- The paper introduces ViDiC, a novel framework and ViDiC-1K benchmark for fine-grained comparative reasoning in dynamic video pairs.
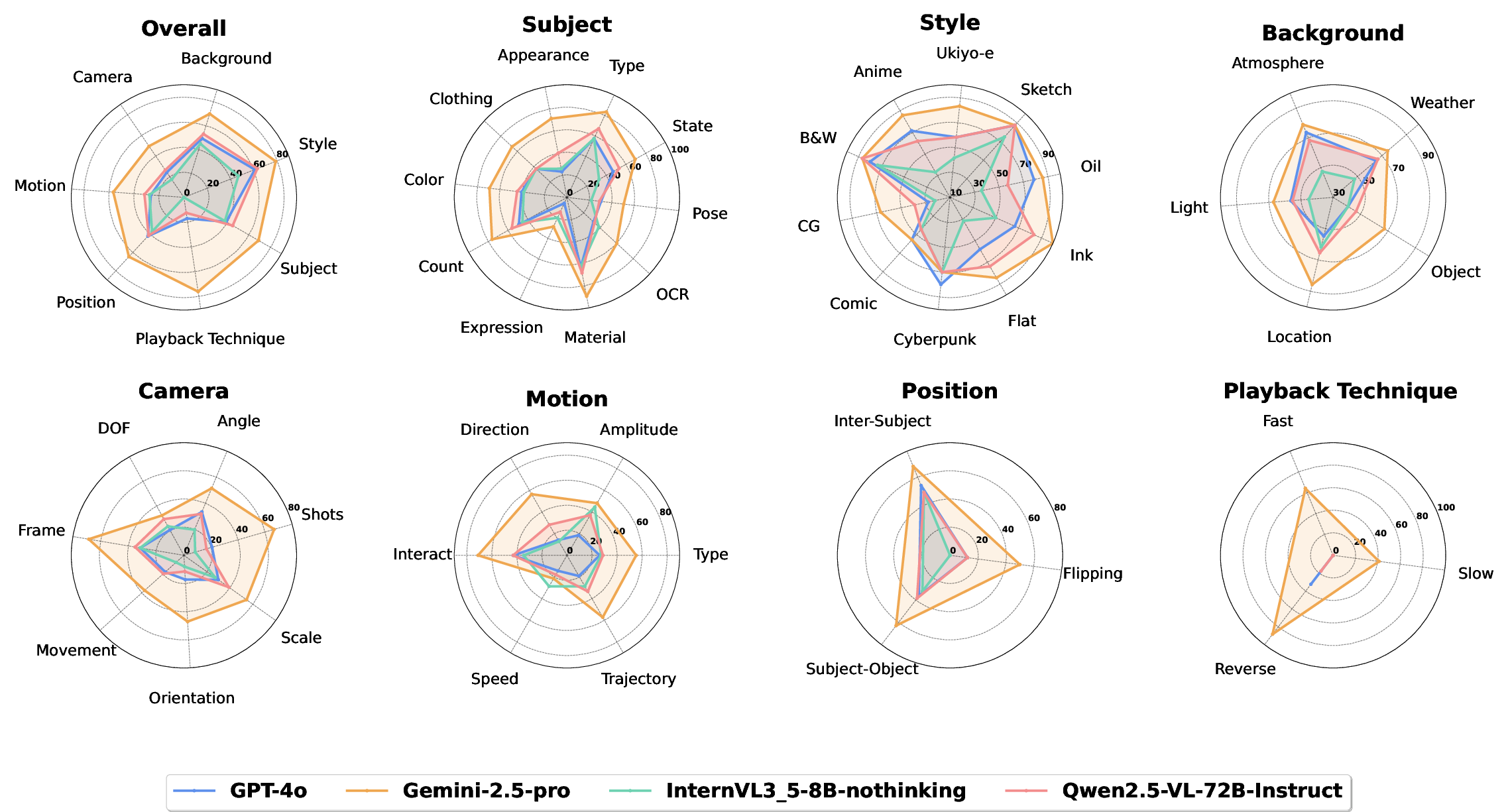
- It presents a dual-checklist evaluation protocol with detailed annotations across seven axes including Subject, Style, and Camera Work.
- Empirical results expose performance trade-offs in current multimodal models, highlighting challenges in temporal reasoning and factual consistency.
ViDiC: Advancing Fine-Grained Spatio-Temporal Comparison in Video-LLMs
The ViDiC framework systematically tackles a nuanced gap in the vision-language domain: factual, fine-grained comparative reasoning over pairs of dynamic video clips. Existing paradigms such as Image Difference Captioning (IDC) lack the capacity to capture temporally-evolving semantics, motion coherence, and the diversity of cinematographic manipulation pervasive in real-world content. The presented Video Difference Captioning (ViDiC) task—anchored by the ViDiC-1K benchmark—demands that multimodal models generate comprehensive natural language descriptions enumerating both similarities and differences across compositional, spatial, and temporal axes. Grounding the evaluation on a dual-checklist protocol, ViDiC isolates and quantifies capabilities critical for robust video understanding, edit analysis, semantic change detection, and content attribution.

Figure 1: Illustration of the seven core axes of variation in ViDiC, with Video Difference Captioning evaluated by matching model output to a fine-grained checklist.
Dataset Construction and Taxonomy
ViDiC-1K comprises 1,000 rigorously curated video pairs annotated with over 4,000 checklist items, stratified along seven principal categories: Subject, Style, Background, Camera Work, Motion, Position, and Playback Technique. Data sourcing follows a hybrid strategy. Public sources are complemented by synthetic variants generated via novel frame-splicing and compositional pipelines, enhancing coverage over subtle perturbations and edited semantics.


Figure 2: Schematic of frame-splicing for synthetic video pair creation, enabling precise control of inter-video differences.
The annotation protocol employs LLM-assisted drafting (Qwen3-VL-plus, Gemini-2.5-Pro), followed by manual expert validation. The resulting checklists deliver both similarity and difference queries per pair, with rigorous filtering to preserve only factual, non-redundant, and discriminative comparison points. The dataset captures diverse real-world and synthetic change types, with durations, resolutions, and topic breadth analyzed to guarantee broad generalization potential.

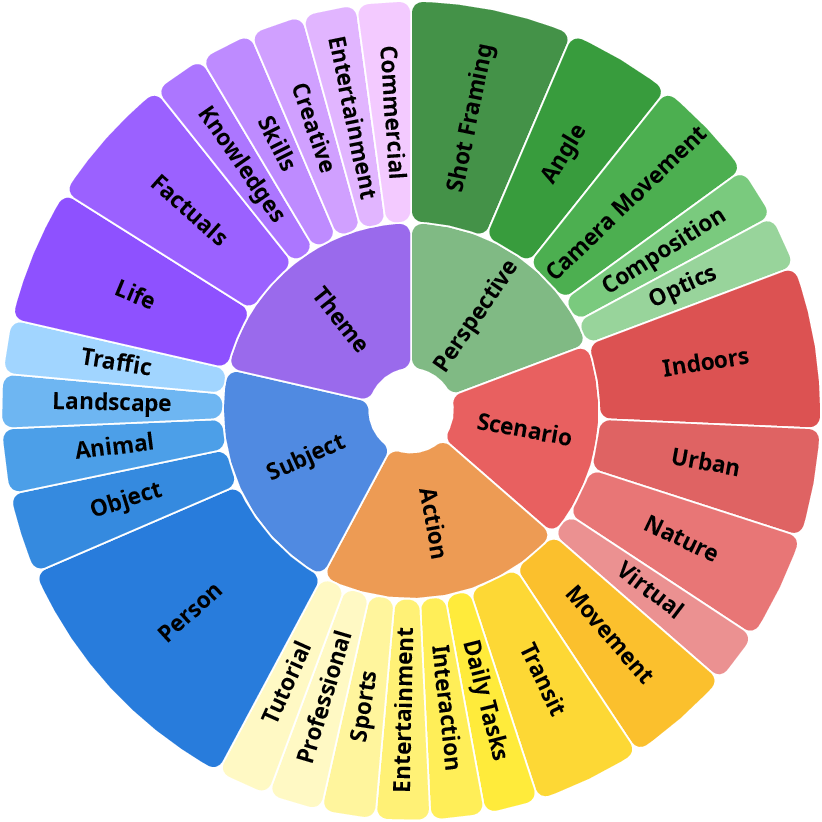
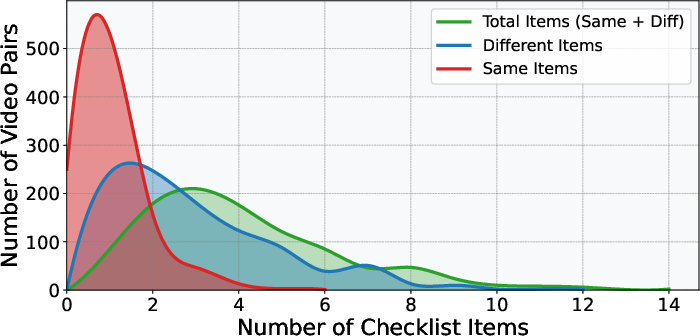
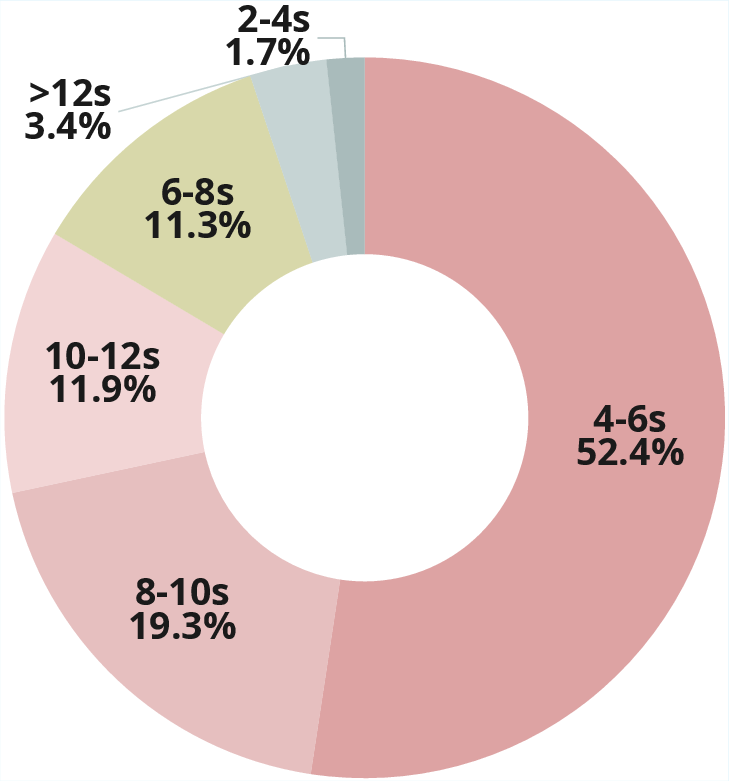
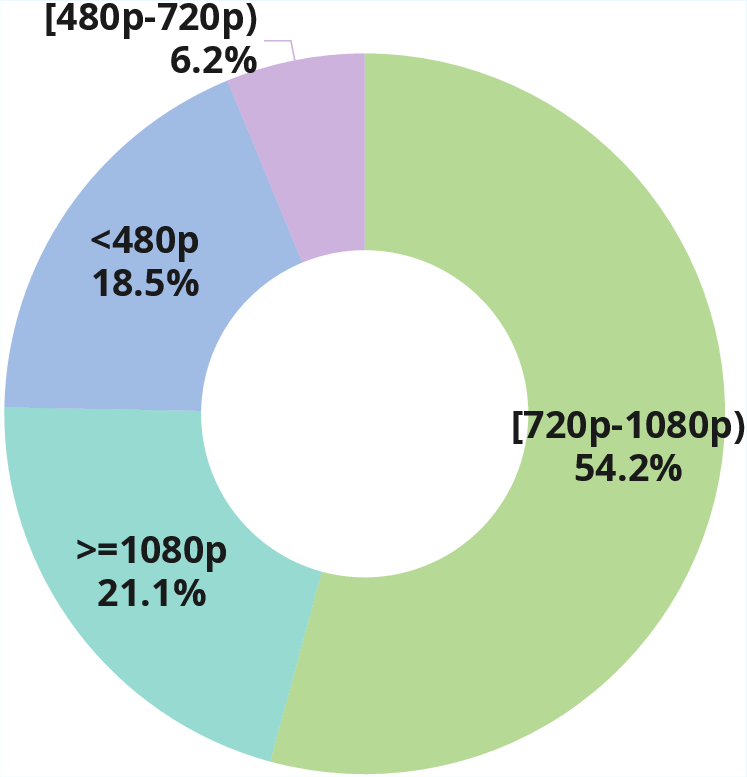
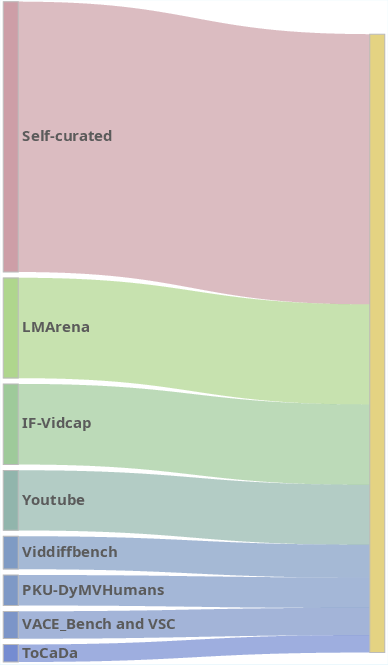
Figure 3: Multi-dimensional statistical overview of ViDiC-1K, highlighting category balance, checklist length, durations, resolution diversity, and data source distributions.
Evaluation Methodology
Recognizing the inadequacy of generic text-similarity metrics for the comparative captioning regime, ViDiC-1K leverages a human-verified binary checklist as ground truth. Model-generated captions are scored by a strong LLM-judge (GPT-5-Mini), which answers each checklist question based solely on the caption—without video access. Accuracy is measured by strict answer agreement against human annotations, calculated distinctly for similarity (penalizing hallucinations over omissions) and difference questions (penalizing omission or incorrect differentiation).
This dual-checklist protocol promotes assessment granularity and interpretability, decoupling coarse narrative overlap from factual comparative precision.
Benchmarking Results and Model Insights
Nineteen state-of-the-art proprietary and open-source multimodal LLMs were evaluated. Systematic trends emerge:
Fine-Grained Category and Robustness Analyses
ViDiC-1K reveals nuanced challenges masking beneath aggregate metrics. OCR, video reversal, and subtle compositional changes are recurrent failure points. Sensitivity analysis demonstrates:
- Frame count: Moderate temporal granularity (e.g., 32 frames) optimally balances context with computational tractability.
- Spatial fidelity: Performance scales with increased resolution, underscoring VLM limitations in low-fidelity conditions.
- Visual augmentations: Blurring, noise, and saturation collectively elevate Similarity accuracy—by suppressing hallucinated distinctions—while impairing the recognition of subtle differences inherent to the Difference metric.
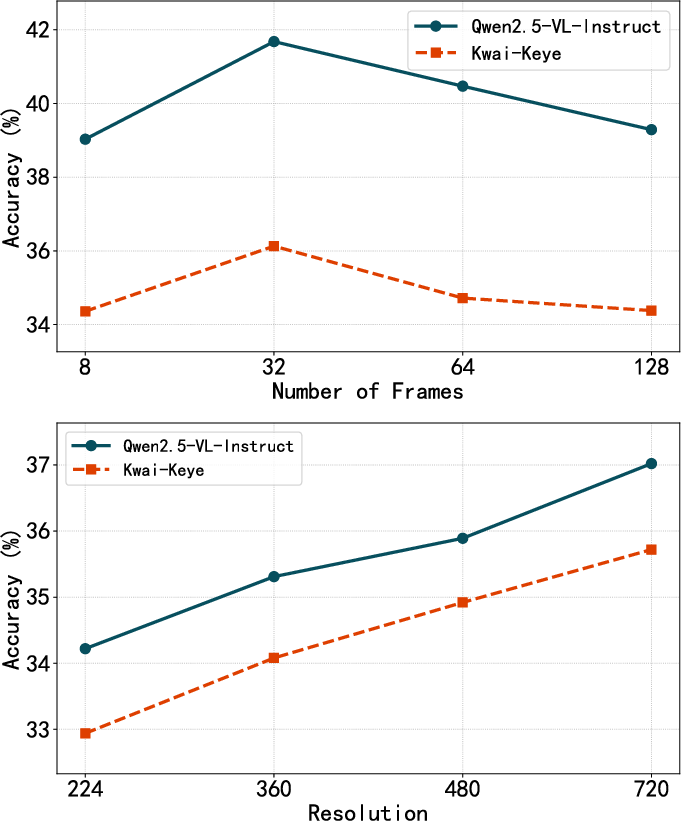

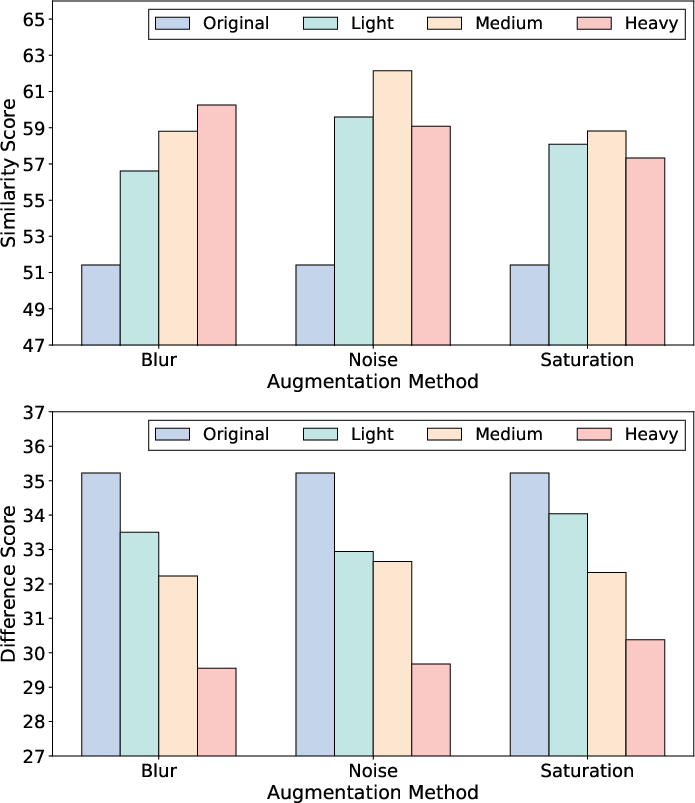
Figure 5: Impact of frame count, spatial resolution, and visual augmentation intensity on per-category model accuracy, with quantitative and qualitative visualizations.
Error Case Inspection
Systematic error analysis highlights three dominant failure patterns: hallucination of non-existent differences, logical inconsistency within or between captions, and incomplete or vague descriptions of salient differences. The reliance on “Thinking” mode exacerbates hallucination on inherently similar content. Many errors arise from failures in temporal reasoning, compositional scene grounding, and factual consistency under viewpoint or stylistic change.

Figure 6: Representative failure cases where models hallucinate, omit, or mischaracterize critical comparative details between paired videos.
Annotation and Curation Protocol
To achieve benchmark quality, the pipeline applies an exacting multi-phase filtration, combining automated temporal gates, manual adversarial checks, and a final expert interface for resolving ambiguities. Annotators systematically validate video dynamics, annotation rationality, and the factual alignment of answer keys with corresponding video content.
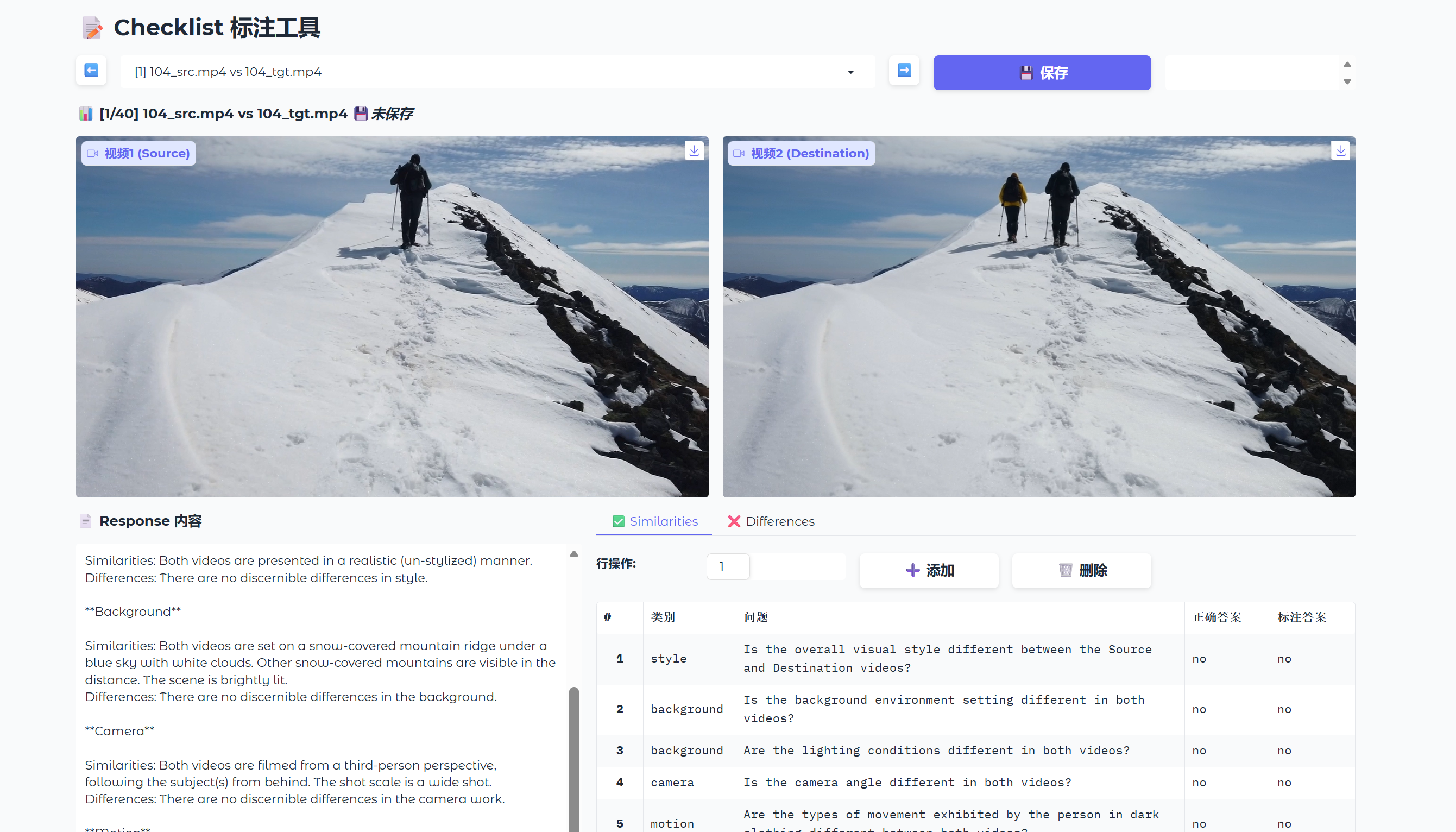
Figure 7: Custom annotation interface supporting multi-modal checklist verification and sample quality assurance.
Implications and Future Research Directions
ViDiC-1K directly exposes substantive deficiencies in the ability of current vision-LLMs to perform factual, compositional comparative reasoning over multi-modal dynamic content. The mechanical contrast with traditional video editing evaluation—focused on edit execution rather than edit comprehension—establishes ViDiC as a necessary complement for real-world deployment, especially in high-precision, audit-critical domains such as content forensics, intelligent video production, legal verification, rehabilitation, scientific monitoring, and semantically-aware surveillance.
Theoretical implications include a need for models supporting compositional temporal reasoning, spatial-temporal token alignment, view-consistent feature fusion, and robust discrimination under style or scenario variance. Practically, ViDiC-1K offers a fertile testbed for development of model pre-training protocols, synthetic data scaling, weak-to-strong supervision transfer, and reasoning-guided architecture innovations in multimodal AI.
Projected future directions involve scaling ViDiC to training magnitude for instruction-tuning, diversifying change axes, and integrating open-ended dialog benchmarks to further stress model compositionality.
Conclusion
ViDiC: Video Difference Captioning is a foundational contribution, delivering an indispensable benchmark and rigorous protocol for comparative video-linguistic reasoning. Empirical results underscore significant gaps in the spatio-temporal understanding and factual captioning capacities of modern MLLMs. The structured dual-checklist evaluation, fine-grained annotation, and category-diverse data curation position ViDiC as a reference suite for the next generation of multimodal intelligence research.