- The paper establishes that LLM-enhanced recommenders suffer from severe optimization barriers due to norm disparities and misaligned semantic clustering.
- It proposes TF-LLMER, which normalizes embeddings and uses Rec-PCA to reduce angular clustering, thereby achieving smoother training loss trajectories.
- Empirical results across multiple datasets and backbones demonstrate that the framework consistently improves standard recommendation metrics.
Breaking the Optimization Barrier in LLM-Enhanced Recommender Systems: Representation-Level Analysis and Practical Solutions
Motivation and Problem Identification
LLM-enhanced recommender models exploit LLM-derived semantic representations to initialize item embeddings in conventional recommendation backbones, allowing richer item textual encoding and obviating inference-time LLM cost. Despite architectural advances–notably methods like LLMInit, LLM-ESR, LLMEmb, and LLM2Rec–these models systematically exhibit intractable optimization behaviors: after LLM embedding injection, the retraining loss plateaus at substantially higher levels than standard randomly initialized recommenders (see baseline loss curves).
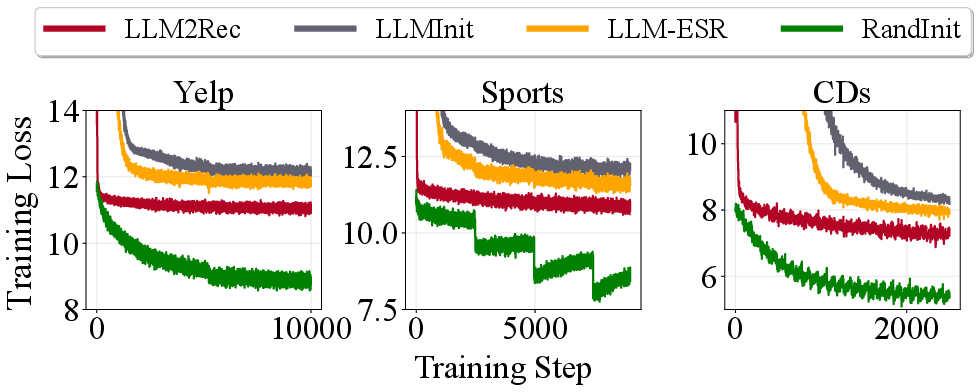
Figure 1: Training loss comparison between randomly initialized GRU4Rec and various LLM-enhanced methods highlights severe optimization barriers post-embedding injection.
This phenomenon signals an unexplored optimization barrier, with prior research narrowly focusing on downstream adaptation or semantic extraction, ignoring the induced geometric conditioning of backbone training.
Theoretical Framework: Conditioning and Optimization Curvature
The authors formalize training difficulty via the Hessian condition number of the recommendation loss with respect to sequence representations. Two critical representation-level issues emerge:
- Norm disparity: LLM-derived item embeddings exhibit large variations in magnitude, destabilizing curvature and inducing ill-conditioned optimization.
- Semantic–collaboration misalignment: Angular clustering among effective items is driven by semantic proximity (from LLMs), but not collaborative relevance, increasing embedding similarity among training-critical items and further worsening Hessian conditioning.
Empirical evidence supports these findings: item embedding norms from LLM2Rec (the strongest baseline) display dramatic long-tail disparities across datasets.
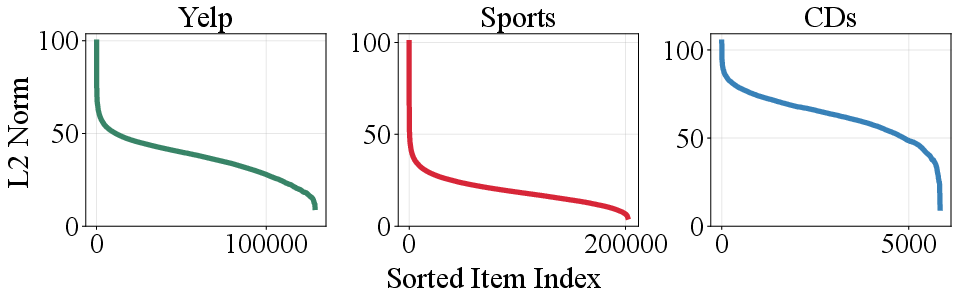
Figure 2: Magnitude distribution of item embeddings from LLM2Rec exhibits extreme norm disparity, which strongly drives training instability.
Additionally, the maximum effective cosine similarity between critical items increases sharply post LLM injection compared to random initialization.
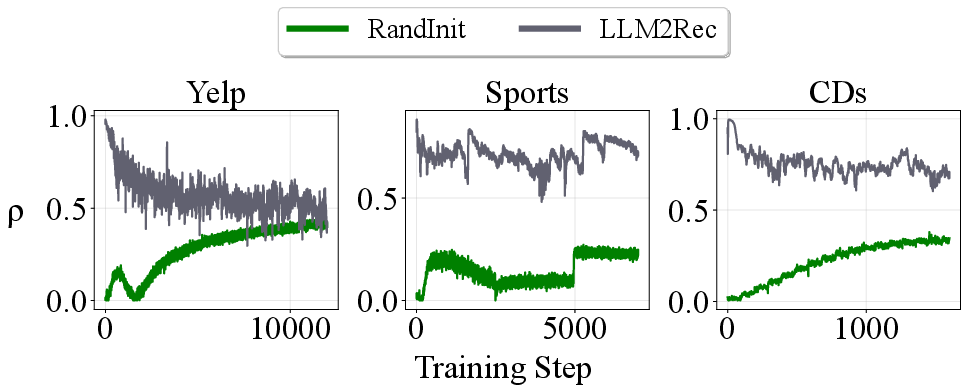
Figure 3: Training curves for maximum effective item similarity (ρ) indicate that LLM2Rec increases angular clustering among recommendation-critical items, undermining optimization.
The theoretical upper bound of the Hessian condition number is jointly determined by the squared ratio of max/min item embedding norm (norm disparity) and the condition number of the effective cosine similarity matrix (misaligned angular clustering), making precise the two optimization barriers.
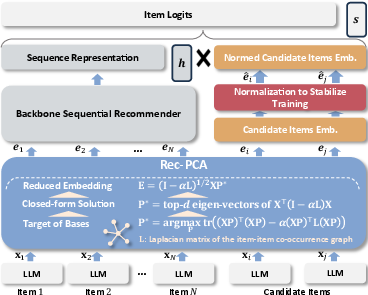
Methodology: Training-Friendly LLM-Enhanced Recommender (TF-LLMER)
The proposed TF-LLMER framework directly targets the identified obstacles with two lightweight, backbone-agnostic modules:
Empirical validation shows that normalization drastically reduces loss and improves training smoothness.
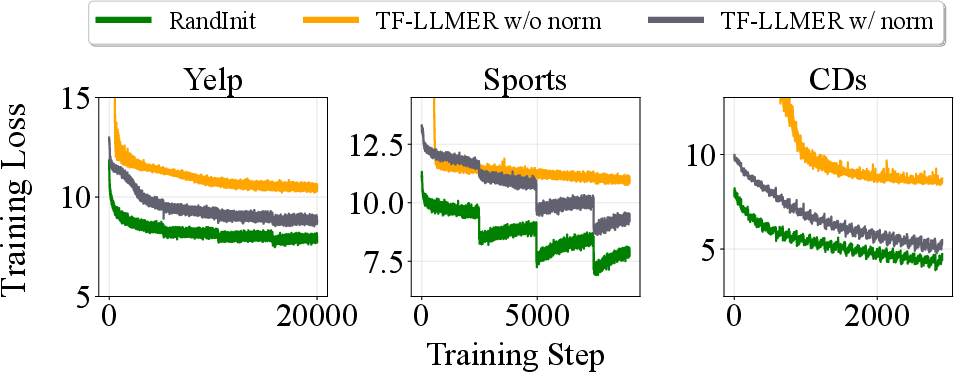
Figure 5: Training loss comparison with/without normalization (SASRec backbone) reveals normalization’s decisive impact on optimization tractability.
- Rec-PCA: A novel recommendation-aware dimensionality reduction module, Rec-PCA leverages graph signal processing by penalizing total variation on an item–item co-occurrence graph built from interaction history. This process explicitly injects collaborative structure during representation transformation, balancing semantic information retention (PCA-style variance maximization) with collaborative alignment via a tunable tradeoff hyperparameter α. Closed-form eigenvector solutions ensure efficiency.
Rec-PCA is shown to consistently reduce maximum effective similarity among items, substantiating its role in mitigating angular clustering and further lowering the Hessian condition number.
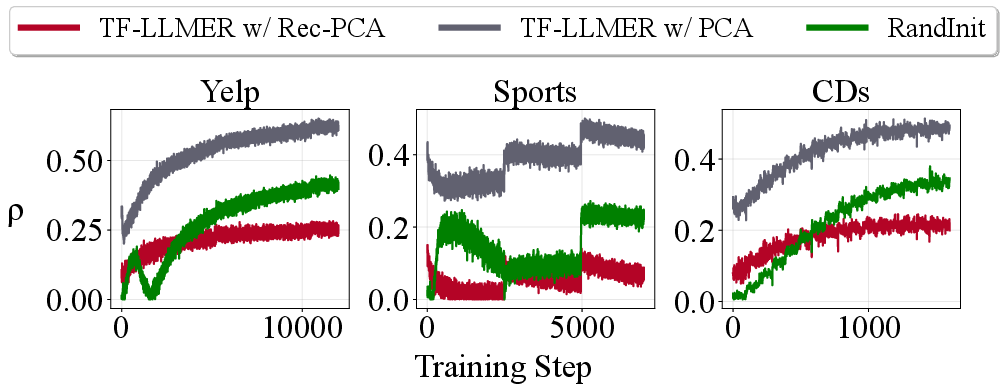
Figure 6: Training curves for ρ (effective coherence) demonstrate Rec-PCA’s ability to reduce angular clustering compared to vanilla PCA and random initialization.
Consequently, Rec-PCA delivers superior loss trajectories throughout retraining, substantially facilitating backbone optimization.
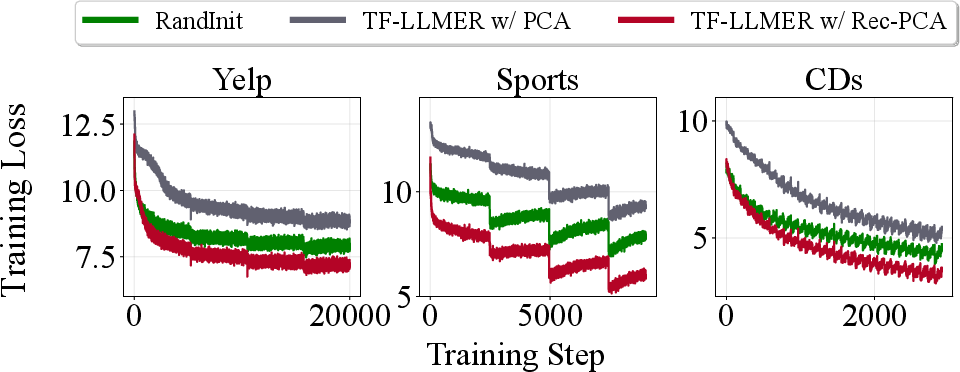
Figure 7: Training loss trajectories for Rec-PCA, vanilla PCA, and random initialization showcase Rec-PCA’s superior optimization properties.
Empirical Evaluation
Experiments spanning three public datasets (Yelp, Amazon Sports, Amazon CDs) and three recommendation backbones (GRU4Rec, SASRec, Bert4Rec) validate TF-LLMER’s effectiveness. On all metrics (Hit Rate, NDCG at N∈{5,10}), TF-LLMER yields significant, consistent improvements over state-of-the-art baselines.
The analysis further demonstrates that TF-LLMER is compatible with existing methods and can be integrated as a plug-in module, consistently enhancing their performance across backbones and dataset domains. Ablation studies isolate the contributions of normalization and Rec-PCA, confirming both as essential for optimal training.
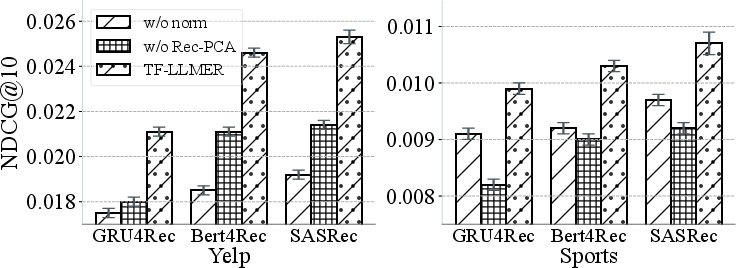
Figure 8: Ablation study quantifies the individual effects of normalization and Rec-PCA, demonstrating each module’s necessity for effective training.
Practical and Theoretical Implications
This work exposes fundamental optimization barriers in LLM-enhanced recommendation architectures at the representation level, challenging prevalent paradigms focused on semantic adaptation alone. The modular solution—embedding normalization and collaborative graph-aware dimensionality reduction—provides a blueprint for controllably integrating LLM representations while preserving collaborative filtering efficacy.
Theoretically, this approach connects signal conditioning in deep learning optimization to spectral/graph signal processing, with potential relevance for broader applications involving pre-trained embeddings in downstream tasks. Practically, it delivers substantial empirical gains without additional LLM fine-tuning or inference cost, making the framework robust and deployable.
Future Directions
Open problems include further characterization of collaborative–semantic tradeoffs, extension to heterogeneous item graphs, and adaptation to multi-modal item representations. As LLMs become increasingly central in recommender pipelines, ensuring training tractability via principled signal processing and normalization will be critical. Rec-PCA and embedding normalization could also inform representation alignment techniques in other contexts, such as knowledge distillation and fine-tuning for user modeling.
Conclusion
TF-LLMER systematically addresses the optimization barriers inherent in LLM-enhanced recommenders by combining provable normalizing strategies and graph-aware representation transformation. The result is a robust, lightweight framework that outperforms existing models, opening new prospects for representation-level conditioning analysis and graph-informed adaptation in recommender systems (2604.20490).