- The paper introduces a multi-agent debate framework that iteratively refines molecular candidates by leveraging distinct roles of Developer, Debater, Examiner, and Refiner agents.
- The approach achieves a 59.82% exact match score and superior success rates on open-domain generation, outperforming previous single-pass models.
- The framework integrates global-local structural reasoning with dynamic prompt refinement, setting a new benchmark for text-guided molecular design.
Multi-Agent Debate for Structural Reasoning in Molecular Design: An Analysis of Mol-Debate
Introduction and Motivation
Text-guided molecular design tasks—where natural language imperatives are used to generate molecular structures under hard chemical constraints—pose a considerable challenge for AI systems. The core issue is the intrinsic "text-structure gap": mapping unstructured, sequential text to highly structured, non-linear molecular graphs. For example, semantic units in text (like functional groups or ring systems) may be non-contiguously represented or overlapping in molecular encodings such as SMILES, complicating alignment between modalities. Figure 1 illustrates this mismatch by showing how simple textual descriptions can correspond to non-trivial molecular features.
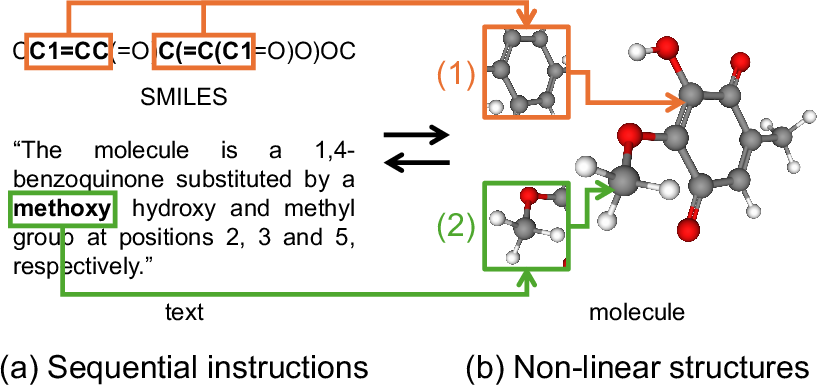
Figure 1: The mapping challenge between linear language instructions and the non-linear molecular structure domain, illustrated by ring and methoxy group representations.
Most state-of-the-art approaches—including RAG, Chain-of-Thought (CoT) prompting, fine-tuned and RL-trained large chemical LMs—operate with a single-pass or one-shot paradigm, employing ad hoc, explicitly selected reasoning perspectives. These pipelines lack the dynamic, iterative, critique-refinement cycles central to real-world medicinal chemistry workflows, where candidate designs are continuously scrutinized, debated, and iteratively refined via multidisciplinary expertise.
The Mol-Debate Paradigm
The Mol-Debate framework introduces a multi-agent, iterative generation architecture specifically tailored to bridge the text-structure gap. It orchestrates a pipeline of expert (Developer) and generalist (Debater) LLM agents, complemented by deterministic structural auditing (Examiner) and dynamic instruction refactoring (Refiner). The agents operate in a generate-debate-refine loop, integrating global and local perspectives on both semantic alignment and molecular feasibility.
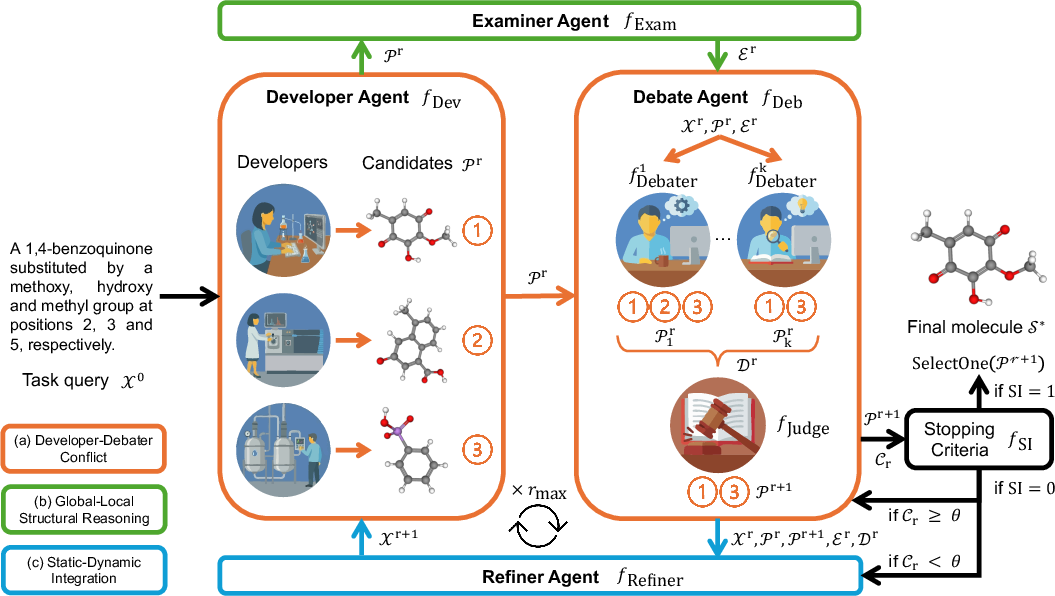
Figure 2: The Mol-Debate framework, highlighting Developer-Debater Conflict, integration of global-local structural reasoning, and static-dynamic orchestration via a closed generate-debate-refine loop.
Key Mechanistic Innovations
- Developer-Debater Conflict: Highlights and leverages the differing inductive biases between domain-specialized (developer) and generalist (debater) LLMs. Developers produce chemically valid, diverse candidates, while debaters—more attuned to raw language understanding—critique the alignment with the original intent.
- Global-Local Structural Reasoning: The Examiner Agent performs property-driven, deterministic analyses of candidates, providing ground-truth chemical descriptors that anchor downstream debate beyond surface string similarity or plausibility.
- Static-Dynamic Integration: The Refiner Agent analyzes consensus breakdowns among debaters, reformulates the prompt to resolve ambiguous or underspecified constraints, and triggers additional rounds of candidate generation—a closed feedback system enabling iterative improvement.
Experimental Evaluation
A range of benchmarks were used: ChEBI-20 for caption-to-molecule tasks (matching textual descriptions to SMILES), and S2-Bench for more open-ended text-driven molecular generation, including design, editing, and optimization queries.
Caption-to-Molecule Generation
Mol-Debate achieves an exact match (EM) score of 59.82%, outperforming all prior generalist and chemical LLMs (improving EM by over 6 points versus the next-best ChemDFM-v1.5-8B baseline), and demonstrating consistent improvements in molecular fingerprint F-scores and validity.
Open-Domain Molecule Generation
On the S2-Bench suite, Mol-Debate yields the highest success rate (SR) and weighted success rate (WSR)—0.7522 and 0.5052, respectively—indicating improved robustness in realistic, unconstrained generation scenarios across both structural and functional objectives.
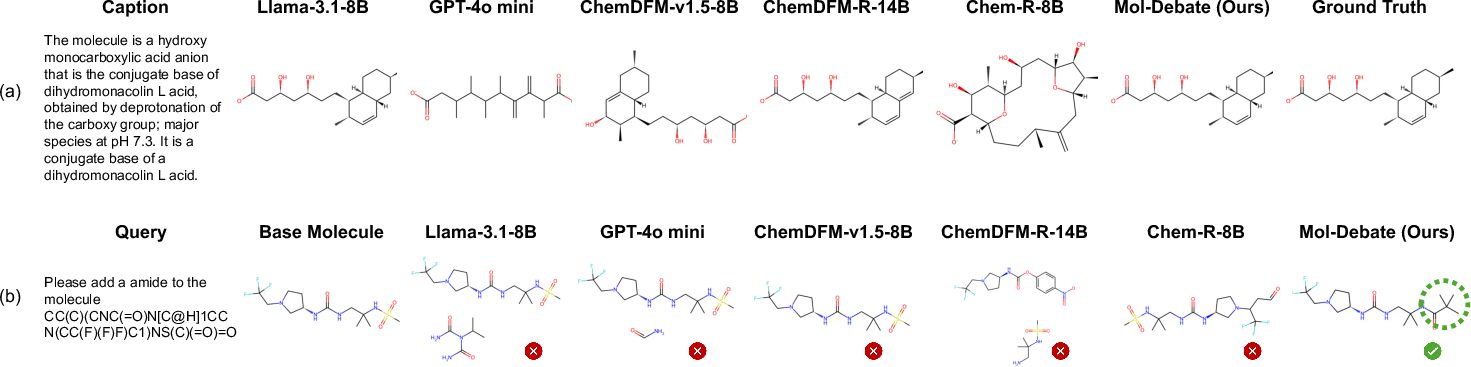
Figure 3: Representative Mol-Debate samples, demonstrating successful caption-to-molecule and open-ended text-guided molecule generation.
Multi-Perspective Ablation and Agent Synergy
Detailed ablations demonstrate that:
- Employing both developer and debater agents (heterogeneous expertise) significantly outperforms homogeneous agent pools, preventing both instruction-misaligned convergence and language-only hallucination.
- The presence of the Examiner Agent (structural evidence) raises validity and facilitates faster consensus.
- Removing dynamic refinement (Refiner Agent) reduces semantic alignment but not chemical validity, confirming that iterative constraint clarification primarily boosts task alignment rather than plausibility.
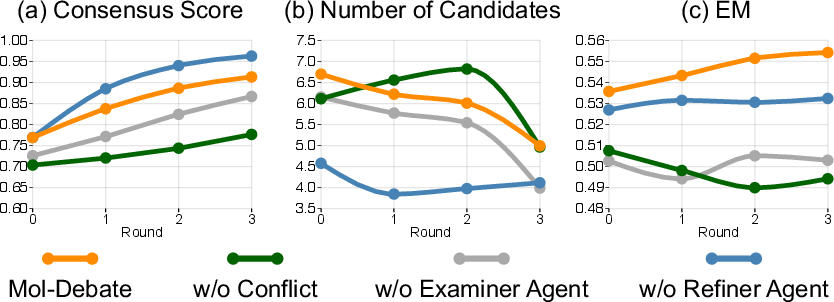
Figure 4: Round-wise analysis of consensus scores, candidate numbers, and EM, illustrating that dynamic debate/refinement accelerates convergence to correct intent-aligned solutions.
Case Studies and Mechanistic Insights
Stepwise case analyses illustrate how the system surfaces intent-structure mismatches, prunes unreliable candidates, debates over ambiguous instructions, and ultimately, by iterative prompt refinement, converges on a chemically and semantically grounded output.

Figure 5: Case study showing the interaction among Developer, Examiner, Debater, and Refiner agents over several rounds, culminating in a consensus structure.
Implications and Future Directions
Practical Implications
Mol-Debate demonstrates that multi-agent debate mechanisms materially enhance the structural reasoning capacity of LLM-based molecular design systems, especially under real-world, ambiguous, or composite-objective scenarios. By integrating deterministic chemical features with dynamic semantic critique, the system reliably balances validity, diversity, and fidelity to user intent.
Theoretical Implications
The orchestration of orthogonal agent skills—explicitly separating propositional, evaluative, and refinement roles—offers a robust blueprint for multimodal, multiperspective alignment in any domain where mapping from ambiguous language to structured outputs is required. The iterative debate-refinement loop provides a general template for correcting overfitting, premature convergence, or groupthink in multi-agent LLM systems.
Limitations and Areas for Future Work
- Computational Overhead: The multi-round, multi-agent protocol incurs substantial inference costs compared to single-pass baselines, highlighting the need for more efficient judge policies or adaptive early-stopping criteria.
- Evaluator Scope: The deterministic evidence provided by current Examiner agents can be extended with more complex, task-specific evaluators (e.g., bioactivity, synthetic feasibility).
- Ambiguity Handling: For underspecified tasks, enabling users to explicitly tune consensus or candidate diversity remains an open challenge.
Extensions Beyond Molecular Design
Mol-Debate’s core design principles are directly extensible to other multidisciplinary, highly-structured generation problems—including multimodal reasoning, scientific hypothesis generation, and even sign language translation (see Appendix for further discussions and references). The underlying architecture supports plug-and-play integration of diverse foundation models and deterministic domain tools.
Conclusion
Mol-Debate sets a new standard for text-driven molecular design via robust orchestration of diverse agent perspectives and iterative, evidence-grounded debate. Its holistic integration of semantic, structural, and refinement signals yields superior fidelity and validity compared to both general LLMs and chemistry-specialized models. The approach carries broad implications for multimodal reasoning and agent collaboration in scientific discovery and beyond.
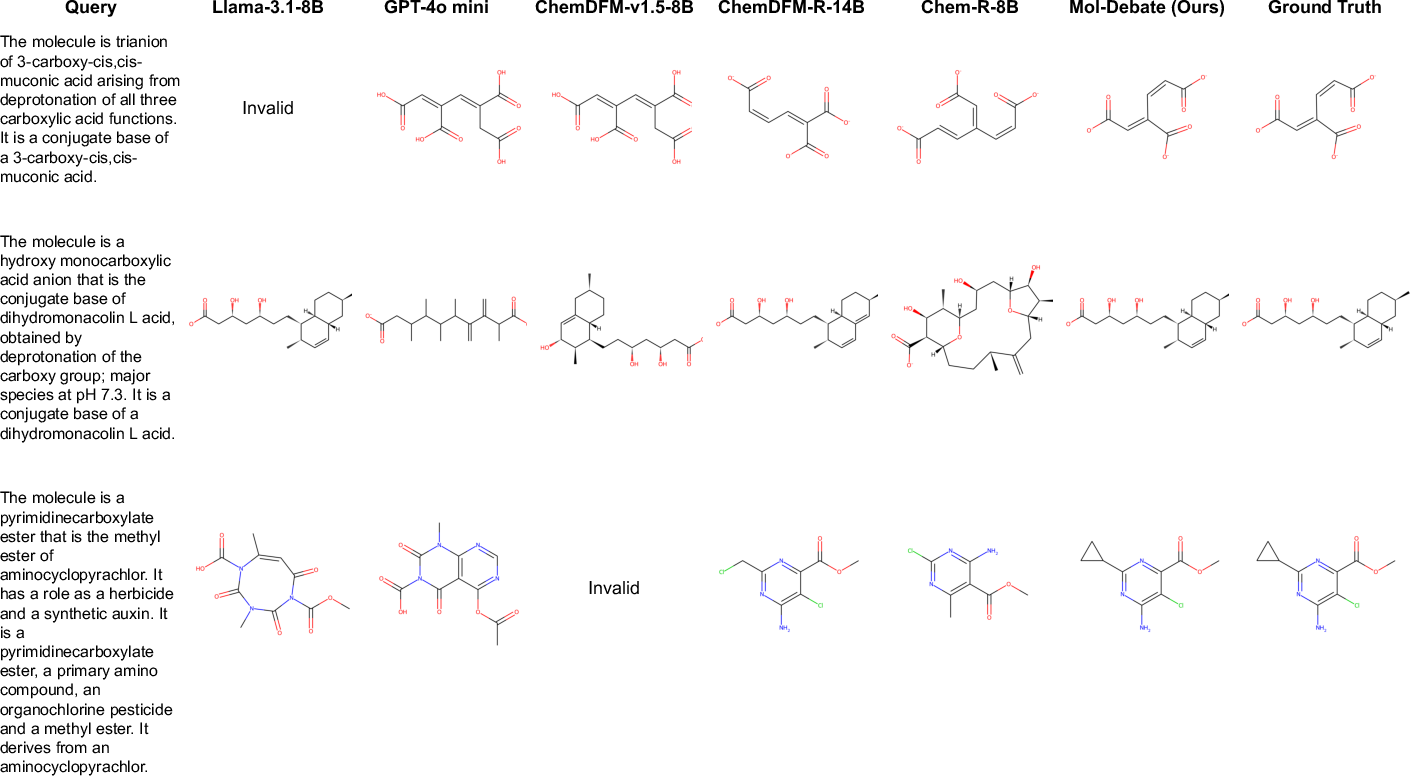
Figure 6: Mol-Debate-generated samples in caption-to-molecule generation, exemplifying high semantic and structural fidelity.