- The paper proposes a novel transformer-based detector that integrates a Coverage-Maximizing Sparse Encoder with a Global-Local Decoupled Decoder for efficient small object detection.
- The method employs an iterative soft-subtraction greedy algorithm for optimal patch selection, achieving up to 10× faster inference and notable mAP improvements on STAR and SODA-A datasets.
- Empirical results demonstrate a 2.8% mAP boost and robust performance under strict computational constraints, validating the effectiveness of sparse perception in UHR remote sensing.
Efficient End-to-End Small Object Detection in UHR Remote Sensing Imagery: UHR-DETR
Motivation and Challenges in Ultra-High-Resolution Detection
Ultra-high-resolution (UHR) remote sensing imagery has become prevalent due to advances in Earth observation. These images span spatial extents orders of magnitude larger than previous benchmarks, creating a unique detection dilemma: maintaining full-resolution for small object detection imposes extreme memory and compute overhead, while conventional strategies such as downsampling or rigidly tiling with sliding windows erase small objects or obliterate macroscopic context. The focal problem is the simultaneous need to preserve fine-grained details for abundant, densely-distributed small objects across vast backgrounds, under realistic hardware constraints.
UHR-DETR Architecture Overview
The UHR-DETR framework introduces an end-to-end transformer-based detector optimized for UHR inputs. It is architected around two core modules: (1) a Coverage-Maximizing Sparse Encoder, and (2) a Global-Local Decoupled Decoder. This design enables selective, context-aware feature extraction, focusing computation on spatially-informative regions while holistically integrating both global and local information for robust small object detection.
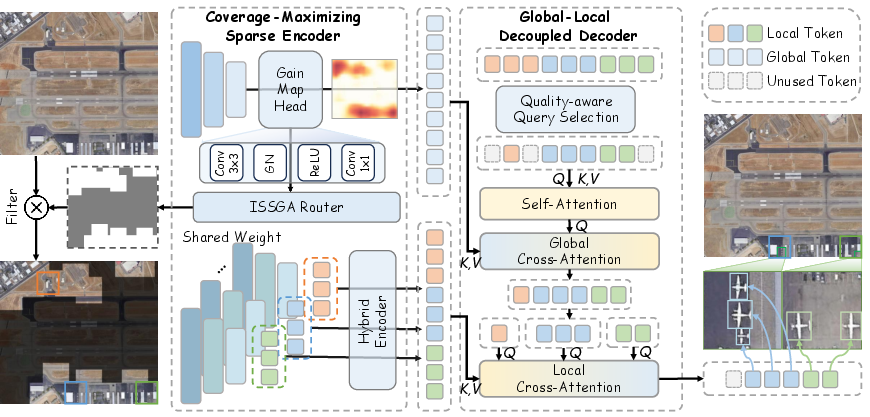
Figure 1: Overall architecture of the proposed UHR-DETR, showing the Coverage-Maximizing Sparse Encoder and Global-Local Decoupled Decoder, and their respective information flow.
Coverage-Maximizing Sparse Encoder
Rather than processing the full-resolution input, the encoder performs an initial global pass to estimate object density using a lightweight backbone network. An object-aware Gain Map is derived to quantitatively score the informativeness of all possible regions. Patch selection is then formulated as a geometric maximum coverage problem—efficiently approximated by a novel iterative soft-subtraction greedy algorithm (ISSGA)—producing K high-value patches that maximize expected object coverage while minimizing redundancy.
Global-Local Decoupled Decoder
Object queries are refined via a two-stage hierarchical attention mechanism. First, a global cross-attention operation injects macroscopic context by allowing queries to assimilate holistic scene priors. This is followed by local cross-attention restricted to the fine-grained tokens from the selected patches, yielding precise detailed predictions. This global-local decoupling resolves semantic ambiguities typical in isolated patches and ensures the preservation of critical contextual cues dispersed over the UHR canvas.
Sparse Perception and Coverage-Optimal Patch Routing
The encoder gains efficiency by dynamically routing compute only to regions likely to contain small objects, informed by the Gain Map. The ISSGA introduces spatially-aware soft suppression to avoid sampling redundant patches and to effectively cover clustered objects.
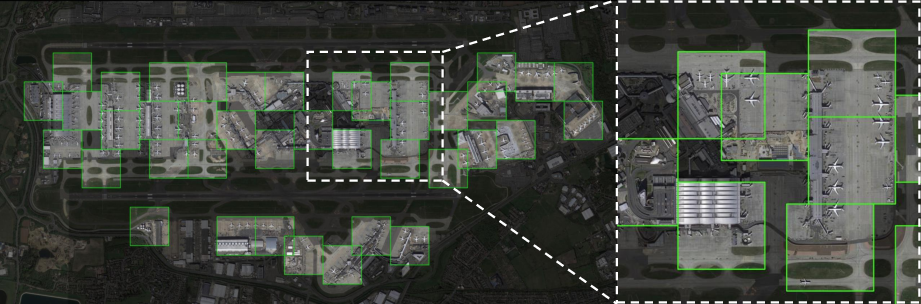
Figure 2: Visualization of dynamic patch selection; green boxes highlight patches adaptively selected to maximize object coverage around dense regions while suppressing computation on sparse background areas.
Quantitative analysis demonstrates the efficiency of this allocation:

Figure 3: (a)-(d): Statistical analysis of object coverage per image, cumulative coverage over the dataset, coverage versus patch budget K, and marginal gain per patch. The allocation efficiently saturates object coverage with moderate K, exhibiting diminishing returns consistent with set cover theory.
Empirical Results and Comparative Evaluation
UHR-DETR consistently surpasses established baselines across the STAR (8192×8192) and SODA-A (9600×9600) datasets. Notable empirical results include:
- On the STAR dataset, UHR-DETR delivers a 2.8% mAP boost and ≈10× faster inference versus sliding window RT-DETR and achieves a 4.2 mAP margin over other state-of-the-art UHR detectors for small objects.
- On SODA-A under 9600×9600 settings, it achieves mAP 53.3% with APS (small object AP) 30.9%, and maintains the highest efficiency among competitive approaches.
- Patch selection ablation shows the linear soft-subtraction strategy outperforms both rigid suppression (NMS) and Gaussian soft subtraction in mAP and APS.
These results validate both the efficiency and efficacy of the sparse perception paradigm, especially under strict 24GB GPU memory ceilings.
Visualization of Sparse Detection Results
High-resolution detection visualizations illustrate the effectiveness of the method in localizing densely packed small objects, maintaining high accuracy even in massive scenes.
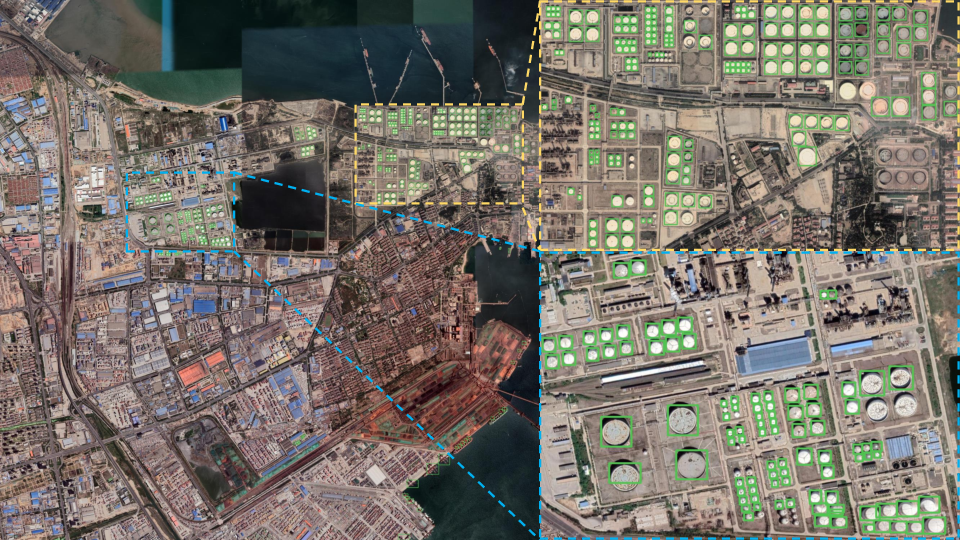
Figure 4: UHR-DETR detection results in a prototypical gigantic scenario, with zoom-in panels highlighting precise localization of crowded small objects and robust background suppression.
Theoretical Implications and Methodological Advances
UHR-DETR’s reliance on regional informativeness rather than explicit proposal or density maps avoids catastrophic localization errors from early-stage downsampling and weakens dependency on highly discriminative early features. The global-to-local query refinement directly addresses the longstanding issue of fragmented context in patch-based frameworks. From an optimization perspective, the synergy between the LPM (Local Peak Margin) loss and ISSGA ensures both the precise identification of valuable regions and coverage-optimal routing.
The architecture demonstrates how combinatorial optimization principles (specifically set cover surrogates) can be embedded in vision backbones, resulting in adaptive, resource-efficient detectors for massive-scale settings.
Limitations and Future Directions
UHR-DETR’s computational advantage degrades in scenarios with uniform, homogeneously dense object distributions—where no sparse clustering exists for efficient patch allocation. In these cases, the dynamic patch selection may approach the inefficiency of exhaustive sliding window methods. Integrating adaptive resolution control or further multi-scale fusion could improve applicability to such degenerate cases. Additionally, global context injection via cross-attention could be further formulated as a learnable dynamic mechanism to enhance flexibility across scene geometries.
Conclusion
UHR-DETR establishes an efficient, end-to-end solution to the challenging problem of small object detection in UHR remote sensing images. By introducing a coverage-optimal, sparse perception module, and a hierarchical decoder which systematically unifies macroscopic and microscopic information, it enables a new class of high-performance, resource-viable large-scale detectors. This work opens the path for future research on set cover-based dynamic routing, adaptive hierarchical aggregation, and context-integrated end-to-end perception pipelines for large-area vision applications.
Reference:
"UHR-DETR: Efficient End-to-End Small Object Detection for Ultra-High-Resolution Remote Sensing Imagery" (2604.21435)

