- The paper introduces MODEE, a four-module multimodal architecture that fuses T5 text encodings and GNN-based graph representations for comprehensive document-level event extraction.
- It employs an attention-based gated fusion with contrastive training to effectively capture long-range dependencies and accurately extract challenging 5W event arguments.
- Empirical results demonstrate that MODEE outperforms fine-tuned T5 and large LLMs on F1, ROUGE-L, and BERTScore metrics, underscoring its superior document-level reasoning.
Multimodal Text- and Graph-based Event Extraction: A Technical Overview of MODEE
Introduction and Motivation
Event extraction (EE) is central to broad information extraction, supporting applications such as document summarization, disaster response, and knowledge graph construction. Traditional EE approaches fall into closed-domain and open-domain paradigms. Closed-domain methods are typically schema-driven, confining extraction to predefined event types and argument roles, and are often limited to sentence-level context, which impairs their ability to capture event arguments dispersed across a document. Recent advances have extended some approaches to document-level EE, but the reliance on predefined schemas and the lack of adaptability to new event types remain significant limitations.
Open-domain approaches offer flexibility in event types but have hitherto been dominated by heuristics, rules, and weakly supervised learning, resulting in poor generalization and limited capacity to model context and structure at the document level. Despite the emergence of LLMs, their application to document-level open-domain EE remains insufficient due to challenges such as the "lost-in-the-middle" phenomena and attention dilution, which diminish their ability to reason across long contexts and capture structural dependencies. Addressing these bottlenecks, Sharma proposes MODEE: a multimodal open-domain event extraction architecture integrating textual representations from LLMs and structural representations from Graph Neural Networks (GNNs), with an attention-based gated fusion mechanism for enhanced document-level reasoning (2604.21885).
MODEE Architecture
MODEE is constructed as a four-module architecture:
- Text Encoder: Utilizes the T5 encoder to generate contextualized token-level embeddings from document text.
- Graph Encoder: Constructs a complete token graph for a document, where nodes are tokens and edges connect all token pairs, encoded via a GraphSAGE LSTM-based two-layer GNN to capture long-range dependencies and document structure.
- Attention-based Gated Fusion: Projects both text and graph embeddings to a shared latent space and computes a gating vector via additive attention, dynamically weighting token relevance across modalities.
- Text Decoder: Based on the T5 decoder, this module autoregressively generates the five journalistic 5Ws (where, when, what, who, why) as structured event information.
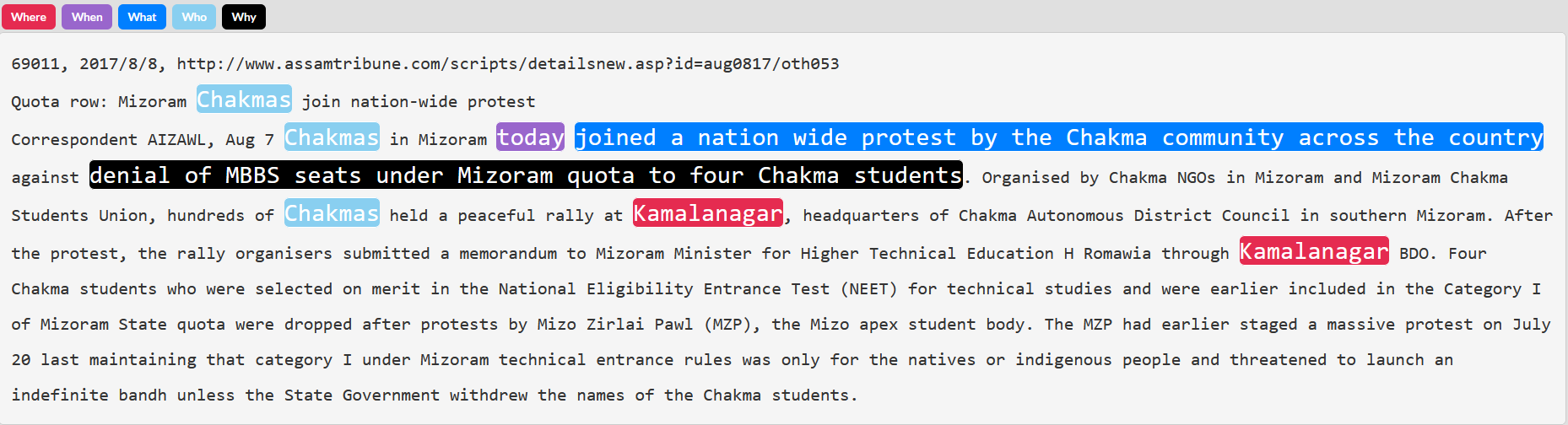
Figure 1: Example of document annotation in the dataset, with the 5Ws for the main event highlighted.
By design, the attention-based gated fusion takes the sum of linearly projected text and graph features, passes it through a tanh non-linearity, and then computes a gating vector with a sigmoid-activated linear mapping, used to modulate the original text encoder's representation for downstream decoding. This enhances semantic and structural selection pressure during event-related argument extraction.

Figure 2: One-shot prompt example used to guide LLM extraction within the MODEE evaluation.
Dataset and Evaluation Protocol
MODEE is evaluated on a novel corpus of 10,000 news documents from seven Indian newspapers, annotated with rigorous inter-coder reliability procedures (Krippendorff’s alpha > 0.8). Each document includes the title and first five sentences to maximize coverage of the main event and minimize annotation ambiguity, consistent with journalistic conventions and empirical findings on argument dispersion in news. The 5W annotations comprise the extraction target for main event identification.
Main metrics include exact match (EM), ROUGE-L, and BERTScore, computed for the 5W tuple both lexically and semantically.

Figure 3: Further illustration of prompt design for LLM prompting scenarios assessed in experiments.
Empirical Results
MODEE-Base (T5-Base backbone) achieves:
- F1 (EM): 57.7%
- F1 (ROUGE-L): 73.7%
- F1 (BERTScore): 94.7%
compared to T5-Base (fine-tuned) with F1 (EM) 53.3%, ROUGE-L 70.5%, BERTScore 94.1%, and T5-Large (fine-tuned) at 55.8%, 73.0%, 94.5%. Notably, large decoder-only LLMs under both zero- and few-shot prompt regimes (Llama, Qwen, Mistral up to 70B parameters) underperform both tuned T5 and MODEE, with F1 (EM) not exceeding 17.4% and BERTScore below 88.0%. Rule-based Giveme5W1H yields only 16.1% F1 (EM). MODEE’s capacity to maintain strong performance on the "Why" component—traditionally difficult due to variability and low lexical redundancy—substantiates its superior document-level reasoning.
Ablation analysis demonstrates that removing contrastive loss for the GNN, simplifying fusion to elementwise addition, or degrading the document graph to a linear chain all degrade performance (the latter catastrophic), cementing the necessity of the gated multimodal integration and structural graph context for robust EE.
Generality Beyond Open-Domain: Closed-Domain Results
To estimate generality, MODEE-Base is evaluated on DocEE, a closed-domain document-level EE benchmark. MODEE-Base outperforms prior SOTA algorithms (BERT_Seq, Doc2EDAG, BERT_QA, Ontology_QA) with a substantial improvement in harmonic mean (HM) F1: 68.1% vs. next best 64.3%. This underscores the model’s flexibility and adaptability across both open- and closed-domain settings.
Technical Implications
MODEE introduces several notable advancements:
- Multimodal Fusion for EE: Attention-based gating integrates semantic (LLM) and structural (token-level graph) cues, addressing context fragmentation and long-range dependencies.
- Contrastive Training for Semantic Clustering: Supervised contrastive loss in the GNN clusters same-class 5W arguments, improving variable-length, sparsity-prone argument detection—especially for challenging fields like "Why".
- Graph-based Reasoning and End-to-End Generation: Unlike prior multi-stage or rigid pipeline systems, MODEE infers event arguments in a single generative sweep, conditioned on rich multimodal embeddings, facilitating backpropagation and holistic optimization.
Limitations and Areas for Future Work
MODEE is currently evaluated on single-event documents (i.e., one-event-per-document). Multi-event, multi-document settings—including cross-document event coreference—remain open. Additionally, higher document lengths may cause computational bottlenecks due to the complete graph construction, suggesting a need for graph sparsification or pruning strategies for scaling. While the architecture leverages T5’s encoder-decoder backbone, extension to decoder-only LLMs (common in current LLM paradigms) and incorporation of external modalities (e.g., images, audio) is left for future research.
Broader Theoretical and Practical Impact
While LLMs offer promising zero-/few-shot IE capabilities, this work suggests that their effectiveness in complex document-level event extraction saturates without explicit modeling of document structure and cross-token dependencies. The hybridization of linguistic and structural representations, along with contrastive learning, provides a new avenue for extending the reach of generative models in information extraction. Furthermore, MODEE's applicability to both open- and closed-domain regimes makes it a robust candidate for broad, schema-flexible knowledge base construction and summarization in dynamic, heterogeneous document collections.
Conclusion
MODEE constitutes a significant methodological step in event extraction. By integrating LLM representations, document-level token graphs, and attention-based gating with contrastive supervision, MODEE achieves robust, generalizable document-level event extraction—substantially outperforming both prompt-based and large fine-tuned LLMs. The implications extend to long-context NLP reasoning, cross-modal learning, and scalable knowledge extraction pipelines. Future work will need to extend these advances to multi-event, cross-document, and multimedia scenarios, and further optimize GNN integration for very large contexts.