Selective LLM-Guided Regularization for Enhancing Recommendation Models
Abstract: LLMs provide rich semantic priors and strong reasoning capabilities, making them promising auxiliary signals for recommendation. However, prevailing approaches either deploy LLMs as standalone recommender or apply global knowledge distillation, both of which suffer from inherent drawbacks. Standalone LLM recommender are costly, biased, and unreliable across large regions of the user item space, while global distillation forces the downstream model to imitate LLM predictions even when such guidance is inaccurate. Meanwhile, recent studies show that LLMs excel particularly in re-ranking and challenging scenarios, rather than uniformly across all contexts.We introduce Selective LLM Guided Regularization, a model-agnostic and computation efficient framework that activates LLM based pairwise ranking supervision only when a trainable gating mechanism informing by user history length, item popularity, and model uncertainty predicts the LLM to be reliable. All LLM scoring is performed offline, transferring knowledge without increasing inference cost. Experiments across multiple datasets show that this selective strategy consistently improves overall accuracy and yields substantial gains in cold start and long tail regimes, outperforming global distillation baselines.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how to make recommendation systems (like the ones that suggest videos, products, or songs) smarter by using LLMs such as ChatGPT. But instead of always trusting the LLM, the paper suggests only listening to it when it’s likely to be right. This selective approach makes recommendations more accurate, especially for new users and unpopular items.
What questions were the authors asking?
The authors wanted to figure out:
- How can we use LLMs to help recommenders without making them slow, expensive, or copy the LLM’s mistakes?
- Can we teach a recommender to learn from an LLM only in situations where the LLM is usually helpful (like when a user is new or an item is rare)?
- Will this selective strategy beat the common approach of forcing the recommender to imitate the LLM everywhere?
How did they do it? (Explained with simple ideas)
Think of a recommender system as a student learning to guess what you’ll like. An LLM is like a super-smart coach: sometimes it gives great advice, sometimes it doesn’t. The key idea is to build a “smart ear” that chooses when the student should listen to the coach.
Here’s the approach, step by step:
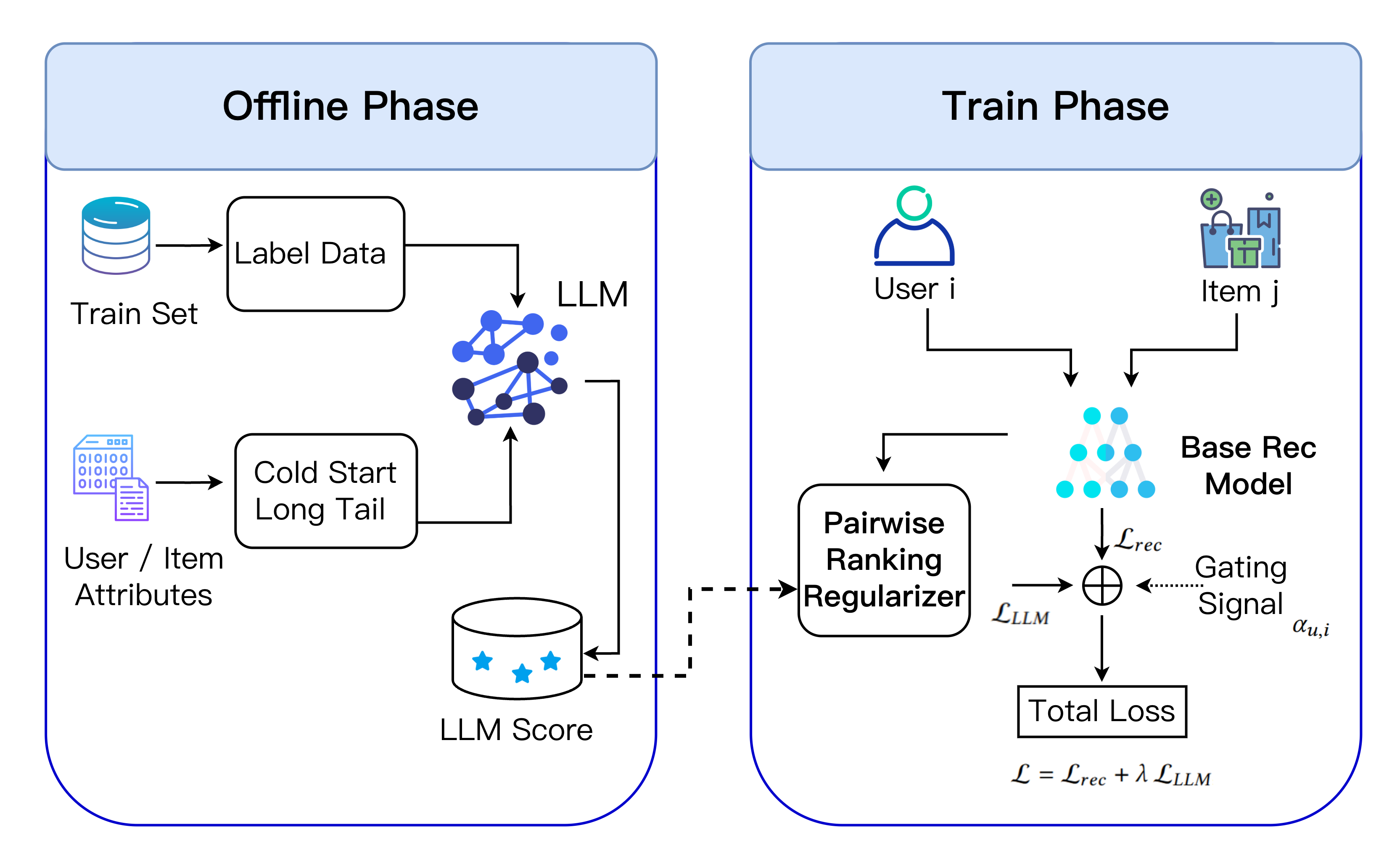
- LLM scores done offline: Before training, the LLM is asked to look at short summaries of each user’s recent activity and to rate how suitable some candidate items are. This is like asking the coach to grade practice problems at home. Because all of this happens offline (before the real system runs), it doesn’t slow down the actual recommendation process users see.
- Selective gate (a “when-to-listen” switch): During training, a small learnable “gate” decides if the LLM’s advice should be used for a specific user–item situation. The gate looks at three simple signals:
- How new is the user? (short history means “cold-start”)
- How unpopular is the item? (rare or “long-tail”)
- How unsure is the base model right now? (its “uncertainty”)
- The gate outputs a number between 0 and 1: closer to 1 means “trust the LLM more here.”
- Pairwise ranking, not point-by-point copying: Instead of copying the LLM’s exact scores, the recommender learns from the LLM’s orderings—who should rank higher between two items. This is like learning which of two suggestions is better, which is easier and less risky than copying exact scores. It also matches how recommenders work in practice: they rank items.
- Regularization, not replacement: The LLM’s advice acts like a gentle nudge (a regularizer) during training, only when the gate says it’s likely useful. The recommender still learns mainly from real user data; the LLM just helps in tricky spots.
- No extra cost at runtime: Because all LLM judging happens before training, the final system doesn’t call the LLM when making live recommendations. That keeps it fast and cheap.
What did they find, and why does it matter?
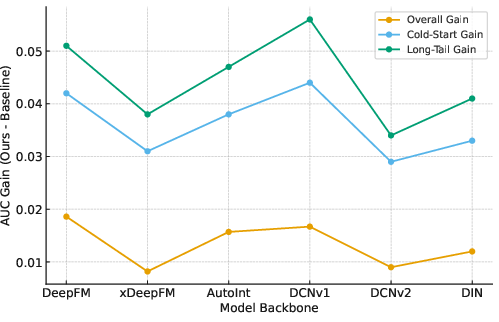
Across several real-world Amazon product datasets (Sports, Beauty, and Toys) and six different recommendation models, the selective method:
- Improved overall accuracy (measured by AUC) compared to both:
- No LLM help, and
- Global “copy the LLM everywhere” methods.
- Helped the most where recommenders usually struggle:
- Cold-start users (people with very short histories)
- Long-tail items (less popular, niche products)
The authors also ran “ablation” tests (turning parts on and off) and showed:
- Selective gating beats using LLM guidance everywhere.
- Learning from the LLM’s rankings (pairwise) beats trying to match its scores directly (pointwise).
- The method works across many different recommender architectures, so it’s flexible and broadly useful.
This matters because it shows you can get the benefits of LLMs—like understanding text and reasoning—without paying the high cost of running them live or copying their mistakes.
What’s the bigger impact?
- Smarter, fairer help where it’s needed most: New users and niche items get better recommendations, which improves user experience and helps smaller creators or products get noticed.
- Practical for industry: Since the LLM work is done offline, the final system stays fast and affordable.
- Safer use of LLMs: By listening selectively, the system avoids known LLM issues like bias or “hallucinations” (confident but wrong answers).
- Easy to plug in: The framework is model-agnostic, so it can be added to many existing recommenders.
In short, the paper shows a simple but powerful idea: don’t blindly copy an LLM—learn when to trust it. This makes recommendations more accurate, more robust in hard cases, and still efficient to run.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. Each point is phrased to be actionable for future research.
- Theoretical underpinnings: No analysis or guarantees on when selective LLM regularization improves generalization; formalize conditions under which the gate should activate and quantify expected risk reduction vs. base training.
- Gate identifiability and supervision: The gate is trained only via the LLM hinge loss without ground-truth labels of “LLM correctness”; evaluate collapse modes, calibrate with explicit labels of teacher superiority (e.g., when LLM ranking agrees with held-out user feedback more than the base model), or add auxiliary supervision.
- Limited gating signals: Gate uses only cold-start indicator, item popularity, and base-model uncertainty; test richer and more direct reliability proxies (LLM self-consistency, multi-LLM consensus/disagreement, LLM confidence/variance, prompt features, item/user text signals, cross-model disagreement).
- Teacher uncertainty unused: Incorporate explicit teacher-side uncertainty (e.g., stochastic decoding variance, temperature sweeps, self-consistency voting) to down-weight unreliable LLM signals; benchmark against current gate-only approach.
- Hyperparameter sensitivity: No sensitivity analyses for margin m, regularization weight λ, history length L, candidate count M, or top-K popularity pool; perform grid/sobol sweeps and develop adaptive schedules or curriculum strategies for λ and m.
- Coverage and candidate sampling bias: Offline LLM scoring draws candidates from a top-K popularity pool; measure how this biases supervision (especially against long-tail) and evaluate stratified/long-tail-focused or user-personalized sampling policies.
- Handling missing LLM scores: Defaulting unscored pairs to 0.5 is arbitrary; quantify its impact and compare alternatives (masking, confidence-aware imputation, content-based prediction of missing scores).
- Prompt design under-specified: The paper does not detail what item/user textual attributes were included; run prompt ablations (titles vs. descriptions vs. reviews, chain-of-thought vs. short rationales, order/randomization) and report their effect on reliability.
- Teacher choice and cost-performance: Only GPT-4o-mini is used; compare multiple LLM families/sizes (open/proprietary, domain-tuned), quantify token/query costs, and establish performance–budget trade-off curves.
- Scalability and storage: Quantify storage footprint for the (u,i)→score table, training-time overhead from pairwise regularization, and scaling behavior to larger catalogs; study compression, caching, or on-the-fly scoring under budget constraints.
- Temporal staleness and drift: Offline scores can become outdated; evaluate refresh cadences, incremental updates, or drift-detection strategies and measure temporal robustness with time-split experiments.
- Extreme cold-start: Zero-history users and truly new items are not evaluated; incorporate side-information (text, images) into prompts/backbones, and devise protocols to handle completely unseen entities.
- Metric breadth: Only AUC is reported; add ranking metrics (NDCG@K, Recall/Hit@K, MAP), calibration metrics (ECE, Brier), and practical KPIs (coverage, diversity, novelty, tail exposure) to validate claimed benefits.
- Statistical rigor: No confidence intervals, significance tests, or multi-seed variance are provided; add rigorous statistical testing and report variability to substantiate small AUC gains.
- Baseline completeness: Compare against strong self-supervised/graph CF baselines (e.g., SGL/SimGCL), and against selective/uncertainty-weighted KD methods (conformal prediction, teacher temperature calibration, ensemble disagreement).
- Re-ranking evaluation gap: Although motivated by LLM strength in re-ranking, experiments use full-catalog ranking; add candidate re-ranking benchmarks and pipelines to test this motivation directly.
- Robustness to noisy teachers: Stress-test with systematically perturbed or biased LLM scores to quantify the gate’s ability to suppress harmful supervision and measure failure modes.
- Gate behavior transparency: Report learned gate coefficients, activation rates by segment (history length, popularity, uncertainty), and per-signal ablations to explain when/why the gate activates.
- Confirmation-bias risk: The gate may activate on pairs already easy for the base model; design counterfactual checks or curricula ensuring activation tracks true teacher advantage, not base-model ease.
- Fairness and popularity bias: Using item popularity as a gating signal may reinforce head-item exposure; measure fairness/diversity impacts and test debiasing strategies (re-weighting, exposure constraints).
- LLM position bias mitigation: The prompt may still induce position/order bias; experimentally randomize candidate order, apply debiasing schemes, and quantify residual bias in teacher outputs.
- Data leakage and contamination: Clarify temporal splits for prompts, ensure the teacher does not see test-era information, and assess LLM pretraining contamination on Amazon items/popularity.
- Privacy and compliance: Offline prompts include user histories and the (u,i) score table persists; analyze privacy risk, propose anonymization/aggregation, on-device inference, or differential privacy.
- Reproducibility: Release code, prompts, and hyperparameters (m, λ, L, M, top-K, pair budget K̃); document item/user text processing to enable faithful replication.
- Domain and language generalization: Validate on non-Amazon domains (news, music, ads), session-based and multilingual settings; test robustness with non-English item/user text.
- Online effectiveness: Validate with online metrics or A/B tests, including latency and user impact; study how often gates would trigger in production and corresponding system load.
- Pair sampling policy: The pair budget K̃ and selection by LLM score differences are under-specified; analyze how pair count/quality and hard-negative mining affect outcomes.
- Probability calibration impact: Pairwise supervision may distort the base model’s probabilistic calibration; measure calibration and test post-hoc fixes (temperature scaling, isotonic regression).
- Environmental footprint: Quantify energy/carbon costs of offline LLM queries and training; investigate greener configurations (smaller teachers, distilled teachers, selective scoring).
- Security and adversarial robustness: Evaluate susceptibility to adversarial item texts/prompts and propose defenses (input sanitization, adversarial training).
- Multi-modal and explainability extensions: Explore adding images/audio and leveraging LLM rationales for explanations; quantify trade-offs between explainability and accuracy.
- Distribution shift at inference: Since the LLM is not used online, test robustness when production distribution diverges from training-time gate activation regions; consider lightweight online reliability proxies.
Practical Applications
Below are practical applications derived from the paper’s findings and innovations, organized by deployment horizon and linked to relevant sectors. Each item includes actionable steps, potential tools/workflows, and assumptions or dependencies that affect feasibility.
Immediate Applications
These can be deployed with current tooling by integrating the paper’s S-LLMR training framework into existing recommendation pipelines.
- Cold-start personalization for new users (e-commerce, media/streaming, news)
- Use case: Improve recommendations for users with ≤3 interactions by activating the S-LLMR gate on short histories and high model uncertainty.
- Tools/workflows: Offline LLM scoring service for sparse users; gating module leveraging Cold(u), Tail(i), and uncertainty; pairwise ranking regularizer added to training. A/B test against global distillation.
- Assumptions/dependencies: Access to an LLM (e.g., GPT-4o-mini or LLaMA2-7B); concise, privacy-compliant user history summaries; reliable uncertainty estimation (entropy, dropout, or ensemble variance).
- Long-tail item uplift and catalog diversity (marketplaces, app stores, music/video platforms)
- Use case: Increase exposure and accurate ranking of niche items (bottom 10–20% popularity) without serving-time cost.
- Tools/workflows: Synthetic candidate generation for long-tail items; offline LLM scoring table for underrepresented items; selective gating with Tail(i) to weight pairwise loss.
- Assumptions/dependencies: Item metadata quality for prompting; business alignment on diversity/novelty vs. CTR trade-offs; periodic refresh of long-tail scoring as catalogs evolve.
- Cost-efficient LLM-assisted training with zero inference overhead (ads CTR, feed ranking, retail search)
- Use case: Benefit from LLM semantic priors at training time only; avoid LLM calls during serving.
- Tools/workflows: Batch offline prompts over top-K candidate pools; normalized LLM score table lookup; gate-controlled pairwise margin loss integrated with existing CTR/BPR/InfoNCE training loops.
- Assumptions/dependencies: Stable training/serving feature parity; LLM query budgeting and caching; monitoring for over-regularization via α gating.
- Reliability-aware reranking supervision for “hard” segments (advertising, social media feeds)
- Use case: Focus supervision on high-uncertainty instances where base models struggle; mitigate position bias and noisy LLM outputs via gating and pairwise constraints.
- Tools/workflows: Uncertainty estimation pipeline (confidence/entropy/variance); gating network (one-layer sigmoid) trained jointly; pair construction within-user batches based on LLM score differences.
- Assumptions/dependencies: Calibrated uncertainty signals; tuned margin m and λ; validation-driven choice of uncertainty instantiation.
- Better onboarding flows and discovery experiences (product teams; daily life impact)
- Use case: For new users, present more relevant initial recommendations; surface niche content aligned with short histories; reduce popularity bias in “first impression” lists.
- Tools/workflows: Lightweight textual history summaries for prompts; “new user” mode activating S-LLMR; diversity/satisfaction dashboards tracking cold-start AUC and discovery metrics.
- Assumptions/dependencies: Consent/notice for data use in prompts; prompt templates robust to sparse histories; KPI alignment (retention vs. short-term clicks).
- Academic benchmarking and teaching integration (academia)
- Use case: Adopt S-LLMR as a plug-in regularizer across common backbones (DeepFM, xDeepFM, AutoInt, DCN, DIN) to study selective LLM guidance under sparsity.
- Tools/workflows: Open-source gating + pairwise loss components; offline scoring scripts; curriculum demos showing global vs. selective LLM supervision outcomes.
- Assumptions/dependencies: Availability of benchmark datasets with cold-start/long-tail labels; reproducible LLM scoring seeds; ethical use of user interaction data.
- Governance and bias mitigation in recommender training (policy, platform trust & safety)
- Use case: Reduce overreliance on LLM predictions and position bias through reliability-aware gating; document long-tail uplift as a diversity metric for audits.
- Tools/workflows: Audit logs of gate activations; fairness dashboards (exposure, calibration across popularity bins); policy playbooks for privacy-preserving offline prompts.
- Assumptions/dependencies: Defined fairness/diversity objectives; privacy-by-design summaries; compliance reviews for LLM data handling.
Long-Term Applications
These require further research, scaling, domain adaptation, or productization beyond the current paper’s scope.
- Cross-domain expansion of selective LLM guidance (search ranking, question answering, personalization in productivity tools)
- Use case: Treat LLM outputs as conditional auxiliary signals in ranking/decision systems beyond recommendation.
- Tools/workflows: Domain-specific offline scoring (e.g., query–document relevance); gate signals tuned to domain uncertainty; pairwise supervision adapted to task (e.g., BM25/semantic baselines).
- Assumptions/dependencies: Robust domain prompts; evaluation suites for reliability (hallucination/position bias); hybrid training that preserves task constraints.
- Sector-specific recommender upgrades with domain LLMs (education, finance, healthcare)
- Use case: Recommend courses/resources (education), financial products (finance), or wellness content (health) under sparse histories while controlling risk.
- Tools/workflows: Domain-tuned LLMs; safety layers on prompts and outputs; compliance-aware gating emphasizing uncertainty and expert signals.
- Assumptions/dependencies: Strict regulatory compliance (FERPA, FINRA/SEC, HIPAA); expert review of supervision signals; explainability and user consent requirements.
- Online adaptive gating and partial LLM serving (real-time systems)
- Use case: Extend S-LLMR to hybrid online settings that invoke LLMs only for the hardest real-time cases (e.g., extreme cold-start or novelty bursts).
- Tools/workflows: Streaming uncertainty estimation; budget-aware LLM invocation policies; caching of recent LLM judgments; drift-aware gate retraining.
- Assumptions/dependencies: Latency budgets; cost controls for sporadic LLM calls; safeguards against feedback loops (e.g., position bias amplification).
- Multi-LLM ensembles and metadata-rich prompting (retail fashion, multimedia platforms)
- Use case: Combine general LLMs with domain LLMs; incorporate multi-modal item metadata (text/images/video) to improve long-tail and aesthetic/semantic matching.
- Tools/workflows: Prompt orchestration pipelines; score fusion strategies; multi-modal encoders; selective gate features expanded to metadata availability/quality.
- Assumptions/dependencies: High-quality item descriptions and assets; cost of multi-LLM calls; careful normalization of heterogeneous signals.
- Privacy-preserving and compliant LLM scoring (platform compliance engineering)
- Use case: Run offline scoring on-prem or with privacy-enhancing techniques; minimize personal data in prompts; adopt federated or synthetic summaries.
- Tools/workflows: On-prem LLM deployment; PII redaction; differential privacy or federated summarization; data governance review workflows.
- Assumptions/dependencies: Organizational capacity for secure model hosting; privacy budgets; legal sign-off on summary generation and storage.
- Productization as an MLOps package (software tooling for RecSys teams)
- Use case: Offer “Selective LLM Rec Trainer” as a managed service/plugin for TorchRec/TFR/LightGBM pipelines, including scoring, gating, pairwise loss, and monitoring.
- Tools/workflows: SDKs for offline scoring and gate training; connectors to common recsys backbones; metrics dashboards for cold-start/long-tail AUC; experiment orchestration.
- Assumptions/dependencies: Vendor-neutral integrations; scalability for large catalogs; support for periodic refresh cycles and prompt versioning.
- Standard-setting and certification for LLM-assisted recommenders (policy and industry consortia)
- Use case: Establish guidelines that require reliability-aware gating, audit logs, and long-tail diversity reporting when LLMs are used in training.
- Tools/workflows: Reference compliance checklists; standardized evaluation suites; third-party audits for position bias and long-tail exposure.
- Assumptions/dependencies: Multi-stakeholder buy-in; alignment on measurable fairness/diversity KPIs; transparency commitments from platforms.
In all cases, successful deployment hinges on careful prompt design, calibrated uncertainty estimation, robust privacy practices, and continuous evaluation to ensure that selective LLM guidance improves difficult regimes (cold-start, long-tail) without introducing new biases or instability.
Glossary
- Ablation study: A controlled analysis that removes or varies components of a system to assess their individual contributions. "Ablation study on DCNv2: We compare global vs.\ gated LLM regularization, and pointwise vs.\ pairwise LLM supervision."
- AUC: Area Under the ROC Curve, a metric for ranking or classification performance. "Since our goal is to assess both global predictive accuracy and robustness in sparse regions, we report AUC as the sole evaluation metric."
- AutoInt: A recommendation backbone that learns feature interactions via self-attention mechanisms. "self-attentive feature learning (AutoInt)"
- back-propagation: The gradient-based procedure used to update model parameters by propagating errors backward through the network. "learned jointly with the backbone through back-propagation from the LLM regularization loss."
- backbone: The primary model architecture into which auxiliary methods or signals are integrated. "Across all six backbone models including DeepFM, xDeepFM, AutoInt, DCNv1, DCNv2, and DIN."
- BCE: Binary Cross-Entropy, a pointwise loss commonly used for binary classification tasks. "base loss (e.g., BCE/BPR/InfoNCE)"
- BPR: Bayesian Personalized Ranking, a pairwise ranking loss used in implicit-feedback recommendation. "base loss (e.g., BCE/BPR/InfoNCE)"
- candidate position bias: A systematic tendency of models to favor items based on their position in a list rather than relevance. "strong candidate position bias"
- collaborative filtering (CF): A family of methods that predict user preferences based on patterns of user–item interactions. "Classical collaborative filtering (CF) forms the foundation of modern recommender systems."
- cold-start: The sparse-data regime where new users or items have little to no interaction history. "cold-start users, long-tail items, and scenarios where user preferences are weakly expressed."
- CTR: Click-Through Rate, a metric and task setting focusing on predicting the probability of a user clicking an item. "in CTR and implicit-feedback recommendation."
- embedding dimension: The size of the latent vector representing users or items in a model. "a batch size of 128, and an embedding dimension of 64"
- ensemble variance: A measure of model uncertainty estimated from the variability across multiple models or stochastic passes. "predictive entropy or ensemble variance"
- full-ranking evaluation: An evaluation protocol that ranks each test item against all non-interacted items. "We adopt the standard full-ranking evaluation setting,"
- gating function: A learned scalar function that modulates the influence of an auxiliary signal based on contextual features. "A gating function controls whether LLM supervision is activated for a given user–item pair."
- gating mechanism: The broader design (features and network) that determines when to trust auxiliary guidance. "a trainable gating mechanism-informed by user history length, item popularity, and model uncertainty"
- gating network: A lightweight neural module that outputs the gate value used to weight auxiliary losses. "We use a one-layer gating network"
- hallucinations: Fabricated or inaccurate outputs produced by LLMs without grounding in data. "occasional hallucinations"
- hinge loss: A margin-based loss that penalizes violations of a desired ordering between pairs. "When LLM-guided pairs reduce the hinge loss, gradients increase ;"
- implicit-feedback recommendation: Recommendation settings where user preferences are inferred from implicit signals (e.g., clicks) rather than explicit ratings. "in CTR and implicit-feedback recommendation."
- inductive biases: Architectural or algorithmic assumptions that guide what patterns a model can easily learn. "across different inductive biases."
- InfoNCE: A contrastive objective that encourages positive pairs to score higher than negatives. "base loss (e.g., BCE/BPR/InfoNCE)"
- knowledge distillation: Transferring behaviors from a teacher (e.g., an LLM) to a student model, often via soft targets. "global knowledge distillation"
- knowledge transfer: Passing useful information (e.g., rankings, semantic priors) from one model/source to another. "with an LLM-guided pairwise ranking loss for targeted knowledge transfer."
- logits: Pre-softmax scores output by a model used to derive probabilities. "the soft logits from a fine-tuned LLaMA2-7B model"
- lookup table: A precomputed mapping from keys to values used to quickly retrieve signals during training or inference. "stored as a lookup table ."
- long-tail items: Items with very low interaction/popularity that are underrepresented in the data. "Long-tail items (bottom 10\% popularity):"
- margin: A desired minimum difference between scores of a preferred item and a less preferred item in pairwise ranking. "with a margin."
- matrix factorization (MF): A method that decomposes the user–item interaction matrix into low-dimensional latent factors. "Matrix factorization (MF) models user--item affinities through latent factors"
- model-agnostic: A method that can be applied across different model architectures without modification. "a model-agnostic and computation-efficient framework"
- natural-language prompt: A textual query to an LLM describing the task and context for generating outputs. "converted into a concise natural-language prompt"
- normalized logits: Logit scores rescaled (e.g., to [0,1]) for comparability across items. "computed via normalized logits or temperature-scaled soft ranking."
- offline scoring: Precomputing scores prior to training/inference to avoid runtime overhead. "All LLM scoring is performed offline, and therefore introduces no inference-time overhead."
- open-world knowledge: External, broad-coverage information captured by LLMs beyond the training domain. "LLM-derived open-world knowledge,"
- pairwise ranking regularizer: An auxiliary loss that encourages the model to respect target orderings between item pairs. "a pairwise ranking regularizer whose contribution is controlled by a gating function."
- pairwise ranking supervision: Training guidance based on relative preferences between pairs rather than absolute labels. "activates LLM-based pairwise ranking supervision"
- position bias: A bias where the position of an item in a list influences its likelihood of being chosen. "issues such as position bias and hallucinated predictions."
- predictive entropy: An uncertainty measure based on the entropy of a model’s predictive probability distribution. "predictive entropy or ensemble variance"
- re-ranking: The process of refining the order of a candidate list, often using a stronger or specialized model. "excel particularly in re-ranking and challenging scenarios"
- representation-enrichment paradigm: An approach that augments learned embeddings with external knowledge (e.g., from LLMs). "capturing the representation-enrichment paradigm of using LLMs in recommendation."
- self-attentive feature learning: Using self-attention to automatically learn interactions among input features. "self-attentive feature learning (AutoInt)"
- temperature-scaled soft ranking: A soft ranking derived from scores adjusted by a temperature parameter to control distribution sharpness. "temperature-scaled soft ranking."
- top-K popularity pool: A candidate selection strategy that samples items from the K most popular items. "top- popularity pool."
- uncertainty score: A scalar quantifying how unsure a model is about a prediction for a user–item pair. "a continuous uncertainty score "
- user-consistent pair construction: Building training pairs only within the same user’s candidate set to maintain semantic coherence. "User-consistent pair construction."
- weighted pairwise ranking loss: A pairwise objective scaled by weights (e.g., gates) to emphasize reliable supervision. "we apply a weighted pairwise ranking loss"
Collections
Sign up for free to add this paper to one or more collections.