AnyRecon: Arbitrary-View 3D Reconstruction with Video Diffusion Model
Abstract: Sparse-view 3D reconstruction is essential for modeling scenes from casual captures, but remain challenging for non-generative reconstruction. Existing diffusion-based approaches mitigates this issues by synthesizing novel views, but they often condition on only one or two capture frames, which restricts geometric consistency and limits scalability to large or diverse scenes. We propose AnyRecon, a scalable framework for reconstruction from arbitrary and unordered sparse inputs that preserves explicit geometric control while supporting flexible conditioning cardinality. To support long-range conditioning, our method constructs a persistent global scene memory via a prepended capture view cache, and removes temporal compression to maintain frame-level correspondence under large viewpoint changes. Beyond better generative model, we also find that the interplay between generation and reconstruction is crucial for large-scale 3D scenes. Thus, we introduce a geometry-aware conditioning strategy that couples generation and reconstruction through an explicit 3D geometric memory and geometry-driven capture-view retrieval. To ensure efficiency, we combine 4-step diffusion distillation with context-window sparse attention to reduce quadratic complexity. Extensive experiments demonstrate robust and scalable reconstruction across irregular inputs, large viewpoint gaps, and long trajectories.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces AnyRecon, a computer system that can build a 3D model of a place or object even when it only has a few, scattered photos or video frames to work with. Imagine trying to understand a whole room from just a handful of snapshots taken from different angles—that’s hard. AnyRecon uses a smart “video imagination” tool (a video diffusion model) plus a memory of 3D geometry to fill in the gaps in a careful, consistent way.
What questions were the researchers trying to answer?
- How can we turn a small, messy set of pictures into a clean, explorable 3D scene?
- How can we make sure the new, made-up views are consistent with the real photos and match the camera angles correctly?
- How can we handle large, complex scenes efficiently without the computer becoming too slow?
How does AnyRecon work? (Simple explanation with analogies)
Think of AnyRecon as a careful artist with two superpowers: memory and geometry.
- Building a simple 3D “skeleton” from sparse photos
- Analogy: If you’re sketching a room, you first draw a rough outline before filling in details.
- AnyRecon starts by estimating a “point cloud” (a 3D scatter of dots that marks where surfaces are). This is like a rough 3D skeleton of the scene built from the input photos.
- A “global scene memory” for flexible view use
- Analogy: The artist keeps a scrapbook of the original photos and can flip to any page at any time.
- Unlike older methods that only look at one or two photos, AnyRecon can use many photos in any order. It puts these photos into a “memory” that the model can refer to while generating new viewpoints.
- No “squishing” of time (non-compressive encoding)
- Analogy: Don’t mash several pages of your sketchbook into one page—you’ll lose details.
- Typical video tools compress frames together to save space, assuming nearby frames are similar. But when photos are far apart or out of order, this breaks. AnyRecon processes frames individually so details don’t get mixed up.
- Geometry-aware generation loop (generation + reconstruction)
- Analogy: After the artist fills in missing parts of the sketch, they update the outline so future drawing stays consistent.
- After generating new views, AnyRecon updates the 3D point cloud with what it learned, so the 3D “memory” gets better and better over time. This creates a loop: better geometry → better new views → better geometry, and so on.
- Smart photo selection (geometry-driven retrieval)
- Analogy: The artist picks the most helpful references—photos that actually show the parts of the room needed now—not just any picture that looks similar.
- Instead of picking reference photos based on simple rules (like matching colors or viewing angles), AnyRecon checks which photos truly “see” the parts needed for the current view (who can see what), and uses only those. This avoids confusion from irrelevant or occluded views.
- Efficient attention and fast generation
- Analogy: The artist focuses attention on nearby pages and the most relevant scrapbook entries to work faster.
- “Sparse attention” means the model concentrates on the most relevant frames and reference photos instead of everything at once—speeding up computation.
- “4-step diffusion distillation” is like a shortcut recipe that gets almost the same results much faster. It reduces the number of steps the model needs to generate high-quality frames.
What did they find, and why does it matter?
- Better quality with fewer inputs: AnyRecon made more accurate and consistent new views than other methods, especially when the photos were far apart or irregularly captured.
- Handles big, complex scenes: It stayed consistent over long camera paths (like walking through a large room or outdoor area) by updating and using its 3D memory.
- Faster than competitors: Thanks to sparse attention and the 4-step shortcut, it ran much faster while keeping quality high.
- More stable and reliable: Because it uses the actual 3D geometry and the right reference views, it avoids wobbly or misaligned results that some other methods produce.
In short, it’s both sharper and quicker than many existing approaches.
What’s the potential impact?
- Everyday 3D capture: People could turn casual phone videos or a few photos into explorable 3D scenes for games, VR, AR, or virtual tours—without needing a studio setup.
- Film and VFX: Creators could generate extra camera angles that match the real footage precisely.
- Architecture and robotics: More accurate 3D reconstructions from limited data could help with planning, mapping, and navigation.
- Research foundation: The idea of coupling a “global scene memory” with a “generation-reconstruction loop” can inspire future systems that are both imaginative and grounded in geometry.
Note: AnyRecon still needs a basic, reasonable starting outline of the scene. If the input photos barely overlap or the initial 3D guess is too broken, the system can struggle. But within usual conditions, it’s a strong step toward reliable 3D reconstructions from sparse, real-world captures.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions identified in the paper that future work could address:
- Quantitative scalability limits: The maximum number of conditioning views the global scene memory and non-compressive encoding can handle (in terms of VRAM, time, and quality) is not characterized; provide scaling curves vs number of reference views, sequence length, and resolution.
- Memory/computation footprint: Exact GPU memory profiles and wall-clock breakdowns (encoder/denoiser/attention/rendering) for different settings (with/without sparse attention, varying window sizes) are not reported; include resource models to guide deployment.
- Robustness to pose errors: The method assumes reasonably accurate poses but provides no systematic sensitivity analysis to pose noise, drift, or intrinsics calibration errors; quantify failure thresholds and add pose refinement or joint optimization.
- Failure modes under extreme sparsity: The limitation section mentions minimal overlap failures, but no controlled study examines how performance degrades with decreasing overlap/baseline coverage; benchmark across input cardinality and baseline distributions.
- Dynamics and non-rigid scenes: The approach assumes static scenes; applicability to dynamic objects, people, or non-rigid deformation remains unexplored; evaluate on dynamic benchmarks or propose motion-aware memory updates.
- Geometry accuracy metrics: Evaluation relies on image metrics (PSNR/SSIM/LPIPS) only; add geometric metrics (e.g., Chamfer distance, completeness, normal consistency) and camera-trajectory closure error to validate 3D accuracy.
- Output representation quality: The geometry memory is a point cloud without assessing meshability, watertightness, or suitability for downstream rendering (e.g., NeRF/3DGS fusion); compare different representations and conversion pipelines.
- Drift across chunk boundaries: The segment-by-segment generation strategy risks temporal/appearance seams at chunk boundaries; provide quantitative transition consistency metrics and blending/overlap strategies.
- Retrieval method reliability: Geometry-driven retrieval depends on per-point source attribution and visibility maps, but no ablation quantifies its benefit vs FOV/similarity baselines or its sensitivity to incorrect attributions; provide controlled experiments.
- Adaptive retrieval hyperparameters: The choice of top-k for conditioning views and the context-window size is fixed; explore adaptive policies based on uncertainty/coverage and study trade-offs.
- Occlusion handling with point clouds: Point-cloud-based visibility can be brittle in thin structures/transparency/reflections; evaluate volumetric or surface-based occlusion reasoning and quantify improvements.
- Dependence on external geometry estimators: The pipeline relies on VGGT/π3 for initialization and updates; assess robustness to their biases/failures, domain shifts, and compare with alternative feed-forward geometry methods.
- Closed-loop learning: Geometry updates are feed-forward and not trained end-to-end with the diffusion model; investigate joint training or differentiable geometry updates to reduce error accumulation.
- Distillation side effects: Four-step DMD2 distillation accelerates inference, but its impact on multi-view geometric consistency, color fidelity, and high-frequency detail is not deeply analyzed; add multi-view consistency metrics and long-range tests.
- Non-compressive encoding alternatives: While removing temporal compression helps quality, memory cost rises; explore adaptive/attention-aware compression or learned temporal decimation that preserves thin structures.
- Generalization beyond training domain: Training is on DL3DV-10K (mostly indoor); broader validation on diverse outdoor, aerial, heritage, low-light, and texture-poor scenes is limited; include cross-domain benchmarks.
- Camera-path specification and planning: The method assumes user-specified trajectories but does not address how to plan coverage-optimal paths under sparse inputs; explore active view planning integrated with geometry memory.
- Pose estimation availability: The paper uses known poses during evaluation; the end-to-end pipeline for real casual captures (pose estimation under noise/outliers) and its effect on AnyRecon are not assessed.
- Handling sensor heterogeneity: Robustness to varying intrinsics, rolling shutter, lens distortion, fisheye, and HDR/mobile sensors is not studied; add heterogeneous-sensor experiments and calibration strategies.
- Photometric/appearance consistency: Color shifts and exposure variations across captures can confuse conditioning; no photometric normalization or learned appearance harmonization is reported; analyze and mitigate.
- Large-scale scenes and loop closure: Qualitative claims suggest reduced drift, but loop-closure consistency (e.g., re-entering the same area) is not quantified; add trajectory loop tests and alignments.
- Reflective/transparent/refractive materials: Performance on challenging materials (glass, mirrors, water) is untested; include targeted benchmarks and enhanced rendering cues.
- Uncertainty estimation and confidence: The method does not estimate uncertainty in generated views or geometry; add uncertainty-aware retrieval/conditioning and confidence-weighted updates to the geometry memory.
- Downstream task integration: It is unclear how AnyRecon’s outputs perform in SLAM, AR anchoring, or robot navigation; evaluate utility in downstream tasks and latency requirements.
- Reproducibility/access: Key components (Wan2.1-I2V-14B teacher, LoRA weights, training code, datasets/splits) and licensing constraints are not fully detailed; provide open resources and recipes for replication.
- Ethical and safety considerations: The system hallucinates content beyond observations; potential misuse (e.g., misleading reconstructions) and mechanisms for provenance/attribution or uncertainty communication are not discussed.
- Ablation completeness: Several components (global scene memory, sparse attention, retrieval, masks) show qualitative benefits; include controlled quantitative ablations isolating each component across multiple datasets.
- High-resolution scaling: Experiments report 512×896; behavior at 1080p/4K (quality, memory, speed) and tiling/latent upsampling strategies are not evaluated.
- Real-time or interactive use: Inference at ~90–105 s per 40-frame sequence is far from interactive; investigate streaming generation, online updates, or partial caching for interactive exploration.
- Parameter and hyperparameter sensitivity: No sensitivity study for key hyperparameters (e.g., attention window size, noise schedule discretization, LoRA rank); provide guidance for practitioners.
- Dataset biases and coverage: DL3DV biases (layout styles, lighting, sensor types) may shape priors; characterize biases and test fairness across diverse environments.
- Failure case taxonomy: Beyond the brief limitation, no taxonomy of typical failure modes (texture repetition, motion blur, extreme parallax, heavy occlusion) is presented; document and quantify to guide future fixes.
Practical Applications
Immediate Applications
Below are deployable use cases that can directly leverage AnyRecon’s methods (arbitrary/unordered conditioning, global scene memory, non-compressive encoding, geometry-aware retrieval/memory updates, 4-step distillation, and sparse attention) with today’s hardware and ecosystems.
- Film/VFX: set reconstruction and view interpolation from limited on-set footage
- Sector: media/entertainment, software
- What: Fill coverage gaps, extend sets, and achieve view-consistent “in-between” shots from 1–4 captured views; stabilize color/geometry across long camera moves.
- Tools/products/workflows: Nuke/Houdini/Maya/Unreal plugins that ingest a capture view bank and camera path, run AnyRecon’s geometry-aware generation per segment, update a 3D point cloud memory, and export 3DGS/NeRF and dense camera tracks.
- Assumptions/dependencies: Mostly static sets; approximate camera poses; compute for 4-step inference (cloud or on-prem); QC for hallucinated regions; licensing for pretrained geometry models (e.g., VGGT/π³).
- Real estate and hospitality: fast virtual tours from casual phone captures
- Sector: real estate, tourism, software
- What: Convert sparse walkthrough photos/videos into explorable 3D scenes; interpolate viewpoints to deliver smooth tours; fill occlusions (e.g., behind furniture).
- Tools/products/workflows: Mobile capture app + cloud service; export to web viewers (glTF/three.js) or game engines; pipeline: upload → initial point map → geometry-aware selection → chunked generation → 3D memory update → tour export.
- Assumptions/dependencies: Accurate or estimated camera intrinsics/poses; static interiors; disclaimers for “hallucinated” non-load-bearing geometry; privacy and consent for captured spaces.
- AEC/FM digital twins with fewer photos
- Sector: architecture, engineering, construction (AEC), facilities management (FM)
- What: Produce room-accurate reconstructions from sparse site photos; interpolate views along inspection paths; reduce required capture density compared to traditional photogrammetry.
- Tools/products/workflows: Add AnyRecon as a front-end “densifier” to RealityCapture/Metashape/3DGS; geometry-aware retrieval prioritizes structurally informative views; export to BIM/construction viewers.
- Assumptions/dependencies: Static scenes; scale calibration (targets/laser) if metrology-grade is needed; human review for safety-critical uses; integration with pose estimation and SLAM.
- Drone mapping “gap fill” for difficult areas
- Sector: surveying, geospatial, energy/utilities
- What: Interpolate/extrapolate views along planned flight paths to cover occluded façades or inaccessible areas; reduce additional sorties.
- Tools/products/workflows: Pix4D/DroneDeploy plugin; chunked path generation with global scene memory; back-project generated frames to update point clouds before final mesh/texturing.
- Assumptions/dependencies: GPS/IMU + camera pose priors; compliance with airspace and safety rules; static or slowly changing environments; documented provenance for synthesized frames.
- Retail and warehousing: store/facility digital twins from quick walkthroughs
- Sector: retail, logistics
- What: Reconstruct store layouts and shelf areas from sparse captures; use geometry-aware retrieval to prioritize high-overlap views for planogram checks.
- Tools/products/workflows: Store ops app → upload → AnyRecon reconstruction → export floor plan overlays and 3D walkthrough; integrates with planogram or inventory systems.
- Assumptions/dependencies: In-store filming policy, customer privacy; moderate compute; static shelving during capture.
- Cultural heritage digitization from limited imagery
- Sector: culture/museums, education
- What: Build coherent 3D tours from sparse staff or tourist videos; interpolate missing views while preserving overall structure.
- Tools/products/workflows: Museum digitization pipeline with AnyRecon replacing dense photo requirements; export to WebXR/Unreal for education/VR.
- Assumptions/dependencies: Rights to imagery; static exhibits; expert oversight for historical accuracy; provenance labels for generative completion.
- Insurance and forensics: incident scene recon from sparse video (bodycam/dashcam/CCTV)
- Sector: insurance, public safety
- What: Produce coherent 3D reconstructions with view interpolation for timeline analysis; preserve captured frames while flagging generated ones.
- Tools/products/workflows: Chain-of-custody-aware pipeline; export both original and synthesized frames with visibility/attribution maps; distance-to-capture overlays to indicate confidence.
- Assumptions/dependencies: Strict provenance and non-repudiation; clear separation of observed vs generated content; static scene after incident; legal/compliance review.
- Robotics/SLAM: map densification and loop-closure assistance
- Sector: robotics, autonomous systems
- What: Use geometry-aware retrieval + global memory to synthesize views that ease loop closure, relocalization, and planning in visually sparse zones.
- Tools/products/workflows: ROS module that triggers AnyRecon when feature sparsity is detected; fuse generated frames via back-projection into the SLAM map.
- Assumptions/dependencies: Static or quasi-static scenes; careful treatment of synthesized data to avoid drift; compute budget on base station/edge.
- Accelerated NeRF/3DGS training via view densification
- Sector: graphics/engine tooling, research
- What: Generate pseudo novel views to speed/steady training of NeRF/3DGS under sparse inputs; improve coverage and reduce artifacts.
- Tools/products/workflows: Pre-pass with AnyRecon to generate 10–50% more views; train NeRF/3DGS using both captured and labeled-synthetic frames; export and evaluate.
- Assumptions/dependencies: Curate synthetic views to avoid bias; ensure camera/pose accuracy; monitoring for overfitting to hallucinated details.
- Academic data augmentation and benchmark creation
- Sector: academia
- What: Augment sparse-view datasets with geometry-consistent novel views; stress-test multi-view consistency under wide baselines and occlusions.
- Tools/products/workflows: Scripts for segment-wise generation, visibility-index attribution, and metadata packaging; release alongside capture sets.
- Assumptions/dependencies: Clear labeling of synthetic frames; licensing for redistribution of pretrained components.
Long-Term Applications
These ideas require further research, scaling, domain adaptation, or policy/governance to become robust and widely deployable.
- Live, on-device AR reconstruction from casual capture
- Sector: AR/VR, consumer devices
- What: Real-time or near-real-time 3D scene completion with arbitrary camera motion; occlusion-aware AR rendering with geometry memory.
- Dependencies: Significant model compression, efficient VAEs without temporal compression, on-device accelerators; robust pose from ARKit/ARCore; streaming memory management.
- City-scale reconstruction from crowdsourced videos
- Sector: geospatial, smart cities
- What: Aggregate massive capture view banks; geometry-driven retrieval at urban scale; segment-by-segment reconstruction with persistent global memory.
- Dependencies: Scalable retrieval across millions of views; deduplication and privacy controls; distributed training/inference; handling dynamic objects/weather/time-of-day.
- Autonomous driving: world-model completion and occlusion forecasting
- Sector: automotive
- What: Fill occluded regions from multi-camera sparse views; consistent novel views for prediction/planning.
- Dependencies: Safety-certified handling of hallucinations; domain-specific training (night, weather); strong temporal consistency and uncertainty quantification; fusion with LiDAR/Radar.
- Free-viewpoint telepresence from a few webcams or smartphones
- Sector: communications, enterprise
- What: Synthesize continuous camera paths for remote participants; maintain consistent geometry across rooms over long sessions.
- Dependencies: Online pose/latency management; incremental memory updates; identity/scene consistency; compression and streaming of 3D memory.
- Construction progress monitoring and as-built verification at scale
- Sector: AEC
- What: Compare as-designed vs as-built models with dense 3D from sparse walks; automated change detection aided by geometry-aware retrieval.
- Dependencies: Scale-accurate reconstruction; uncertainty-aware differencing that discounts hallucinated regions; integration with BIM and safety workflows.
- Disaster response: rapid 3D situational awareness from minimal flights
- Sector: public safety, humanitarian
- What: Use sparse drone passes to reconstruct key corridors and occluded interiors/exteriors; plan routes and resource placement.
- Dependencies: Robustness under debris/dynamics; strict provenance and uncertainty overlays; field-ready compute or reliable uplink; domain-tuned priors.
- Standardized provenance and watermarking for generative 3D recon
- Sector: policy, governance, platforms
- What: C2PA-style signatures on synthesized frames and mesh segments; visibility-index maps attached as metadata to trace source contributions.
- Dependencies: Cross-vendor standards; legal frameworks for disclosure of generative content; UI/UX for end-user interpretability.
- Healthcare endoscopy/robotic surgery scene completion (research)
- Sector: healthcare
- What: Geometry-aware interpolation/extrapolation along endoscope paths to recover 3D anatomy with sparse frames.
- Dependencies: Extensive domain retraining, depth priors for tissue; strict validation; regulatory approval; handling non-rigid motion and specularities.
- Edge inference for drones/robots/phones with sparse attention
- Sector: edge AI hardware/software
- What: Deploy distilled 4-step models with windowed sparse attention and dynamic retrieval on NPUs; on-demand reconstruction in the field.
- Dependencies: Memory-efficient global scene cache; mixed-precision kernels; robust fallback when geometry memory is poor.
- Synthetic data engines for robotics and vision at scale
- Sector: academia, autonomous systems
- What: Generate multi-view sequences with controllable baselines and occlusions to train/test perception stacks.
- Dependencies: Strong domain gap mitigation; automatic labeling pipelines; configurable uncertainty tagging.
Cross-cutting assumptions and risks (affecting many applications)
- Requires approximate camera poses and an initial point/geometry prior (e.g., VGGT/π³); performance degrades with minimal overlap or severe pose error.
- Best on mostly static scenes; dynamic objects and lighting changes need further handling or domain-specific training.
- Hallucination risk: generated regions should be flagged and uncertainty-quantified in safety- or compliance-critical contexts.
- Compute: although 4-step distillation and sparse attention reduce cost (e.g., ~90–105 s per 40-frame sequence at 512×896), real-time or very large-scale workloads need more optimization and hardware.
- Licensing and IP for pretrained components and datasets; privacy for captured content and shared view banks.
Glossary
- 3D Gaussian Splatting: An explicit point-based rendering technique that represents scenes with anisotropic Gaussians for real-time radiance field rendering. "explicit point-based approaches like 3D Gaussian Splatting~\cite{kerbl20233d}"
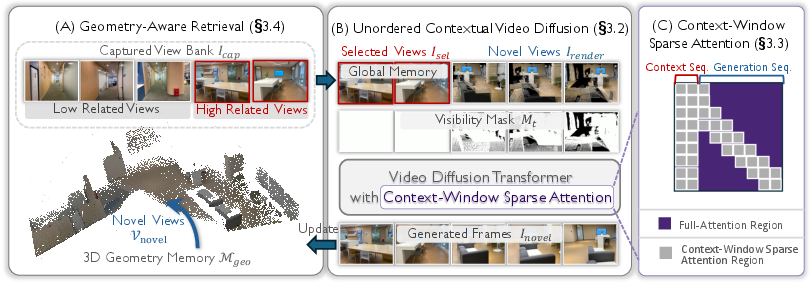
- 3D Geometry Memory: An explicit, incrementally updated point-cloud representation that stores the evolving scene geometry to guide subsequent generation and reconstruction. "we build an explicit 3D Geometry Memory by back-projecting newly generated images into the initial point cloud"
- 3D-VAEs: Video autoencoders that compress spatiotemporal data across time and space, commonly used in video diffusion but prone to losing frame-level correspondences in wide-baseline settings. "Traditional video diffusion models~\cite{wan2025} often use temporal compression (e.g., 3D-VAEs) to reduce dimensionality"
- back-projection: The process of projecting image pixels back into 3D space (using known camera geometry) to update or construct a point cloud. "via a 3D Geometry Memory with back-projection and geometry-driven capture-view retrieval"
- block sparse attention: An attention pattern that restricts attention to fixed-size blocks to reduce quadratic cost while preserving relevant context. "By removing temporal compression and adopting diffusion distillation with block sparse attention, our method generalizes across varying numbers of input views while maintaining computational efficiency."
- channel-wise concatenation: Combining multiple conditioning signals by concatenating them along the channel dimension to enforce alignment and provide explicit cues. "enforces strict spatial alignment through channel-wise concatenation of visibility masks and rendered observations "
- context-window sparse attention: An attention mechanism that limits each token’s receptive field to local temporal windows and selected reference views to achieve scalability. "we combine 4-step diffusion distillation with context-window sparse attention to reduce quadratic complexity."
- denoising score matching: A training objective that learns to predict clean data from noisy inputs by matching the data score, often used to train diffusion critics or estimators. "the critic is optimized via a standard denoising score matching objective on the student's generated samples"
- Distribution Matching Distillation: A distillation method that trains a fast student generator to match the distribution of a teacher diffusion model using score differences. "we employ Distribution Matching Distillation ~\cite{yin2024onestep,yin2024improved} to distill the pre-trained model into a student network capable of high-quality generation in just 4 steps."
- DMD2 distillation: An improved version of distribution-matching distillation tailored for higher-quality and stable few-step sampling. "Finally, we apply DMD2 distillation~\cite{yin2024improved} for an additional $30$k iterations"
- feed-forward point map estimation: A direct, non-iterative method to estimate 3D point maps from images, used to initialize or update scene geometry. "an initial 3D geometry memory is established via a feed-forward point map estimation method (e.g., VGGT~\cite{wang2025vggt} or ~\cite{wang2025pi})"
- field-of-view (FOV): The angular extent of the observable scene captured by a camera; often used in heuristic retrieval but can be misleading under occlusion. "rather than relying on image-level similarity or field-of-view (FOV) heuristics~\cite{yu2025context,li2025vmem,chen2026context}"
- geometry-aware conditioning: A strategy that uses explicit 3D geometry (e.g., point clouds, visibility) to guide diffusion generation for spatially consistent synthesis. "we introduce a geometry-aware conditioning strategy that couples generation and reconstruction through an explicit 3D geometric memory and geometry-driven capture-view retrieval."
- Geometry-Driven View Selection: Selecting reference images based on their geometric contribution and visibility support for the target viewpoint rather than appearance similarity. "we perform geometry-driven view selection from a captured view bank based on geometric contribution and spatial overlap with the current reconstruction"
- Global Scene Memory: A persistent cache of reference views used as keys/values in the diffusion transformer to enable long-range, unordered conditioning. "we introduce a Global Scene Memory mechanism as shown in Fig. \ref{fig:pipeline}(B)."
- Kullback-Leibler (KL) divergence: A divergence measure used to align the student generator’s output distribution with the real/teacher distribution during distillation. "The optimization objective minimizes the Kullback-Leibler (KL) divergence between the student's generated distribution and the real distribution"
- Learned Perceptual Image Patch Similarity (LPIPS): A perceptual metric that compares images using deep features to assess visual similarity beyond pixel-wise differences. "Learned Perceptual Image Patch Similarity (LPIPS) for high-level perceptual quality."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects low-rank updates into pretrained weights. "We implement AnyRecon by fine-tuning the {Wan2.1-I2V-14B}~\cite{wan2025} model using {LoRA}~\cite{hu2022lora} with a rank of $32$."
- NeRF: Neural Radiance Fields; an implicit neural representation that models view-dependent radiance for novel view synthesis and rendering. "implicit representations such as NeRF~\cite{mildenhall2021nerf}"
- Non-Compressive Latent Encoding: A design that avoids temporal compression to preserve frame-level correspondences and spatial fidelity across wide baselines. "AnyRecon employs Non-Compressive Latent Encoding."
- novel view synthesis: Generating new views of a scene from unseen camera poses while maintaining geometric and appearance consistency. "Novel view synthesis and 3D reconstruction are fundamental problems in computer vision and graphics"
- point cloud renderings: Projections or rasterizations of a reconstructed point cloud into target viewpoints used as geometric guidance. "conditions diffusion models primarily on projected point cloud renderings"
- PSNR: Peak Signal-to-Noise Ratio; a metric for pixel-level reconstruction accuracy, higher is better. "Peak Signal-to-Noise Ratio (PSNR) for pixel-level accuracy"
- SSIM: Structural Similarity Index; a metric that evaluates perceived structural fidelity between images, higher is better. "Structural Similarity Index (SSIM) for structural integrity"
- stop-gradient: An operator that prevents gradients from flowing through a tensor, stabilizing training objectives like distillation. "with a stop-gradient () operator"
- temporal compression: Compressing features across time (e.g., via 3D-VAEs), which can harm alignment under large viewpoint changes. "we remove temporal compression in the latent encoder."
- video diffusion model: A generative diffusion model tailored to video data, learning to denoise sequences to synthesize temporally coherent frames. "we employ Distribution Matching Distillation ~\cite{yin2024onestep,yin2024improved} to distill the pre-trained model into a student network ... of the Wan video diffusion model"
- video diffusion transformer: A transformer-based architecture for video diffusion that attends across space-time and conditioning inputs. "video diffusion transformer equipped with context-window sparse attention for scalable long-range conditioning."
- visibility index map: A rendered map indicating which source views contribute visible points to a target viewpoint, used for geometry-driven retrieval. "we render from the target viewpoint to generate a visibility index map"
- visibility masks: Binary or soft masks indicating which geometry or pixels are visible from a target viewpoint, used to inform the diffusion model. "their corresponding visibility masks , both of which are derived from the 3D geometry memory "
Collections
Sign up for free to add this paper to one or more collections.