Denoising, Fast and Slow: Difficulty-Aware Adaptive Sampling for Image Generation
Abstract: Diffusion- and flow-based models usually allocate compute uniformly across space, updating all patches with the same timestep and number of function evaluations. While convenient, this ignores the heterogeneity of natural images: some regions are easy to denoise, whereas others benefit from more refinement or additional context. Motivated by this, we explore patch-level noise scales for image synthesis. We find that naively varying timesteps across image tokens performs poorly, as it exposes the model to overly informative training states that do not occur at inference. We therefore introduce a timestep sampler that explicitly controls the maximum patch-level information available during training, and show that moving from global to patch-level timesteps already improves image generation over standard baselines. By further augmenting the model with a lightweight per-patch difficulty head, we enable adaptive samplers that allocate compute dynamically where it is most needed. Combined with noise levels varying over both space and diffusion time, this yields Patch Forcing (PF), a framework that advances easier regions earlier so they can provide context for harder ones. PF achieves superior results on class-conditional ImageNet, remains orthogonal to representation alignment and guidance methods, and scales to text-to-image synthesis. Our results suggest that patch-level denoising schedules provide a promising foundation for adaptive image generation.

















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making AI image generators smarter by not treating every part of an image the same. Instead of cleaning up (denoising) the whole picture evenly, the model looks at the image in small tiles (patches) and spends more effort where things are tricky (like tiny text or sharp edges) while moving faster where things are simple (like sky or flat backgrounds). The authors call this idea Patch Forcing (PF).
Think of it like un-blurring a photo in stages: some parts become clear quickly, while others need more careful work. If the easy parts clear up first, they can help the model figure out the hard parts.
What questions are the researchers asking?
- Can an image model work better if it treats different areas of an image differently—going faster on easy parts and slower on hard parts?
- How can we train a model to handle different noise levels in different patches without “cheating” during training?
- Can the model learn to tell which patches are easy or hard and use that to plan its denoising steps?
- Will this make the final images sharper, more accurate, and better at details like text?
How did they approach the problem?
The team used three main ideas. Here they are in everyday language:
1) Training without “cheating”: a smarter way to add noise
Image generators learn by practicing how to turn noisy images into clean images. Usually, they add the same amount of noise everywhere. Here, the authors add different amounts of noise to different patches (tiles) of the image during training.
- Problem: If some patches are too clean during training, the model gets easy hints it won’t have at test time (when it starts from pure noise). That’s like practicing a test with answers printed in the margin.
- Their fix: They cap how clean any patch can be during training (they pick a “maximum cleanliness” and only sample patch cleanliness levels below it). This keeps training fair and closer to what happens at test time. They also make sure the overall mix of noise levels stays balanced over many training examples.
In the paper this is called the Logit-Normal Truncated Gaussian (LTG) sampler. You can think of it as:
- “Set a ceiling on how clean any patch can be, then spread the rest of the patches below that ceiling in a smooth, varied way.”
2) Teaching the model to know what’s hard
They add a tiny “difficulty head” to the model that predicts how hard each patch will be to denoise right now. You can think of this like a confidence map:
- Low difficulty (high confidence): the model thinks it can clean this patch quickly.
- High difficulty (low confidence): the model wants more attention or more context from other patches.
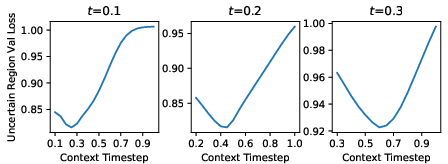
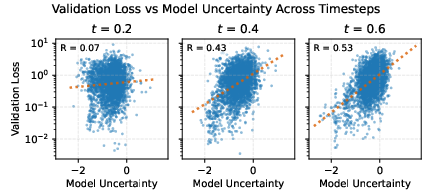
They train this by letting the model estimate how uncertain it is about its denoising in each patch. The authors show that this difficulty score matches real trouble spots: high predicted difficulty lines up with higher errors, and giving the model more context lowers both difficulty and error.
3) Adaptive sampling at test time: letting easy patches help the hard ones
Using the difficulty map, the model changes how it spends its effort during image generation:
- Dual-loop: At each step, the model moves easy patches forward with bigger steps (faster), then uses those clearer patches as context while it carefully refines the hard patches with smaller steps.
- Look-ahead: The model “looks into the future” for easy patches by pushing them a bit further ahead (toward cleaner states) and uses those to guide the hard patches right now.
These strategies mean the model stops wasting time on parts that are already easy and instead uses that time to resolve tricky details.
What did they find, and why is it important?
- Patch-level noise helps: Simply allowing patches to have different noise levels (when trained properly) already improves image quality compared to standard methods that treat every patch the same.
- Difficulty maps are meaningful: The model’s predicted difficulty strongly matches which areas are actually hard to denoise, and extra context from easy patches reduces both difficulty and error where it’s needed most.
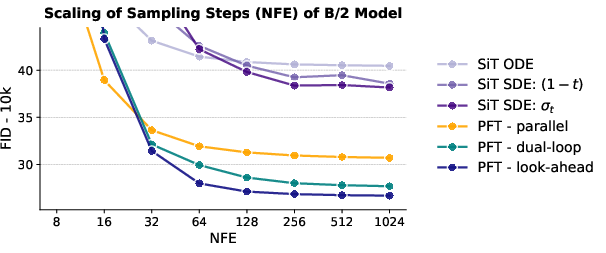
- Adaptive samplers work better: The dual-loop and look-ahead strategies produce better images than regular uniform sampling under the same compute budget. In other words, it’s not just smarter—it’s also more efficient.
- Strong results on benchmarks: On ImageNet (a classic image dataset), Patch Forcing improves over solid baselines (like SiT/DiT), and it works well with other techniques such as guidance methods (e.g., REPA, CFG) instead of conflicting with them. It also scales to text-to-image generation and helps with tough details like rendering readable text.
In simple terms: letting easy parts finish first gives the model clearer clues for the hard parts, leading to sharper, more accurate images without extra compute.
What does this mean going forward?
- Smarter use of compute: AI image models can allocate their effort where it matters most, making better pictures with the same (or even less) time.
- Better detail handling: Fine structures, object boundaries, and text can come out clearer because hard areas get more focused attention when they need it.
- Plays well with others: Patch Forcing can be combined with popular guidance and alignment methods, so it’s a building block rather than a replacement.
- Future extensions: This patch-by-patch, difficulty-aware idea could make even bigger gains for faster models that take fewer steps, or for tasks like video and editing, where some parts are naturally easier or need to be consistent over time.
Overall, the big idea is simple and powerful: don’t treat every pixel the same. Let easy parts lead the way so they can help the hard parts catch up.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues that future work could address, distilled from the paper’s scope, assumptions, and empirical coverage.
- Lack of theoretical grounding: No formal analysis explains why advancing “easy” patches improves denoising dynamics or convergence in flow/diffusion frameworks, nor how heterogeneous timesteps affect stability and bias.
- Residual train–test mismatch: Training never explicitly simulates the dual-loop or look-ahead schedules used at inference. It is unclear whether training with schedule-mimicking curricula would further reduce mismatch or improve robustness.
- Sensitivity of LTG sampler: The effects of the Logit-Normal Truncated Gaussian hyperparameters (, , ) on performance, stability, and coverage are not systematically studied; guidelines for selecting them are absent.
- Uncertainty calibration and reliability: The “difficulty” head’s calibration quality is not quantified (e.g., ECE, reliability diagrams), and there is no comparison to alternative uncertainty estimates (ensembles, MC-dropout, test-time augmentation).
- Failure modes of adaptive progression: The paper does not analyze cases where “confident” patches are misidentified, potentially propagating errors to uncertain regions; mechanisms for error detection, rollback, or consistency checks are missing.
- Patch size and partitioning: The method assumes a fixed patch grid; effects of patch size, overlap, superpixel/segment-based groupings, or adaptive patching on performance and artifacts at patch boundaries remain unexplored.
- Boundary artifacts and global coherence: There is no systematic evaluation for seams, inconsistent lighting, or geometry across patch boundaries induced by heterogeneous timesteps.
- Compute and memory overheads: Wall-clock training and inference costs, memory footprint, throughput, and cache behavior for LTG sampling and adaptive strategies (dual-loop, look-ahead) are not reported.
- Fairness of “fixed NFE” comparisons: Dual-loop and look-ahead introduce inner/outer steps and selective updates; the paper lacks a precise accounting to guarantee identical effective NFEs and fair runtime comparisons against baselines.
- Generalization across resolutions and datasets: Results focus on ImageNet at 256×256 and a single T2I setup; scalability to 512/1024, other domains (e.g., LSUN, COCO), and challenging long-tail distributions is not demonstrated.
- Architectural generality: Experiments are on DiT/SiT-like Transformers; applicability to U-Nets, pixel-space diffusion, consistency models, and distilled few-step samplers (explicitly cited as future work) is untested.
- Interaction with guidance methods: While claimed orthogonal, the interaction with varying CFG scales and newer guidance techniques (e.g., SAG, PAG, ERG) is not systematically analyzed for quality–diversity trade-offs.
- Integration with inference-time acceleration: The paper suggests complementarity to caching methods (e.g., Region-Adaptive Sampling), but provides no empirical evidence of combined fidelity/speed benefits.
- Robustness and OOD behavior: Sensitivity to uncertainty miscalibration, adversarial or rare prompts/classes, domain shifts, and failure rates under OOD conditions are not evaluated.
- Policy design for compute allocation: Uncertainty thresholding is heuristic; there is no exploration of top-k selection, soft weighting, learned step-size controllers, or reinforcement learning to optimize patch-wise budgets.
- Look-ahead step sizing: The proportional step design lacks ablations (e.g., different δt schedules, adaptive step sizes, multi-step look-ahead), leaving the optimal context advancement strategy unresolved.
- Diversity and coverage metrics: Beyond FID/sFID/IS/precision/recall, broader diversity metrics (e.g., coverage curves, CLIP diversity), human studies, and per-region error analyses are missing.
- Text rendering evaluation: The improved spelling is qualitative; there is no standardized text-legibility benchmark or quantitative measurement of text fidelity under controlled prompts.
- Calibration of loss weighting (λ): The heteroscedastic NLL weight is fixed (0.01) without sensitivity analysis; its impact on uncertainty quality and generative performance is unclear.
- Long-range dependencies: Effects of local heterogeneous timesteps on modeling long-range spatial relationships are not probed (e.g., compositionality, multi-object layouts), beyond limited T2I benchmarks.
- Data and training details: Reproducibility gaps include limited reporting on training seeds/variance, compute budgets, and hyperparameter sweeps for LTG and sampler thresholds.
- Bias in compute allocation: Whether the method over-allocates compute to backgrounds/low-frequency regions or systematically under-serves small objects and thin structures is not measured.
- Multi-scale and hierarchical forcing: The approach does not explore coarse-to-fine or hierarchical schedules (e.g., coarse patches advance first, then finer patches), which could better leverage context.
- Extension beyond images: While inspired by video Diffusion Forcing, spatio-temporal Patch Forcing for video and other modalities (audio, 3D, multi-view) is untested and raises additional consistency challenges.
Practical Applications
Overview
Based on the paper’s contributions—per‑patch timesteps, the Logit‑Normal Truncated Gaussian (LTG) training sampler, and difficulty‑aware adaptive samplers (dual‑loop and look‑ahead)—there are multiple practical applications that improve quality, efficiency, and controllability of diffusion/flow-based image generators. Below are actionable use cases, grouped by deployment horizon, with sector links, potential tools/workflows, and key dependencies.
Immediate Applications
These can be prototyped and deployed with modest engineering when retraining or fine‑tuning of image generators is feasible.
- Adaptive sampling to improve image quality at fixed compute
- Sector(s): software (AI image platforms), creative industries, gaming, e‑commerce
- What: Replace uniform denoising with PF’s dual‑loop or look‑ahead samplers to reallocate the same NFE toward locally difficult patches (boundaries, small text, thin structures), improving FID and perceptual quality without increasing latency.
- Potential tools/workflows: “PF-Sampler” drop‑in scheduler for DiT/SiT pipelines; toggleable “Adaptive Quality” mode in T2I services.
- Assumptions/Dependencies: Requires a PF‑trained model (per‑patch timestep conditioning + uncertainty head). Thresholds for confidence need calibration; monitoring to ensure prompt‑wise stability.
- Cost and energy reduction for cloud inference
- Sector(s): cloud AI, energy/sustainability
- What: At a target quality, use PF samplers to cut redundant updates on easy regions, reducing NFEs or GPU time per image.
- Potential tools/workflows: Per‑image “compute governor” that chooses PF schedules based on predicted uncertainty distributions; A/B tested against uniform Euler.
- Assumptions/Dependencies: Quantification of quality vs. cost trade‑off; SRE/FinOps hooks to track quality metrics and energy savings.
- Better text rendering and fine structure fidelity in T2I
- Sector(s): advertising, branding, UX/product design, education
- What: Use the look‑ahead sampler to advance confident background regions and provide cleaner context for text strokes and small logos, improving legibility (as observed in paper).
- Potential tools/workflows: “Text clarity mode” that triggers look‑ahead whenever OCR confidence is low; integration with caption- or OCR-based post‑checks.
- Assumptions/Dependencies: Training data must include text examples; still limited by the base model’s text fidelity; prompt engineering best practices remain useful.
- Higher‑quality inpainting and local editing with internal context
- Sector(s): photo/video editing, restoration, product mockup tools
- What: Use patch‑level difficulty to denoise confident regions first and condition uncertain masked areas, improving boundaries and occlusion transitions during inpainting or localized edits.
- Potential tools/workflows: Inpainting “context‑first” refinement preset; mask‑aware PF sampler that treats masked areas as high‑uncertainty.
- Assumptions/Dependencies: Inpainting or conditioning support in the backbone model; may need re‑training with inpainting masks for best results.
- Interpretability and QA via uncertainty heatmaps
- Sector(s): academia, platform QA, enterprise content workflows
- What: Expose per‑patch uncertainty maps to pinpoint likely failure regions, guide manual touch‑ups, or trigger re‑sampling only where needed.
- Potential tools/workflows: “Uncertainty overlay” in creative UIs; automatic re‑render of high‑uncertainty patches; prompt troubleshooting dashboards.
- Assumptions/Dependencies: Uncertainty correlates with local error (shown in paper); calibration may be needed per domain/model.
- Training recipe upgrade with LTG sampler
- Sector(s): ML research/engineering, model providers
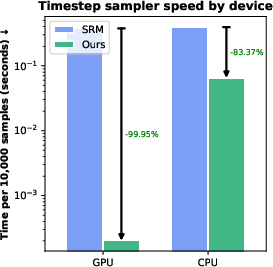
- What: Replace SRM’s uniform-mean approach with LTG to avoid train‑test mismatch by controlling t_max and broadening per‑patch timestep variety—leading to better downstream generation.
- Potential tools/workflows: Training pipeline flag for “LTG timesteps”; hyperparameter sweeps for m, s, σ; unit tests against SRM schedules.
- Assumptions/Dependencies: Re‑training or continued training; code changes to timestep sampler; validation on target datasets.
- Orthogonal gains with guidance and representation alignment
- Sector(s): software (model serving), research
- What: Combine PF with CFG and REPA to stack quality gains; deploy PF as a guidance‑agnostic enhancement layer.
- Potential tools/workflows: Pipeline combinators that apply CFG/REPA alongside PF samplers; automated tuning of CFG scales with PF thresholds.
- Assumptions/Dependencies: Pipeline testing to avoid edge cases (oversharpening, overguidance).
Long-Term Applications
These require further research, scaling, and/or systems work to reach production maturity.
- Spatiotemporal adaptive video generation
- Sector(s): media/VFX, social platforms, scientific visualization
- What: Extend per‑patch PF to per‑spatiotemporal tokens (frames × patches), advancing easy regions/frames to guide hard motion/occlusion regions, reducing flicker and improving fine details.
- Potential tools/workflows: Video PF with temporal look‑ahead and dual-loop across frames; scene‑aware compute allocation.
- Assumptions/Dependencies: Training data and memory budget for spatiotemporal models; stability of look‑ahead across motion.
- Few‑step and distilled diffusion with adaptive patch progression
- Sector(s): real‑time apps, AR/VR, on‑device generation
- What: Leverage PF’s context advantage when jumps between timesteps are large (distilled few‑step models), mitigating quality loss by focusing steps on hard patches.
- Potential tools/workflows: “Few‑step PF” libraries; mobile‑optimized schedulers that dynamically budget steps per patch.
- Assumptions/Dependencies: Distillation training tailored to per‑patch timesteps; rigorous latency–quality evaluation on edge devices.
- Hardware/software co‑design for region‑wise updates and caching
- Sector(s): semiconductors, inference frameworks
- What: Accelerate PF by fusing masked per‑patch updates, attention caching for stable regions, and sparse compute kernels.
- Potential tools/workflows: Triton/CUDA kernels for token‑wise timestep embeddings; TensorRT plugins for region caching; integration with Region-Adaptive Sampling.
- Assumptions/Dependencies: Engine support for dynamic token schedules and sparse attention; benchmarking across GPUs/NPUs.
- Safety and quality gates based on uncertainty
- Sector(s): policy/compliance, platform governance, enterprise content
- What: Use uncertainty thresholds to route images for extra refinement or human review when critical elements (e.g., faces, text, logos) are ambiguous.
- Potential tools/workflows: “Uncertainty QA gate” in content pipelines; selective high‑NFE re‑rendering; audit logs linking uncertainty with release decisions.
- Assumptions/Dependencies: Robust correlation between uncertainty and human‑perceived errors across domains; well‑chosen thresholds to minimize false positives/negatives.
- Layout- and composition‑aware generation and editing
- Sector(s): publishing, office productivity, design tools
- What: Combine PF with layout constraints so confident backgrounds guide spatially constrained elements (text blocks, icons), improving adherence to templates.
- Potential tools/workflows: “Layout‑aware PF” that advances non‑critical background early; plugin for Figma/Canva‑like tools.
- Assumptions/Dependencies: Conditioning on layout masks/boxes; training that reflects layout priors.
- Data‑ and compute‑efficient training curricula
- Sector(s): research, training platforms
- What: Use LTG to design curricula that progressively expose models to controlled maximum information, potentially reducing training iterations or improving robustness.
- Potential tools/workflows: Curriculum schedulers built on LTG; adaptive difficulty schedules tied to validation feedback.
- Assumptions/Dependencies: Empirical validation of sample/compute savings at scale; task‑specific tuning.
- Cross‑modal extensions (3D, multimodal editing, medical imaging research)
- Sector(s): graphics/3D asset creation, robotics simulation, healthcare research
- What: Generalize patch‑wise adaptive timesteps to tokens in 3D grids/voxels or multi‑view settings; explore uncertainty‑guided refinement for reconstruction tasks.
- Potential tools/workflows: “PF‑3D” for mesh/voxel generators; uncertainty‑driven multi‑view fusion; research prototypes for MR/CT reconstruction with generative priors.
- Assumptions/Dependencies: Careful safety/validation in clinical contexts; new architectures for 3D tokens; domain‑specific datasets.
- Interactive UIs for creator‑controlled compute allocation
- Sector(s): creative tools, education
- What: Let users paint “must‑be‑correct” regions that PF treats as high‑priority, allocating more steps there while fast‑tracking easy areas for context.
- Potential tools/workflows: Brush‑driven difficulty overrides in design apps; visual progress indicators tied to uncertainty maps.
- Assumptions/Dependencies: UX research; minimal overhead for real‑time responsiveness.
- Standards and benchmarks for “adaptive‑compute” generation
- Sector(s): standards bodies, environmental reporting, platform policy
- What: Define metrics for quality‑per‑joule and region‑wise error under adaptive sampling; establish reproducible benchmarks for PF‑style methods.
- Potential tools/workflows: Open leaderboards reporting NFE/energy alongside FID/CLIP metrics; dataset annotations for region difficulty.
- Assumptions/Dependencies: Community adoption; standardized measurement of energy and compute in inference.
Notes on feasibility across applications:
- Model requirements: PF necessitates per‑token timestep conditioning and a lightweight uncertainty head; these are straightforward changes for DiT/SiT architectures but typically require re‑training or fine‑tuning.
- Calibration: Thresholds for “confident vs. uncertain” regions and look‑ahead parameters are workload‑dependent and benefit from validation‑time tuning.
- Compatibility: PF is orthogonal to CFG, REPA, and attention‑based guidance; integration typically improves quality further but needs pipeline‑specific testing.
- Data and domain shift: Uncertainty‑quality correlation holds empirically in reported settings; domain‑specific retraining may be needed for specialized imagery (e.g., dense text, diagrams, medical scans).
Glossary
- Adaptive LayerNorm (AdaLN): A conditioning mechanism that modulates LayerNorm parameters using external signals (e.g., timestep), enabling time- or token-dependent transformations. "Since Diffusion Transformers~\cite{ma2024sit,peebles2023scalable-dit} already broadcast scalar timesteps through Adaptive LayerNorm~\cite{zhu2024sd-dit} across spatial locations, this only requires a minimal adaptation: we simply extend the same mechanism to support spatially varying timesteps."
- Aleatoric uncertainty: Uncertainty arising from inherent noise or ambiguity in the data, not reducible by more data. "We explicitly repurpose this score as a measure of local patch difficulty rather than as epistemic or aleatoric uncertainty~\cite{seitzerpitfalls}."
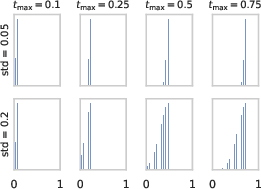
- Bates distribution: The distribution of the mean of i.i.d. uniform variables; for many uniforms it concentrates near the center of the interval. "They observe that independently sampling for each patch leads to the mean following a Bates distribution, which is heavily concentrated around $0.5$ and deviates substantially from the expected inference-time distribution."
- Classifier-Free Guidance (CFG): A guidance technique that blends conditional and unconditional model predictions to steer generation toward conditioning signals. "While Classifier-Free Guidance (CFG) \cite{ho2021classifier_cfg} improves generation quality, it suffers from quality-diversity trade-offs and can push samples away from the data manifold at high guidance scales."
- Data manifold: The (typically lower-dimensional) set of likely data points embedded in high-dimensional space that generative models aim to approximate. "While Classifier-Free Guidance (CFG) \cite{ho2021classifier_cfg} improves generation quality, it suffers from quality-diversity trade-offs and can push samples away from the data manifold at high guidance scales."
- Diffusion Forcing: A training and sampling scheme that assigns different noise levels (timesteps) to different elements (e.g., patches or frames) so partially denoised parts can guide noisier ones. "We implement our approach using Diffusion Forcing~\cite{chen2024diffusion_forcing}, a method that applies different noise levels during training and sampling."
- Diffusion Transformer (DiT): A transformer-based architecture tailored for diffusion models, operating on spatial tokens instead of U-Net feature maps. "Diffusion Transformers (DiTs)~\cite{peebles2023scalable-dit} replaced U-Net architectures in the latent diffusion model paradigm~\cite{rombach2022high-sd-ldm} with transformers operating on spatial patches."
- Dirac delta distribution: A degenerate distribution concentrated at a single point (infinite density at that point, zero elsewhere). "Setting collapses the distribution to a Dirac delta distribution, reducing our method to standard Flow Matching."
- Dual-Loop (sampler): An adaptive sampler that advances confident patches with larger time steps while refining uncertain patches with smaller steps, iteratively re-estimating uncertainty. "We term our first sampler dual-loop as it preferentially advances confident regions to provide context for uncertain ones, while also refining the latter with more steps."
- Epistemic uncertainty: Uncertainty due to limited model knowledge or parameters, reducible with more data or model capacity. "We explicitly repurpose this score as a measure of local patch difficulty rather than as epistemic or aleatoric uncertainty~\cite{seitzerpitfalls}."
- Euler sampling: A first-order numerical integration scheme for simulating ODE-based denoising trajectories in diffusion/flow models. "With fixed architecture and NFE, our Patch Forcing Transformer (PFT) already outperforms the baseline under standard Euler sampling."
- Flow Matching (FM): A training approach that learns a velocity field guiding samples along a predefined path (interpolant) from noise to data. "Flow Matching (FM) models \cite{liu2022rectifiedflow, albergo2023stochastic, lipman2022flow} gradually deteriorate data samples using a predefined noising schedule and then learn a neural network to reverse this process."
- Fréchet Inception Distance (FID): A metric comparing generated and real image distributions via Fréchet distance between feature embeddings; lower is better. "In~\cref{tab:dit} we report FID-50k on ImageNet~\cite{russakovsky2015imagenet}."
- Function evaluations (NFE): The number of model evaluations performed during sampling; often correlates with computational cost and sample quality. "Across increasing numbers of function evaluations (NFE), our PFT-B/2 model consistently outperforms the SiT-B/2 ODE and SDE baselines."
- Heteroscedastic uncertainty: Input-dependent predictive variance modeled by the network, allowing different noise levels across inputs. "SRM~\cite{wewer2025spatial_srm} learn the uncertainty as standard deviation and minimize the negative log-likelihood of the ground truth noise, similar to heteroscedastic uncertainty estimation~\cite{seitzerpitfalls}."
- Interpolant: A continuous path that blends noise and data across timesteps, defining the trajectory along which the model learns the velocity/score. "The interpolant on the continuous timesteps is defined as"
- Latent diffusion model paradigm: A framework that performs diffusion in a learned latent space rather than pixel space for efficiency and quality. "Diffusion Transformers (DiTs)~\cite{peebles2023scalable-dit} replaced U-Net architectures in the latent diffusion model paradigm~\cite{rombach2022high-sd-ldm} with transformers operating on spatial patches."
- Logit-Normal (distribution): A distribution obtained by applying the logistic (sigmoid) function to a normally distributed variable; useful for sampling bounded variables like timesteps. "we adopt the Logit-Normal timestep sampler from~\cite{esser2024scaling-sdv3}"
- Logit-Normal Truncated Gaussian (LTG) sampler: The paper’s timestep sampler that draws a global maximum from a logit-normal and per-patch timesteps from a lower-half truncated Gaussian. "We term our sampler Logit-Normal Truncated Gaussian (LTG), and formalize it as"
- Monte Carlo sampling: Estimation technique using repeated random sampling to approximate quantities like variances or expectations. "measuring the per-patch empirical variance via Monte Carlo sampling."
- Negative log-likelihood (NLL): A loss function that encourages the model’s predicted distribution to assign high probability to observed targets. "we model this difficulty as the predicted standard deviation and minimize the negative log-likelihood (NLL) of the ground-truth conditional velocity"
- ODE sampling: Sampling via solving an ordinary differential equation that traces a deterministic reverse-time trajectory in diffusion/flow models. "Notably, our adaptive samplers improve over both ODE and SDE sampling by a large margin."
- Patch Forcing (PF): The proposed framework using per-patch timesteps and predicted patch difficulty to advance easy regions and provide context for harder ones. "Combined with noise levels varying over both space and diffusion time, this yields Patch Forcing (PF), a framework that advances easier regions earlier so they can provide context for harder ones."
- Patch Forcing Transformer (PFT): The implementation of Patch Forcing in a transformer backbone for image synthesis. "We show that our Patch Forcing Transformer (PFT) consistently improves performance on the standard ImageNet generation benchmark~\cite{russakovsky2015imagenet}, and demonstrate that it enables sampling strategies to improve quality."
- Predictor-corrector sampling: A two-stage sampling scheme where a deterministic predictor step is followed by a stochastic corrector to refine uncertain regions. "Score-based diffusion models~\cite{song2020score} similarly perform adaptive refinement via predictor-corrector sampling, where stochastic corrector steps refine uncertain regions after each deterministic prediction, showing that heterogeneous refinement improves sample quality."
- Representation alignment (REPA): A guidance/conditioning method aligning internal representations to improve fidelity; used here as a complementary technique. "In addition, \cref{tab:dit} shows that pairing PFT-XL/2 with REPA yields comparable relative gains and improves over the SiT baseline in both settings, indicating that Patch Forcing is orthogonal to representation alignment."
- SDE sampling: Sampling via solving a stochastic differential equation that maintains stochasticity during the reverse process. "Notably, our adaptive samplers improve over both ODE and SDE sampling by a large margin."
- Spatial Reasoning Models (SRM): Models that adapt Diffusion Forcing to spatial tasks and propose sampling schemes to control patch-wise timestep distributions. "Spatial Reasoning Models (SRM)~\cite{wewer2025spatial_srm} adapts Diffusion Forcing~\cite{chen2024diffusion_forcing} for spatial reasoning tasks, showing that generation order can be learned and leveraged to improve spatial reasoning."
- Stop gradient operation: An operator that blocks gradients from flowing through a tensor during backpropagation, used to stabilize auxiliary predictions. "where is the stop gradient operation and the NLL loss weight."
- Truncated Gaussian (distribution): A Gaussian distribution restricted to a subset of its support (e.g., the lower half), renormalized to form a valid distribution. "where is the lower half of a Gaussian distribution centered and truncated at with standard deviation "
- Uncertainty head: An auxiliary network head predicting per-patch uncertainty (e.g., variance/standard deviation) to guide adaptive denoising. "To determine which patches should be denoised earlier than others, we use a learned uncertainty head that predicts patch-wise uncertainty for the model's velocity estimate, similar to~\cite{wewer2025spatial_srm, nichol2021improvedDDPM}."
- Vector field: A field over the data space assigning a vector (direction and magnitude) at each point, here representing the direction from noise toward data. "We train a denoising model to regress a vector field along the noising trajectory, following the linear path that points from to "
- Velocity field: The specific vector field indicating instantaneous direction of flow along the denoising trajectory (often synonymous with the model’s output in FM). "Given the input, our model predicts a patch difficulty map over the velocity field, separating \textcolor{easy{confident} (easy) from \textcolor{hard{uncertain} (hard) denoising regions."
Collections
Sign up for free to add this paper to one or more collections.