prompting example demonstrating the model instruction for extracting the 5Ws.

Figure 9: Five-shot prompting example, showing guidance from in-context examples for event 5Ws extraction.
Generalization Across Domains and Geographies
To evaluate cross-domain generalizability, T5 Large is fine-tuned on EVENT5Ws and tested on manually verified main event 5Ws extraction data from US/UK newspapers [hamborgGiveme5W1HUniversalSystem2019]. Despite the domain and cultural shift, the model trained on EVENT5Ws outperforms the rule-based Giveme5W1H baseline in both EM and ROUGE-L. This empirical result supports the recruitment strategy (coders familiar with news and culture) and the theoretical claim that EVENT5Ws enables generalizable event extraction models.
Implications, Recommendations, and Future Directions
From a practical standpoint, EVENT5Ws enables development and benchmarking of robust document-level event extraction algorithms capable of open-domain generalization and accommodating unconstrained event types. The detailed annotation pipeline, phased approach to varying W complexities, and batch-wise monitoring offer effective methodologies for large-scale human annotation projects. Selection and training of coders familiar with domain context demonstrably enhance annotation reliability and efficiency.
On a theoretical level, the pronounced difficulty for "What" and "Why" extraction with current LLMs exposes gaps in contextual and causal reasoning capacity in neural architectures, suggesting the need for advances in global document context modeling, discourse comprehension, and specialized event extraction modules beyond generic transformers. Integration of multimedia (images, video) and multimodal event structures [zhangImprovingEventExtraction2017, liCLIPEventConnectingText2022, sunUMIEUnifiedMultimodal2024] represents a promising extension, as does multi-task learning and structured prediction for event-centric information extraction.
Conclusion
EVENT5Ws presents a rigorously constructed, large-scale, open-domain event extraction dataset annotating the main event’s 5Ws at the document level. Empirical LLM benchmarks reveal strong performance disparities between entity-based and conceptually abstract event aspects, underscoring the continuing challenge of document-level open event extraction in NLP. The dataset’s demonstrated generalizability across domains, alongside its annotation methodology, propels both practical system development and fundamental inquiry into event-centric representation and reasoning for text, multimodal, and multilingual contexts.