- The paper presents a two-stage pipeline that combines FastSAM’s accelerated mask generation with a multi-branch semantic labeling module.
- It achieves over 20x faster inference and competitive mIoU scores (70.33% on Cityscapes) while drastically reducing GPU memory usage.
- The design supports flexible closed-set and open-vocabulary segmentation, enabling real-time applications on resource-constrained devices.
Semantic-Fast-SAM: An Efficient Paradigm for Semantic Segmentation
Introduction
Semantic segmentation is a critical computer vision task underpinning applications in autonomous systems, robotics, and large-scale visual understanding. The emergence of foundation models, particularly the Segment Anything Model (SAM), has set a new bar for class-agnostic mask generation with broad generalization capabilities. However, SAM’s transformer-based architecture is computationally prohibitive for resource-constrained or real-time deployments, and its native outputs lack semantic category labels. Extensions such as Semantic-Segment-Anything (SSA) have enabled semantic labeling on top of SAM, but real-time practical use remains elusive due to high inference latency and memory footprint.
Semantic-Fast-SAM addresses these limitations by coupling the rapid FastSAM mask generator, which employs an efficient CNN-inspired by YOLO and YOLACT, with a multi-branch semantic labeling pipeline inspired by SSA. This composite design realizes real-time, high-throughput semantic segmentation with strong open-vocabulary capability and minimal accuracy loss compared to state-of-the-art, transformer-based solutions.
Architecture of Semantic-Fast-SAM
The Semantic-Fast-SAM (SFS) architecture is a two-stage pipeline. The first stage generates class-agnostic masks leveraging FastSAM's accelerated YOLOv8-style instance segmentation, which can deliver segmentations at up to 50× the speed of the original SAM by amortizing computation over dense image features and avoiding prompt-based iterative inference. The second stage assigns semantic labels by fusing predictions from closed-set segmentation heads and open-vocabulary sources.
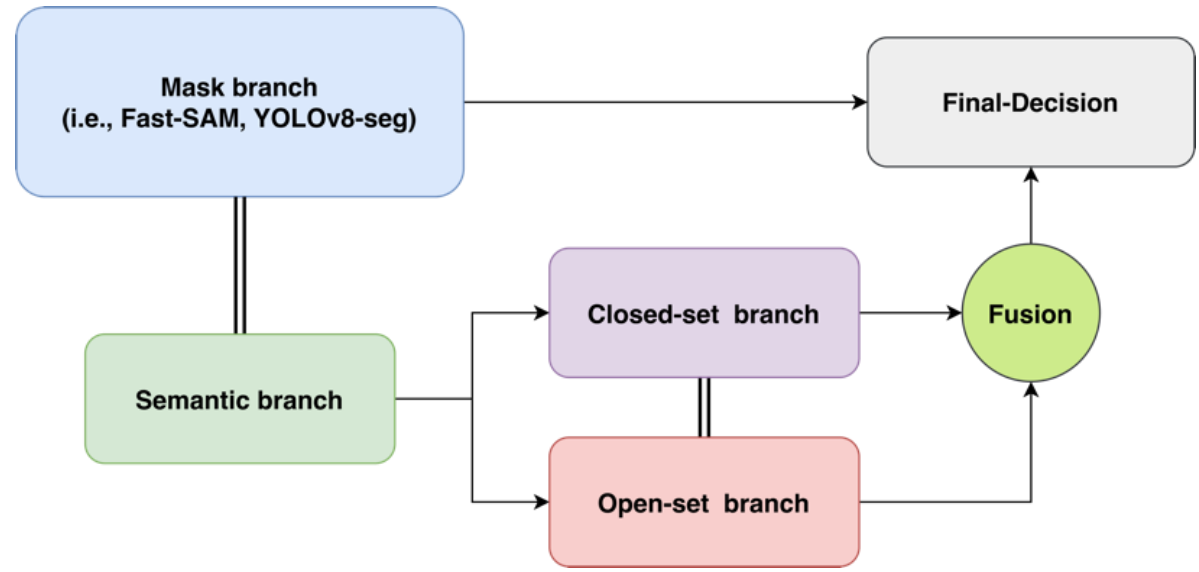
Figure 2: Overall architecture of Semantic-Fast-SAM, illustrating the integration of FastSAM for mask generation with multi-branch semantic heads for closed-set and open-vocabulary labeling.
The closed-set branch utilizes pre-trained, fully-supervised segmenters (e.g., OneFormer trained on COCO or ADE20K) to generate static semantic maps. For each mask predicted by FastSAM, the corresponding semantic class is determined by majority voting over the map region. The open-vocabulary branch uses BLIP for captioning individual mask regions, extracts candidate noun phrases, and ranks these candidates in conjunction with closed-set labels using CLIP similarity. A decision module fuses branch outputs based on confidence and contextual criteria, efficiently resolving ambiguous cases without model fine-tuning or retraining.
Experimental Results
Inference Speed and Computational Efficiency
Semantic-Fast-SAM demonstrates a dramatic reduction in inference time compared to previous SAM-based semantic segmentation systems. In closed-set mode, SFS processes high-resolution images in approximately 80~ms (>20× faster than SSA's 1.65~s), which makes it practical for real-time vision systems. In open-vocabulary mode, even with region-wise captioning and CLIP-based fusion, SFS achieves more than 3× lower latency than comparable models. These gains are attributable to the one-pass mask generation of FastSAM and the parallelizable design of the semantic labeling stage.
Memory usage is also significantly reduced; SFS’s 4.5~GB peak GPU footprint is within the range of common consumer hardware, compared with the >19~GB demand of transformer-based pipelines leveraging SAM and full SSC.
Segmentation Quality
On standard benchmarks, the model achieves mIoU scores competitive with the best zero-shot segmenters: 70.33\% on Cityscapes and 48.01\% on ADE20K, only marginally behind SAM-based SSA (71.40/48.94). This negligible accuracy drop is compensated by a substantial improvement in latency and resource efficiency. SFS also closely matches the performance of domain-finetuned, state-of-the-art supervised models (OneFormer, Mask2Former), despite not observing any target-domain images during training.
Open-Vocabulary and Semantic Breadth
The open-vocabulary branch, built from CLIP and BLIP, enables SFS to surpass prior CLIP-based segmentation models (e.g., MaskCLIP, GroupViT) in both overall mask quality and generalization to novel semantic categories. By decoupling mask generation from semantic labeling and utilizing closed-set predictions as strong priors, SFS maintains high accuracy for both common and rare object classes, facilitating robust zero-shot transfer.
Ablation Analysis
Ablation studies confirm that the open-vocabulary branch can be disabled for known environments, yielding further reductions in runtime without significant accuracy loss for closed-set tasks. Additionally, selectively controlling the mask budget during semantic labeling exposes a trade-off between inference speed and label granularity, offering versatility for deployment in computationally constrained environments.
Implications and Future Directions
The introduction of Semantic-Fast-SAM has strong implications for the democratization and deployment of semantic segmentation in real-world, latency-sensitive scenarios:
- Resource-Constrained Vision: The efficiency gains position SFS as a foundation for edge-based robotics, interactive UI, and real-time video analytics, where transformer-scale runtime is untenable.
- Flexible Open-World Recognition: By fusing closed-set and open-vocabulary cues, the architecture accommodates the dynamic and evolving set of categories encountered in open-world deployments.
- Foundation Model Distillation: The modular, inference-only design provides a blueprint for further compressing or unifying multi-modal label assignment, e.g., by distilling the CLIP ranking module into a single, lightweight semantic head.
Potential future research directions include optimizing textual captioning (substituting BLIP with efficient region encoders or CLIP-only approaches), sharing features across FastSAM and semantic heads, and unifying prompt-free open-vocabulary assignment. These developments could yield even faster pipelines, approaching the $20$ FPS real-time threshold without sacrificing coverage or accuracy.
Conclusion
Semantic-Fast-SAM constitutes a decisive advance in semantic segmentation efficiency. By combining a high-throughput CNN-based mask generator with a unified multi-branch semantic labeler, the framework delivers near-SAM accuracy at a fraction of the computational cost. Its open design, free from further training, is poised to drive the adoption of foundation segmentation models in time-constrained and resource-limited applications.

