Decoupled DiLoCo for Resilient Distributed Pre-training
Abstract: Modern large-scale LLM pre-training relies heavily on the single program multiple data (SPMD) paradigm, which requires tight coupling across accelerators. Due to this coupling, transient slowdowns, hardware failures, and synchronization overhead stall the entire computation, wasting significant compute time at scale. While recent distributed methods like DiLoCo reduced communication bandwidth, they remained fundamentally synchronous and vulnerable to these system stalls. To address this, we introduce Decoupled DiLoCo, an evolution of the DiLoCo framework designed to break the lock-step synchronization barrier and go beyond SPMD to maximize training goodput. Decoupled DiLoCo partitions compute across multiple independent learners'' that execute local inner optimization steps. These learners asynchronously communicate parameter fragments to a central synchronizer, which circumvents failed or straggling learners by aggregating updates using a minimum quorum, an adaptive grace window, and dynamic token-weighted merging. Inspired bychaos engineering'', we achieve significantly improved training efficiency in failure-prone environments with millions of simulated chips with strictly zero global downtime, while maintaining competitive model performance across text and vision tasks, for both dense and mixture-of-expert architectures.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
In simple terms: what is this paper about?
This paper is about making the training of very large AI models (like chatbots) more reliable and efficient when using thousands or even millions of computer chips. The authors introduce a new way to train called “Decoupled DiLoCo,” which keeps training going even if some machines slow down or fail, without hurting the model’s final quality.
What questions were the researchers trying to answer?
- How can we keep training running smoothly when some machines are slow or crash?
- Can we reduce the waiting and talking between machines so they spend more time actually learning?
- Is it possible to do this without damaging the model’s accuracy on language and vision tasks?
- Will this work for different kinds of models, including those with many “experts” (Mixture-of-Experts)?
- Can we make use of extra computers that come and go (like borrowing spare capacity) without causing delays?
How did they try to solve it? (Easy explanation of the method)
Think of training a giant model like a big group project:
- The usual way (classic “SPMD” training) is like everyone writing the same essay together, step-by-step. After every sentence, everyone must stop and agree on the exact words before continuing. If one person’s keyboard breaks, the whole group stops.
- Earlier work called “DiLoCo” improved this by having everyone work a few steps locally and then synchronize occasionally. That cut down how often they had to stop, but they still had to pause together at the same times.
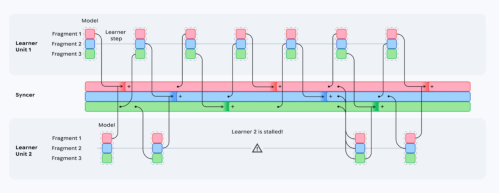
- Decoupled DiLoCo goes further: the team splits into several independent groups (“learners”) that each keep writing locally. A central “synchronizer” (like a teacher) collects pieces of their work and merges them. Crucially, the groups don’t wait for each other—they keep going.
How that works in practice:
- Split the model into “fragments” (like chapters). Each learner trains its own copy of the model and, every so often, sends just one fragment to the synchronizer.
- Minimum quorum: the synchronizer doesn’t wait for everybody. It waits for “enough” learners (say, K of them), then merges those fragments and sends back an updated version. If some learners are late or offline, training still continues.
- Grace window: if there’s a little extra time, the synchronizer waits briefly to include a few more learner updates, improving the quality of the merge without slowing things down.
- Token-weighted merging: learners that processed more data (tokens) since their last update get a bigger say in the merge, so the most helpful work counts more.
- Smarter averaging: the synchronizer uses a careful merging rule (a more stable way to combine updates) so the global model stays on track.
- Chaos engineering: the team repeatedly “pretends” machines fail (pulling the plug in a simulation) to test if training keeps going. They model scenarios with up to millions of virtual chips and lots of interruptions.
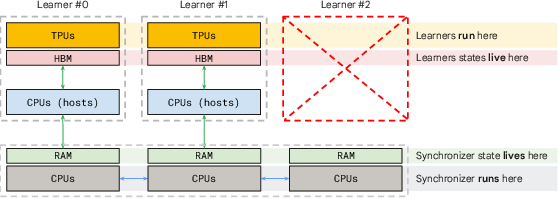
- System design: learners run the heavy training on accelerators (like TPUs/GPUs); the synchronizer runs on stable CPUs and does light-weight combining. Because learners are independent, a failure in one doesn’t stop the rest.
Also, “scavenging” means they can temporarily add extra learners when spare computers are available and remove them later—training just adapts without big pauses.
What did they find, and why is it important?
Main results:
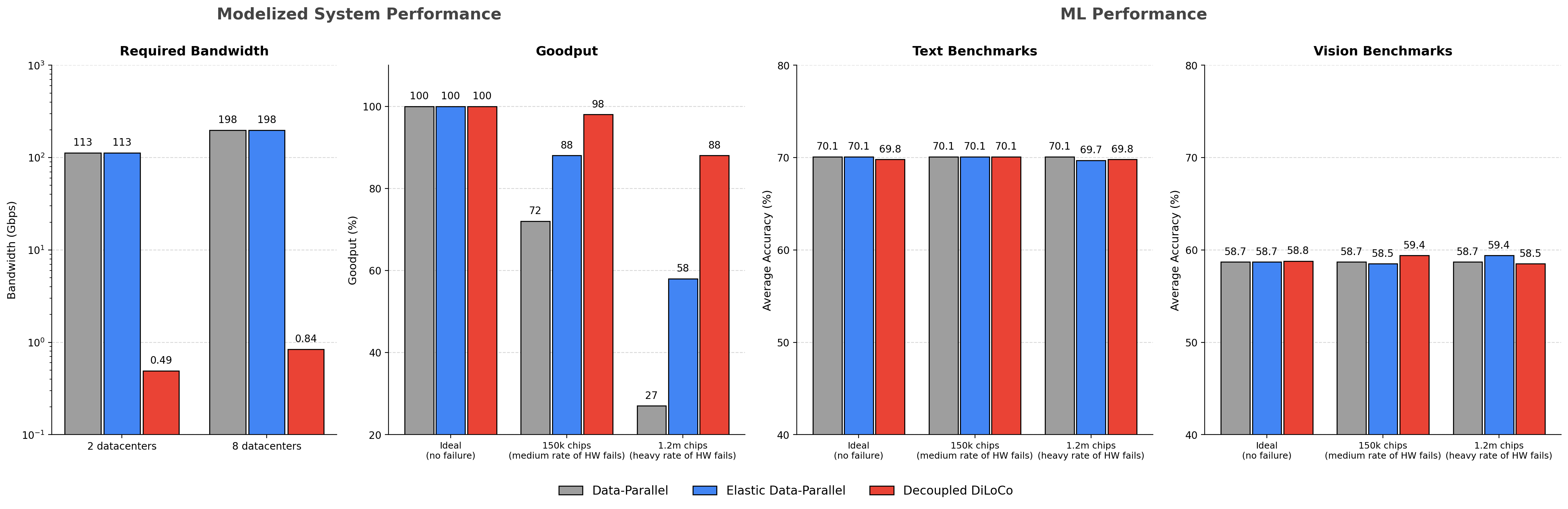
- Much higher “goodput” and uptime: Goodput is the percentage of time doing useful training work. With the traditional approach, goodput drops sharply when many machines fail or slow down (e.g., to about 40–60% in tough cases). With Decoupled DiLoCo and enough learners (like M=8 or 16), goodput stays very high (often above 90%), and uptime (time actually stepping) can reach nearly 100%, meaning the system basically never stops.
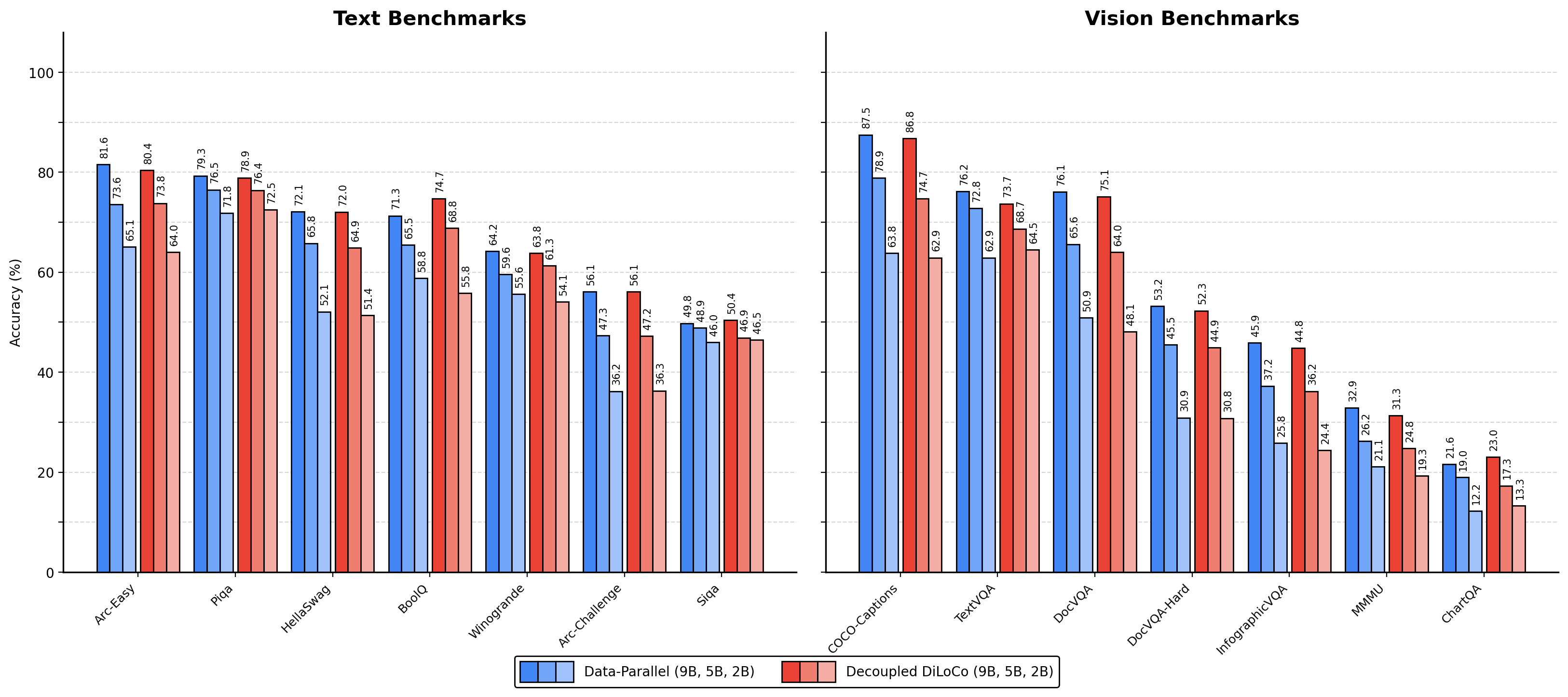
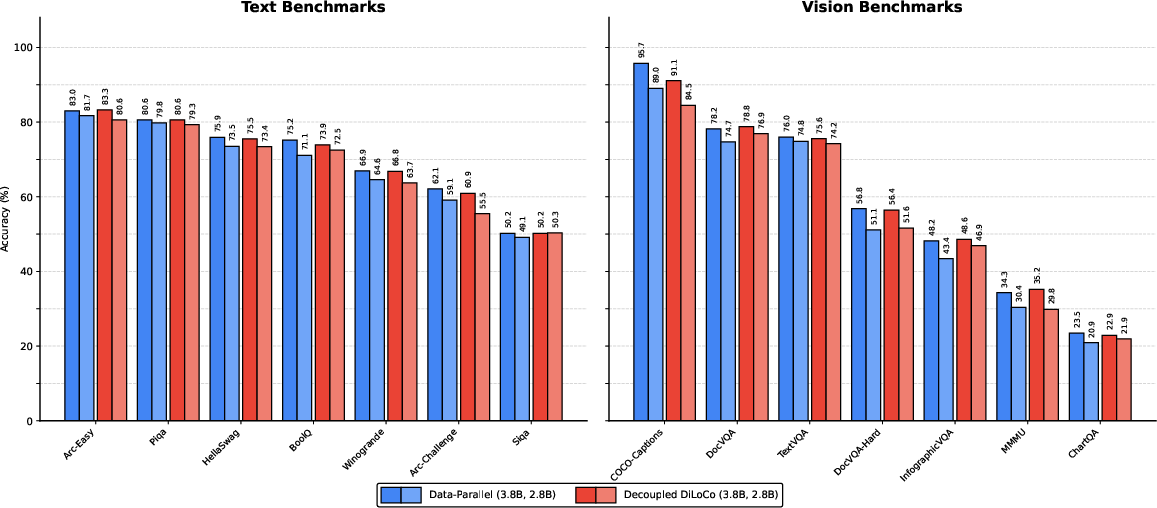
- Strong model quality: Despite being asynchronous, models trained with Decoupled DiLoCo perform about as well as models trained the old way on both language and vision benchmarks. This held true for both standard “dense” models and Mixture-of-Experts models.
- Lower bandwidth pressure: Because learners send only fragments at staggered times and don’t need to synchronize the whole model every step, the system uses much less communication bandwidth—helpful at large scales.
- Works with “chaotic” conditions: Even under aggressive simulated failures (machine interruptions happening very often), training stays efficient and model performance remains competitive.
- Scavenging speeds up training: When extra machines become available temporarily, Decoupled DiLoCo takes advantage of them to finish sooner, without hurting accuracy—and with fewer slowdowns than the classic approach.
Why this matters:
- It makes training huge models faster and more reliable, especially in real-world conditions where machines aren’t perfect.
- It reduces wasted time and cost, squeezing more value out of expensive hardware.
- It supports training across different types of machines (even older ones) and across different locations.
- It opens the door to training even larger models without being blocked by rare (but inevitable) hardware hiccups.
What’s the big takeaway?
The paper shows that you don’t need every machine to be perfectly in sync at all times to train great models. By letting independent learners work locally and merging their progress smartly and asynchronously, Decoupled DiLoCo keeps training moving through failures, cuts communication costs, and preserves model quality. This approach could make future large-scale AI training more robust, faster, and more affordable, especially as we push toward even larger models and more complex training setups.
Knowledge Gaps
Below is a single, concrete list of knowledge gaps, limitations, and open questions that remain unresolved by the paper; each item is phrased to enable actionable follow-up work.
- Convergence theory: No formal analysis or bounds for the proposed fully asynchronous, fragment-wise outer optimization with staleness, token-weighted aggregation, and grace windows; need convergence guarantees relative to synchronous DP and prior DiLoCo variants.
- Optimizer state semantics on fragment overwrite: Unclear how inner optimizer (e.g., AdamW) moments are handled when a fragment is replaced mid-training; need policies (reset, partial merge, bias correction) and their stability implications.
- Learner recovery details: The mechanism by which a long-failed learner “catches up” (state transfer across fragments, optimizer state reconciliation, bandwidth/time costs) is not specified; correctness and performance of recovery are unknown.
- Syncer reliability: The CPU-based syncer is a potential single point of failure; no redundancy, failover, or strong consistency protocols described for syncer shards; need fault-tolerant designs and recovery procedures.
- Syncer scalability: Lack of scaling analysis of syncer CPU memory/compute vs model size, number of fragments P, learners M, and outer optimizer state; need capacity planning and sharding limits, especially for frontier-scale models.
- Network characterization: No quantitative DCN traffic measurements (avg/peak bandwidth, tail latencies), congestion impact, or cross-region behavior under bursty/asynchronous update patterns; need detailed profiling.
- Weighting function validation: The proposed w = tokens × (tokens/steps) lacks empirical/theoretical justification; need ablations vs alternatives (tokens-only, steps-only, loss- or gradient-norm-weighted, variance-aware, normalized weights) and analyses under variable sequence lengths and MoE sparsity.
- Robust aggregation under faults: No defense against outlier or corrupted learner updates (e.g., silent data corruption, misconfiguration, adversarial learners); need robust aggregators (median, trimmed-mean, Krum), anomaly detection, and checksums.
- Grace-window control: No stability analysis or control policy for adaptive grace window and quorum size K under varying bandwidth/compute; need guarantees on maximum staleness and utilization without oscillations.
- Staleness management: No explicit staleness metrics, thresholds, or downweighting policies for overly stale updates per fragment; need bounds and drop/decay strategies with impact on convergence.
- Fragmentation policy: Only “balanced tensor fragmentation” is explored; need studies on grouping interdependent parameters (e.g., LayerNorm weights, tied embeddings), co-synchronization sets, and adaptive fragment scheduling based on parameter drift.
- Cross-fragment consistency: Partial fragment overwrites can create inconsistencies (e.g., weight decay coupling, paired parameters, optimizer state coupling); need safeguards or atomic multi-fragment updates for sensitive parameter groups.
- RDA merge method: Radial-Directional Averaging is under-specified; missing theoretical motivation, hyperparameters, and comparisons to alternatives (simple average, EASGD, Yogi/Adam as outer optimizers) across models and scales.
- Hyperparameter tuning: No systematic method for selecting H, P, τ, K, grace-window limits, or outer LR/momentum; need auto-tuning guided by divergence, bandwidth, and failure rates, and sensitivity analyses.
- Data heterogeneity: Fixed per-learner shards with asynchronous updates risk data skew (fast learners dominating); need re-sharding, curriculum, or weighting by dataset distribution or loss to avoid bias.
- Sample efficiency: Comparable downstream scores at equal tokens do not quantify any efficiency gap; need loss-vs-tokens and loss-vs-time curves under varying failure rates to measure sample and time efficiency versus DP.
- Learning-rate schedules: How global step t and per-learner tokens map to inner/outer LR schedules (warmup/decay) under asynchronous progress is unspecified; need principled scheduling tied to tokens or effective updates.
- MoE specifics: Impact of asynchronous fragment updates on router/expert parameters, expert load-balancing, and capacity constraints is not analyzed; weighting should reflect per-expert activation and token flow.
- Memory/copy overheads: Frequent host RAM snapshots and CPU syncer optimizer states may not scale to 100B+ models; need measurements and alternatives (delta updates, zero-copy, RDMA), and memory budgeting.
- Update compression: Full-precision fragment transfers are used; potential gains from quantization, sparsification, error feedback, or delta encoding are unexplored.
- Application point semantics: Learners apply fragment updates upon receipt, potentially mid-step; need safe application points or transactional update semantics to avoid step-level inconsistencies and optimizer mismatch.
- Checkpointing and replay: Snapshot frequency, overhead, and correctness guarantees of Chandy–Lamport snapshots and deterministic replay under asynchrony are not detailed; need validation under non-FIFO and packet loss.
- Failure model realism: Simulations assume Poisson chip failures and constant chip speeds; missing evaluations with correlated failures, network partitions, heavy-tailed disruptions, bandwidth volatility, and cross-region asymmetries.
- Cross-region scavenging: Claims of easy geo-distributed training lack empirical latency/staleness/quality measurements and cost trade-offs under realistic WAN conditions.
- Security for scavenged/heterogeneous compute: No treatment of authentication, encryption, or trust boundaries for learners; need protocols to prevent data/model exfiltration and malicious contributions.
- Fairness/starvation: Policies ensuring slow learners still contribute (and are not perpetually downweighted) are unspecified; need fairness constraints and periodic inclusion mechanisms.
- “Missed updates” semantics: The mechanism to apply missed global updates to a rejoining learner without double counting or violating causality is not formally described; vector-clock-based reconciliation needs specification and proofs.
- Evaluation scope: Experiments focus on 2–5B models and a limited benchmark set; generalization to frontier-scale models, long-context, code/math, and multilingual tasks remains untested.
- MFU and step-time breakdowns: The “no MFU regression” claim is not quantified; need profiling of compute–communication overlap, MFU, and per-step time components vs DP across regimes.
- Energy and cost: No analysis of energy/$ per token, including CPU syncer overhead and extra host-memory copies; need holistic cost-efficiency evaluation.
- Interplay with other parallelism: Compatibility and performance with tensor/sequence/pipeline parallelism and optimizer sharding (e.g., ZeRO) at very large scales are not addressed.
- Hyperparameter portability: It is unclear whether a single inner/outer optimizer configuration transfers across different M, K, and failure regimes; need practitioner guidelines and stability regions.
- Reproducibility variance: Asynchrony may increase run-to-run variance; need statistical repeatability studies, seed handling, and confidence intervals for reported metrics.
- Open-sourcing and artifacts: Absent public release of code, configs, and failure simulation tools limits independent verification and adoption; reproducibility remains constrained.
Practical Applications
Practical Applications of “Decoupled DiLoCo for Resilient Distributed Pre-training”
Below are concrete, real-world applications that leverage the paper’s findings (asynchronous learners, central syncer, fragment-wise outer optimization, adaptive quorum/grace window, token-weighted merging, RDA merging, chaos-engineering simulation, and scavenging). Each item includes sector tags, potential tools/workflows, and the key assumptions/dependencies that affect feasibility.
Immediate Applications
- Resilient LLM pre-training at scale (Industry, Academia; Sectors: software, cloud/HPC)
- What: Replace monolithic SPMD/DP with Decoupled DiLoCo to isolate failures to a learner, maintain near-100% system uptime, and recover goodput under frequent interruptions.
- Tools/Workflows: “Syncer microservice” (CPU-only), learner partitioning into fragments (e.g., P≈24), OuterOpt with RDA, K≈1 plus adaptive grace window, vector clocks + Chandy-Lamport snapshots; rollout playbooks for converting DP jobs into M independent learners.
- Assumptions/Dependencies: Support for background fragment exchange over DCN; instrumentation for tokens/steps per fragment; inner-optimizer that tolerates asynchronous fragment overwrites; reliable message passing and logging to enable deterministic replay.
- Cost- and carbon-efficient training via scavenging (Industry, Academia; Sectors: cloud, energy, finance)
- What: Opportunistically add/remove learners (preemptible or burst capacity) to reduce wall-clock under fixed FLOPs budgets; exploit regional time-of-day capacity/price.
- Tools/Workflows: “Scavenging scheduler” that spins up/down learners; carbon-aware placement policy; batch-size governance to keep token accounting consistent; goodput dashboards.
- Assumptions/Dependencies: Adequate DCN bandwidth for fragment sync; accounting to prevent double-counting tokens; cross-region egress cost acceptance; minimal compile-time overhead for new learners (recovery path).
- Geo-distributed, heterogeneous training that tolerates bandwidth and speed variance (Industry; Sectors: cloud/HPC, telecom)
- What: Train across heterogeneous hardware and regions without lock-step all-reduce; reduce peak bandwidth via fragment streaming.
- Tools/Workflows: “Heterogeneous Orchestrator” that forms learners from mixed accelerators; balanced tensor fragmentation; adaptive grace window to utilize slack; token/step-weighted merging.
- Assumptions/Dependencies: Sufficient DCN reliability; secure channel setup across regions; careful merge hyperparameters (RDA, OuterOpt LR/momentum) for stability.
- Chaos engineering for AI training reliability (Industry, Academia; Sectors: software/SRE, cloud)
- What: Institutionalize failure-tape generation, MTBI/MTBF modeling, and deterministic replay to harden training pipelines and quantify goodput/uptime.
- Tools/Workflows: “Failure tape generator” and “replay runner”; goodput and uptime SLOs; integration with incident response.
- Assumptions/Dependencies: Logging of vector clocks and non-deterministic events; reproducible build and data versions; tape storage and privacy controls.
- CPU-based Syncer-as-a-microservice to lower accelerator pressure (Industry; Sectors: software, cloud)
- What: Offload global aggregation/OuterOpt to durable CPU nodes; reduce HBM footprint and stabilize coordination.
- Tools/Workflows: Horizontal sharding by learner; fragment-wise all-reduce across syncer shards; autoscaling policies for syncer CPU pools.
- Assumptions/Dependencies: Low-latency DCN between learners and syncer; high availability for syncer (HA pair, checkpointing).
- Reliable MoE and dense training under failures (Industry, Academia; Sectors: software)
- What: Adopt Decoupled DiLoCo for both MoE and dense models with comparable downstream quality under aggressive failure rates.
- Tools/Workflows: MoE-aware fragmentation; stable OuterOpt configs; evaluation gates showing parity to DP baselines.
- Assumptions/Dependencies: Data sharding uniqueness; careful merge stability (RDA) with MoE router updates; compatibility with existing MoE libraries.
- Capacity planning and TCO optimization using goodput modeling (Industry; Sectors: finance, operations)
- What: Use the paper’s “goodput rule of thumb” and MTBI/MTBF models to size M (learners) and chips per learner for target uptime/cost.
- Tools/Workflows: “Goodput Planner” that evaluates trade-offs between M, H, τ, K, bandwidth, and failure rates; procurement decision support.
- Assumptions/Dependencies: Accurate MTBI estimates per fleet; realistic quorum and grace window timing; alignment with budget and SLA constraints.
- Multi-tenant datacenters: SLA-friendly training tiers (Industry; Sectors: cloud)
- What: Offer a resilient-training tier that absorbs preemptions/failures without downtime; expose goodput and uptime SLOs to customers.
- Tools/Workflows: Tiered SKUs (“Resilient Pretrain”), per-tenant syncer sharding, automated learner isolation, usage-based billing by effective tokens.
- Assumptions/Dependencies: Metering of useful-step time vs total time; fair-share scheduling; cost of cross-tenant network isolation.
- University/HPC lab co-ops for shared compute (Academia; Sectors: education, research computing)
- What: Pool intermittent campus clusters as learners; continue training through maintenance windows and partial outages.
- Tools/Workflows: Cross-site learner federation; nightly scavenging windows; snapshot/replay for reproducibility in publications.
- Assumptions/Dependencies: Cross-institution data transfer agreements; compliance with data licenses; standardized syncer endpoints.
- Carbon-aware scheduling “now” (Industry, Academia; Sectors: energy)
- What: Shift learner activity to low-carbon or low-price hours/regions; tolerate partitions without halts.
- Tools/Workflows: Carbon-intensity APIs feeding learner throttling; grace-window tuning to absorb network variability.
- Assumptions/Dependencies: Access to real-time carbon and price signals; policies for inter-region data movement.
Long-Term Applications
- Cross-organization collaborative pre-training (Privacy-aware) (Industry, Government, Academia; Sectors: healthcare, finance, public sector)
- What: Use decoupled learners at different institutions sharing updates to a central syncer without tight synchronization; privacy-enhanced merging pipelines for sensitive domains (e.g., clinical or financial text).
- Tools/Workflows: “Federated pretrain” with secure aggregation, TEEs/SMPC; differential privacy on outer gradients; audit trails via vector clocks.
- Assumptions/Dependencies: Strong privacy guarantees; legal agreements (data sovereignty, HIPAA/GDPR); encryption at rest/in transit; overhead of secure aggregation.
- Syncer-as-a-Service across clouds and accounts (Industry; Sectors: cloud, telecom)
- What: Managed, cross-account syncer for multi-cloud/sovereign setups, abstracting merging, RDA, and quorum control.
- Tools/Workflows: Public APIs for fragment push/pull; SLA for availability and data retention; observability.
- Assumptions/Dependencies: Inter-cloud peering and egress economics; standardized fragment schemas and OuterOpt APIs.
- Standardization of resilience metrics and chaos testing in AI SLAs (Policy, Industry)
- What: Codify goodput, uptime, and reproducible “chaos tapes” into procurement and regulatory checklists for foundation-model training.
- Tools/Workflows: NIST-like profiles; certification programs that verify deterministic replay under failure scenarios.
- Assumptions/Dependencies: Industry consensus on definitions; willingness to disclose reliability traces; privacy-preserving audit mechanisms.
- Grid-interactive, demand-response AI training (Industry, Government; Sectors: energy)
- What: Participate in demand-response markets by elastically modulating learner activity based on grid stress—without pausing global progress.
- Tools/Workflows: Grid API adapters; automatic M tuning and learner throttling; carbon-aware token budget managers.
- Assumptions/Dependencies: Regulatory approval; predictable economic incentives; robust forecasting of network and energy conditions.
- Edge/robotics continuous learning via asynchronous merging (Industry, Academia; Sectors: robotics, IoT)
- What: Extend the learner–syncer pattern to fleets collecting data in the wild; learners sync opportunistically; central server merges with token-weighted updates.
- Tools/Workflows: Lightweight fragment exchange over intermittent links; on-device token accounting; conflict-safe OuterOpt for non-IID data.
- Assumptions/Dependencies: Model sizes practical for edge; privacy and safety approval for autonomous data usage; convergence studies under extreme heterogeneity.
- Deep integration into mainstream ML stacks (Industry, Open-source; Sectors: software)
- What: Native support in PyTorch/JAX/TF/DeepSpeed/Ray Train for learners, syncer, RDA merge, adaptive quorum/grace window, and failure replay.
- Tools/Workflows: “DecoupledTrainer” APIs; one-click migration from DP; auto-tuners for H, τ, K based on bandwidth and failure logs.
- Assumptions/Dependencies: Community adoption; compatibility with pipeline/tensor parallelism; debugging and profiling tooling maturity.
- Privacy- and security-hardened merging (Industry, Academia; Sectors: healthcare, finance, public safety)
- What: Apply homomorphic encryption or TEEs to fragment exchange; add secure logging and verifiable computation for regulated domains.
- Tools/Workflows: Hardware-backed enclaves around syncer; post-quantum crypto channels; verifiable replay artifacts.
- Assumptions/Dependencies: Performance overheads; regulatory validation; hardware support footprint across sites.
- Multi-model, multi-task orchestration (Industry, Academia; Sectors: software, education)
- What: Share compute across several models/tasks by rotating fragments and learners; dynamic weighting by token utility/quality.
- Tools/Workflows: “Multi-model syncer” that tracks per-task tokens and quality; task-aware RDA variants; schedulers optimizing portfolio goodput.
- Assumptions/Dependencies: Interference management across models; fair allocation policies; sophisticated telemetry.
- Disaster-resilient national AI compute fabrics (Government, Academia; Sectors: public infrastructure)
- What: Stitch HPC centers and cloud regions into a resilient learner mesh able to withstand regional outages without halting training.
- Tools/Workflows: Sovereign syncer deployments; emergency routing; standardized snapshots and tapes for continuity-of-research.
- Assumptions/Dependencies: Inter-agency MOUs; network peering; data governance spanning jurisdictions.
- Formal guarantees and convergence theory for asynchronous fragment merging (Academia; Sectors: research)
- What: Theoretical analysis and verification frameworks for RDA, token-weighted merges, and quorum/grace dynamics under non-IID data and variable delays.
- Tools/Workflows: Open benchmarks, simulators, and proofs; reproducible failure tapes; standardized ablations.
- Assumptions/Dependencies: Access to large-scale simulators; community-maintained datasets and metrics.
- Fairness and accounting for shared/scavenged compute (Policy, Industry; Sectors: cloud, finance)
- What: Credit systems and fair-use policies for multi-tenant scavenging; transparency in who benefits from excess capacity.
- Tools/Workflows: Token-based accounting tied to learners; auditable metering of useful steps; cost-sharing contracts.
- Assumptions/Dependencies: Market mechanisms; customer trust; robust metering that cannot be gamed.
Notes on general feasibility across all applications:
- Empirical grounding: Paper reports parity in downstream performance (text and vision, dense and MoE) under aggressive failure simulations with significantly higher goodput and, in some cases, two orders of magnitude lower bandwidth than elastic DP.
- Operational readiness: Success depends on reliable DCN, robust checkpointing/replay, and careful merge hyperparameterization (RDA, OuterOpt). The defaults demonstrated (e.g., P≈24, H=P, τ≈2, K≈1 + grace window) are strong starting points but need tuning per environment.
- Data and privacy: Token-weighted merging requires accurate token accounting; cross-domain deployments may need privacy layers and legal agreements.
- Economics: Cross-region egress and CPU syncer resources affect cost; scavenging benefits hinge on access to discounted/preemptible capacity and tolerance for variable throughput.
Glossary
- Adaptive grace window: A short wait period the syncer uses to include more learner updates without stalling, improving sample efficiency under asynchrony. "by aggregating updates using a minimum quorum, an adaptive grace window, and dynamic token-weighted merging."
- All-reduce: A collective communication operation that aggregates values (e.g., sums gradients) across replicas and distributes the result back to all. "Thus, when using Streaming DiLoCo with all-reduce, issues such as stragglers and learner failures can significantly slow down or halt training entirely."
- Availability (A): In the CAP-style framing for training, the property that training continues despite hardware failures. "Availability (A): Training continues in the presence of hardware failures."
- Balanced tensor fragmentation: A partitioning strategy that groups tensors into similarly sized fragments to balance communication and reduce peak bandwidth. "We found that this strategy, which we refer to as balanced tensor fragmentation, maintained model quality compared to layer-based fragmentation strategies~\citep{douillard2025streaming}, while significantly reducing peak bandwidth."
- Bin-packing algorithm: A heuristic to pack items (tensors) into bins (fragments) to balance sizes; used here to form fragments. "We form the fragments via a greedy bin-packing algorithm, applied to individual tensors in the model."
- Blast radius: The scope of impact from a failure; minimizing it confines the effects to only part of the system. "we limit the “blast radius” of a hardware failure to a single learner."
- CAP theorem: A principle describing trade-offs between Consistency, Availability, and Partition tolerance in distributed systems; used as an analogy for training trade-offs. "Framing this analogously to the CAP theorem~\citep{brewer2000towards}, we argue the primary bottleneck of modern pre-training is a rigid adherence to parameter consistency."
- Chandy-Lamport distributed snapshotting algorithm: A classic protocol to take consistent global snapshots in distributed systems. "creating consistent global checkpoints via the Chandy-Lamport distributed snapshotting algorithm \citep{chandy1985distributed}"
- Chaos engineering: Systematically injecting failures to test and improve system resilience. "We apply chaos engineering~\citep{basiri2016chaos} principles to LLM pre-training, demonstrating that our framework maintains high availability and model quality, even under aggressive, continuous hardware failures."
- Consistency (C): In the training CAP-style framing, the property that all accelerators share a globally synchronized model state. "Consistency (C): Every accelerator maintains a view of a globally synchronized set of model weights."
- Data-center network (DCN): The interconnect across machines in a datacenter used here for transmitting parameter fragments and updates. "Learner workers communicate with the syncer by sending parameter fragments and receiving outer-optimized updates over the data-center network (DCN)."
- Data-parallel training (DP): A setup where model replicas process different data shards and aggregate updates synchronously. "Decoupled DiLoCo achieves comparable downstream performance to standard data-parallel training across various model and compute scales"
- Decoupled DiLoCo: An asynchronous distributed training framework that partitions computation into independent learners coordinated by a central syncer to maximize goodput. "We propose Decoupled DiLoCo, a distributed training framework that decomposes a global cluster into independent, asynchronous “learners”."
- Deterministic replay: Reproducing a nondeterministic run exactly by logging all nondeterministic events, for debugging and resilience. "logging of a nondeterministic training run to enable deterministic replay as discussed in Section~\ref{sec:tape_generation}"
- Device mesh: The logical arrangement of accelerators for parallel computation and communication. "which manages the resource allocation, device mesh construction, and inter-worker dataflow."
- DiLoCo: A distributed training method that reduces bandwidth via intermittent synchronization and an outer optimization step. "Recent distributed alternatives like DiLoCo~\citep{douillard2024diloco} and its streaming variant~\citep{douillard2025streaming} have successfully addressed communication bottlenecks by reducing bandwidth requirements through intermittent synchronization."
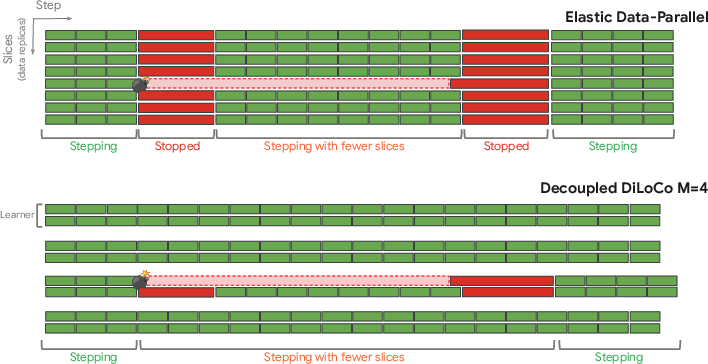
- Elasticity, slice-granularity: Dynamically resizing active hardware slices to adapt to failures or resource changes at fine granularity. "similar to the slice-granularity elasticity described by \citet{geminiteam2025gemini2p5}."
- Exponentiated Weibull distribution: A probability distribution used here to model repair/return times of failed chips. "after a delay sampled from an exponentiated Weibull distribution."
- FIFO channels: First-in-first-out message channels ensuring ordered delivery, used for progress coordination and snapshotting. "via message passing over FIFO channels where the sender attaches its current vector clock to each message"
- Fragment (parameter fragment): A partition of the model parameters used to stagger and reduce peak synchronization bandwidth. "Partition the model weights into sets (called fragments)"
- Goodput: The fraction of allocated compute time that performs useful training work (as opposed to being idle or stalled). "This simulation yields a goodput metric \citep{wongpanich2025machinelearningfleetefficiency}: the percentage of allocated cluster time actually spent executing useful steps;"
- HBM: High Bandwidth Memory on accelerators; here, avoiding extra copies reduces memory pressure. "without requiring extra model copies on HBM."
- Inner optimizer: The local optimizer (e.g., AdamW) that each learner uses between outer synchronizations. "each of the learners trains in parallel using an inner optimizer (e.g. AdamW) on distinct data shards"
- Iso-FLOPs regime: An experimental setting where total floating-point operations are held constant to compare strategies fairly. "We run our experiments in an iso-FLOPs regime where total compute usage is fixed;"
- Learner: An independent training group with its own model replica performing local steps asynchronously. "We train across learners, each with their own model copy ."
- Lock-step training: A regime where all replicas proceed synchronously, forcing global progress to wait for the slowest. "Streaming DiLoCo still requires lock-step training across learners."
- Mean time between failures (MTBF): Expected time between failures for the entire cluster; decreases with cluster size. "the mean time between failures (MTBF) of the entire cluster decreases proportionally as the number of chips increases:"
- Mean time between interruptions (MTBI): Expected time between interruptions for a single chip; used to parameterize failure simulations. "the mean time between interruptions (MTBI) per chip ($MTBI_{\text{chip}$)"
- Mixture-of-Experts (MoE): A model architecture routing tokens to specialized expert subnetworks to increase capacity efficiently. "for both dense and Mixture-of-Experts (MoE) architectures."
- Model Flops Utilization (MFU): The fraction of peak FLOPs the model achieves; a hardware efficiency metric. "While we omit Model Flops Utilization (MFU) for simplicity, our decoupled framework introduces no MFU regression."
- Minimum quorum (K): The smallest number of learners the syncer waits for before aggregating a fragment update. "the syncer only waits for a minimum threshold learners that successfully send their metadata"
- Nesterov momentum: A momentum variant of SGD that looks ahead for improved convergence; used as the outer optimizer. "SGD with Nesterov momentum~\citep{sutskever2013nesterov} greatly improves model quality compared to weight averaging"
- Outer gradient: The difference-in-parameters used as a pseudo-gradient for outer optimization at sync points. "We refer to as an outer gradient."
- Outer optimizer (outer optimization): The global optimizer that updates parameters using aggregated outer gradients across learners. "the syncer applies the outer optimizer (e.g., SGD with Nesterov momentum, L13) to derive an updated global fragment "
- Overlap (τ): The number of steps by which communication is delayed/overlapped relative to computation in streaming synchronization. "the learners can send and receive steps later with little change in model quality for small values of ."
- Parameter server architecture: A design where centralized servers (syncers) aggregate and distribute model updates to workers. "This naturally leads to a parameter server architecture, inspired by \citep{dean2012large}."
- Partition Tolerance (P): In the training CAP-style framing, the ability to continue despite network instability or delays. "Partition Tolerance (P): Training continues despite interconnect instability or communication delays."
- Pathways: The orchestration system managing resources, meshes, and dataflow for distributed training. "All workers are orchestrated by Pathways~\citep{barham2022pathways}, which manages the resource allocation, device mesh construction, and inter-worker dataflow."
- Radial-Directional Averaging (RDA): A merge method that averages norms and directions of outer gradients separately for stability. "We propose a modified merging operation, Radial-Directional Averaging (RDA) in which we separately average the norms and directions of outer gradients."
- Recovery (learner recovery): The process by which a failed/lagging learner obtains up-to-date state to rejoin training. "except in the special case of recovery, the process by which one learner obtains up-to-date state from another learner in order to rejoin after a long failure (see Section~\ref{sec:recovery})."
- Scavenging: Opportunistically adding temporary compute during training to accelerate progress without changing total FLOPs. "We exploit our decoupled framework to dynamically add compute resources, “scavenge”, on the fly during training."
- Sequence parallelism: A parallelization strategy splitting work along the sequence dimension. "Modern LLM pre-training relies on the tightly coupled single program, multiple data (SPMD) paradigm (e.g., data, tensor, and sequence parallelism)"
- Sharded (syncer shards): Partitioning the syncer into multiple shards, typically one per learner, for scalable aggregation. "The syncer is -way sharded across CPU-only replicas and performs the outer optimization step."
- Single program multiple data (SPMD): A model where all workers execute the same program on different data, often requiring synchronization. "Modern LLM pre-training relies on the tightly coupled single program, multiple data (SPMD) paradigm (e.g., data, tensor, and sequence parallelism)"
- Slice (TPU slice): A partition of TPU resources; failures can remove slices, reducing effective batch size. "slices of TPU chips"
- Straggler: A slow worker that delays synchronous training progress. "a single hardware failure or straggler can stall the entire system."
- Streaming DiLoCo: A DiLoCo variant that synchronizes parameter fragments in a staggered, overlapped fashion to reduce peak bandwidth. "Streaming DiLoCo offers a number of benefits, including significant reductions in bandwidth usage (total and peak) and the ability to make communication across steps asynchronous."
- Synchronization barrier: A point where all workers must reach before proceeding, causing stalls on failures/slowdowns. "they are bound by strict synchronization barriers: a failure or slowdown in any single device stalls the entire cluster."
- Syncer: The central service that aggregates learner updates and performs outer optimization asynchronously. "a central synchronizer (the syncer), which asynchronously receives and sends updates to learners."
- Tensor parallelism: A model parallelism strategy splitting tensors across devices for concurrent computation. "Modern LLM pre-training relies on the tightly coupled single program, multiple data (SPMD) paradigm (e.g., data, tensor, and sequence parallelism)"
- Token-weighted merging: Weighting learner contributions by token counts (and step efficiency) when aggregating updates. "by aggregating updates using a minimum quorum, an adaptive grace window, and dynamic token-weighted merging."
- TPU: Tensor Processing Unit, Google’s ML accelerator used here in large training clusters. "slices of TPU chips"
- Vector clock: A per-worker logical timestamp vector used to track causality and coordinate state across distributed components. "Each worker locally maintains a vector clock \citep{mattern1989virtual} keeping track of its own step as well as its latest knowledge of the step for each of the other workers in the system."
- Watermarking: Marking channels with progress to enable garbage collection of obsolete state in distributed messaging. "watermarking of channels to garbage-collect old state"
- XLA: Accelerated Linear Algebra compiler/runtime used to execute operations on accelerators; here, profiled to analyze heterogeneity. "XLA operations when learners have varying step times for quorum sizes of , , and with an adaptive grace window."
Collections
Sign up for free to add this paper to one or more collections.