Advancing Vision Transformer with Enhanced Spatial Priors
Published 20 Apr 2026 in cs.CV | (2604.18549v1)
Abstract: In recent years, the Vision Transformer (ViT) has garnered significant attention within the computer vision community. However, the core component of ViT, Self-Attention, lacks explicit spatial priors and suffers from quadratic computational complexity, limiting its applicability. To address these issues, we have proposed RMT, a robust vision backbone with explicit spatial priors for general purposes. RMT utilizes Manhattan distance decay to introduce spatial information and employs a horizontal and vertical decomposition attention method to model global information. Building on the strengths of RMT, Euclidean enhanced Vision Transformer (EVT) is an expanded version that incorporates several key improvements. Firstly, EVT uses a more reasonable Euclidean distance decay to enhance the modeling of spatial information, allowing for a more accurate representation of spatial relationships compared to the Manhattan distance used in RMT. Secondly, EVT abandons the decomposed attention mechanism featured in RMT and instead adopts a simpler spatially-independent grouping approach, providing the model with greater flexibility in controlling the number of tokens within each group. By addressing these modifications, EVT offers a more sophisticated and adaptable approach to incorporating spatial priors into the Self-Attention mechanism, thus overcoming some of the limitations associated with RMT and further enhancing its applicability in various computer vision tasks. Extensive experiments on Image Classification, Object Detection, Instance Segmentation, and Semantic Segmentation demonstrate that EVT exhibits exceptional performance. Without additional training data, EVT achieves 86.6% top1-acc on ImageNet-1k.
The paper introduces EVT, a vision transformer that incorporates explicit Euclidean spatial priors to improve spatial attention over traditional Manhattan decay.
It employs a novel one-dimensional and dilated token grouping mechanism to achieve linear complexity and enhanced throughput.
Empirical results, including an 86.6% top-1 accuracy on ImageNet-1K, demonstrate EVT's superior performance and robustness across multiple vision tasks.
Enhanced Spatial Priors in Vision Transformers: The EVT Framework
Background and Motivation
The Vision Transformer (ViT) architecture has achieved notable success in computer vision, but it is fundamentally limited by its lack of explicit spatial priors and the quadratic computational complexity of its self-attention mechanism. Unlike convolutions, which inherently encode locality and spatial structure, standard self-attention treats all token pairings equally, failing to exploit spatial context. Prior attempts to address these issues include window-based attention (Swin Transformer), neighborhood modulation (NAT), and explicit spatial decay (RMT). However, these solutions introduce specific trade-offs in terms of computational complexity, spatial inductive bias, and flexibility.
This paper introduces the Euclidean enhanced Vision Transformer (EVT), which incorporates explicit spatial priors via Euclidean distance-based decay matrices in the attention mechanism. The model replaces the Manhattan distance decay of RMT with a more natural, isotropic Euclidean decay and abandons decomposition-based attention for a spatially-independent, one-dimensional token grouping method, achieving linear complexity and enhancing top-1 accuracy. Extensive experiments validate EVT's improvements across multiple vision tasks.
EVT Architecture and Methodological Advances
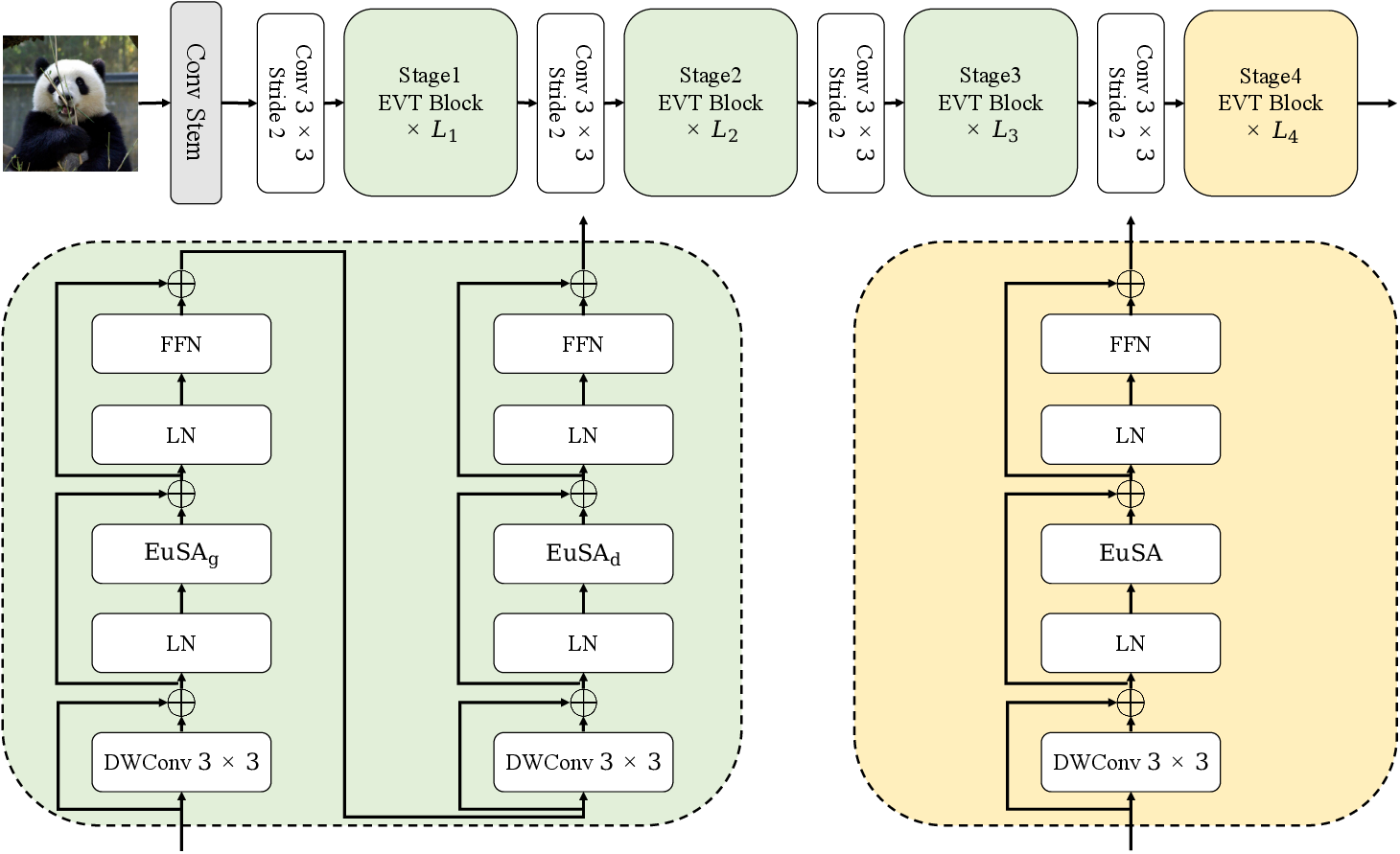
EVT begins with a hierarchical model structure, progressing through multiple stages utilizing progressively downsampled feature maps. Each stage consists of three modules: Conditional Positional Encoding (CPE), Euclidean Self-Attention (EuSA), and Feed-Forward Network (FFN). The architecture processes token tensors with CPE to inject positional information, applies EuSA for token mixing with explicit spatial decay, and uses FFN for channel integration.
Figure 1: Overall architecture of EVT, showing hierarchical modular processing and the integration of EuSA for spatially-aware attention.
Spatial Decay: From Manhattan to Euclidean Distance
The spatial decay mechanism is central to EVT. Whereas RMT utilizes Manhattan distance—favoring axis-aligned locality but failing to match natural image statistics—EVT introduces Euclidean decay, which models radial, isotropic attention decay:
Enm2d=γ(xn−xm)2+(yn−ym)2
Multiple empirical and theoretical analyses demonstrate superior distribution alignment (lower Jensen-Shannon divergence) with Euclidean decay, improved optimization stability (smoother gradients), enhanced spatial coverage, and better entropy characteristics for the attention distribution. EVT also allows per-head decay coefficients, enabling multi-scale receptive fields and richer spatial modeling.
Token Grouping and Computational Efficiency
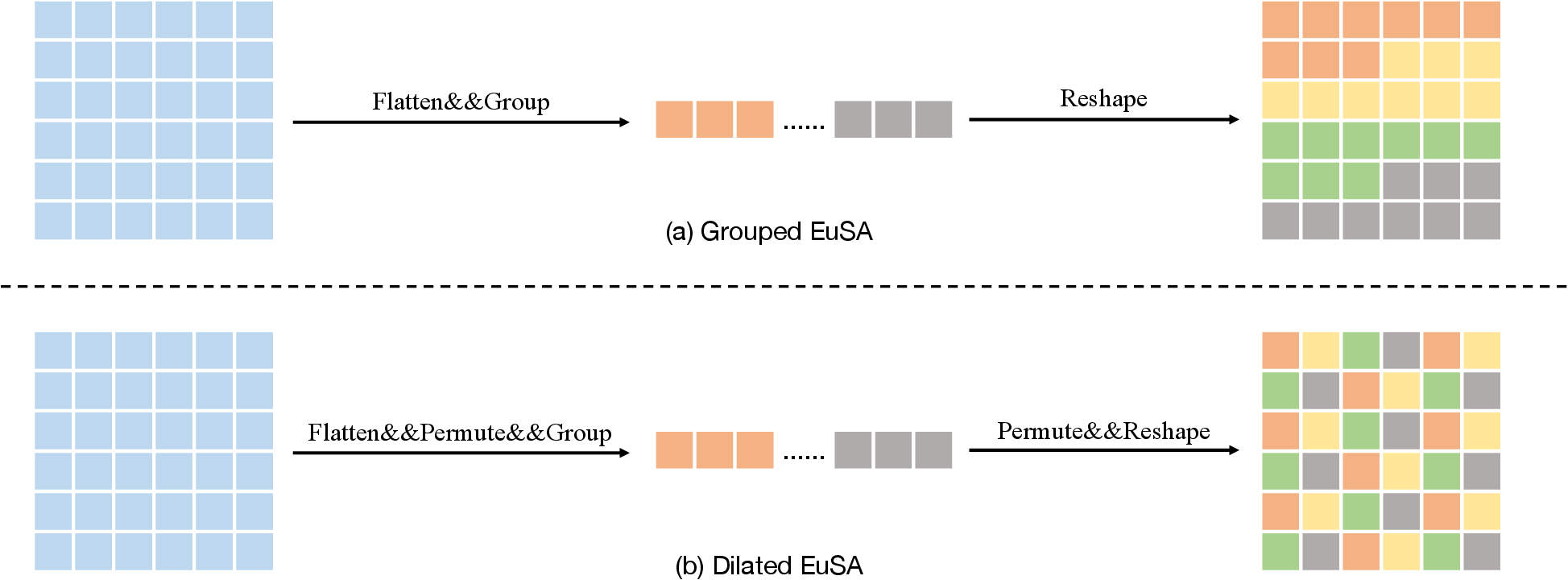
The original RMT employed horizontal/vertical decomposition attention, resulting in O(N1.5) complexity and low parallelism. EVT replaces this strategy with one-dimensional, spatially-independent grouping and dilated grouping, achieving O(Nk) complexity and better throughput. The global field is ensured by alternating group/dilated mechanisms across stages, and spatial priors are restored via the Euclidean decay matrix.
Figure 2: Illustration of grouped EuSA and dilated EuSA. Alternating modalities ensure global receptive field while maintaining spatial sensitivity.
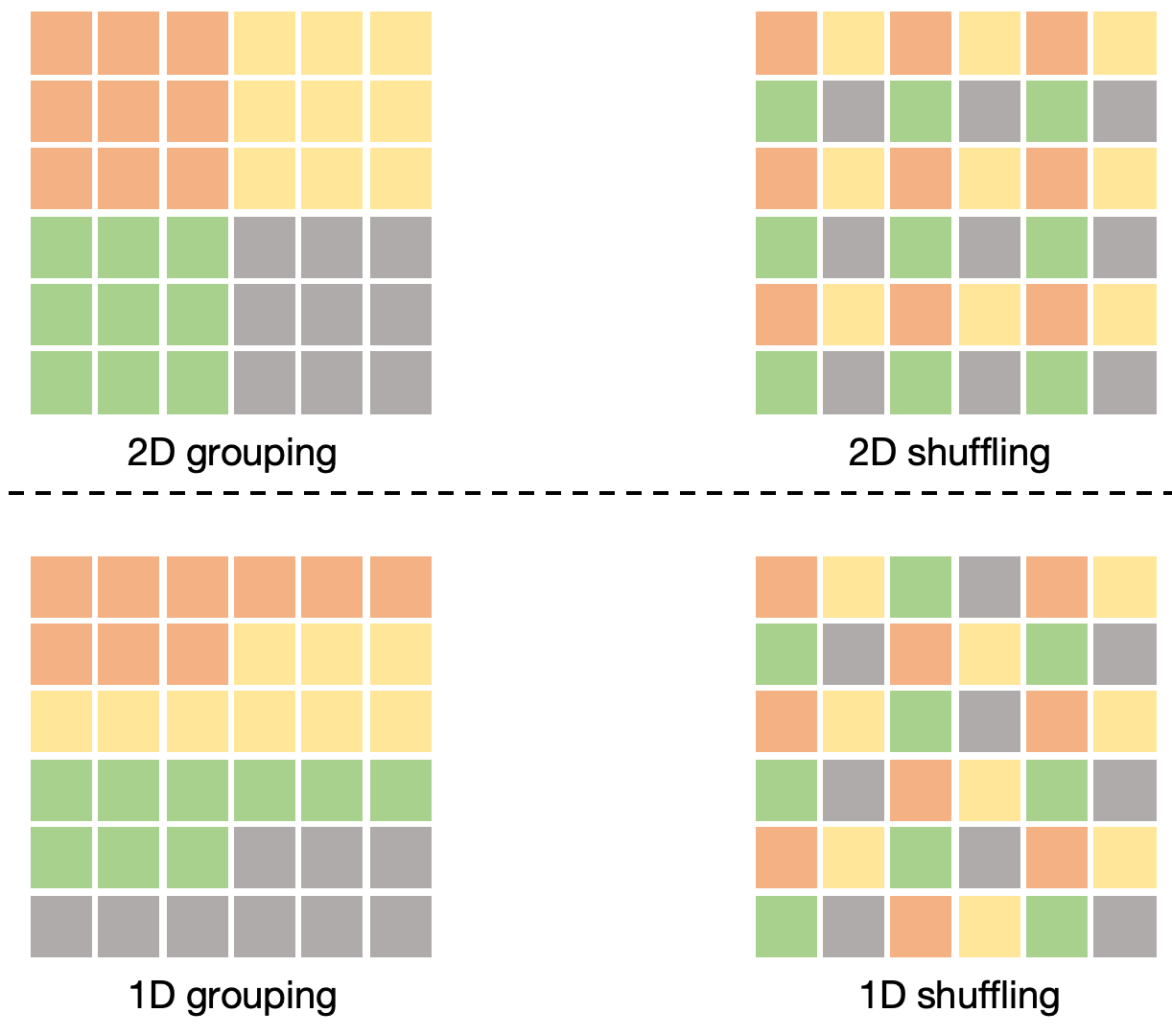
Figure 3: Comparison of 2D grouping/shuffling (window-based) with EVT's 1D grouping/shuffling. 1D grouping achieves higher throughput and flexible receptive fields.
Empirical Results and Numerical Findings
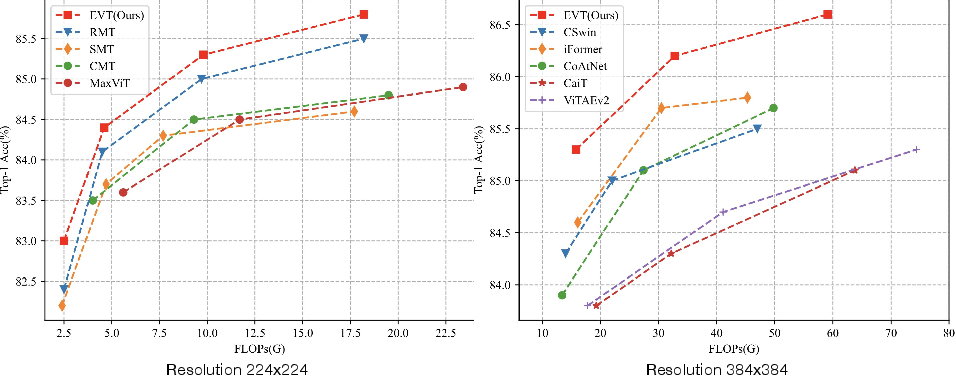
EVT delivers substantial improvements over previous models across diverse benchmarks. On ImageNet-1K, EVT-L achieves 86.6% top-1 accuracy at 384×384 resolution with only 100M parameters, outperforming prior architectures in both accuracy and computational efficiency.
Figure 4: FLOPs versus top-1 accuracy on ImageNet-1K. EVT achieves higher accuracy with lower computational cost compared to previous state-of-the-art.
Comparisons with Swin Transformer, RMT, MaxViT, BiFormer, and convolution-Transformer hybrids demonstrate consistent superiority across image classification, object detection, instance segmentation, and semantic segmentation tasks. EVT also exhibits exceptional robustness on OOD datasets, including ImageNet-A and ImageNet-R, with strong performance under distribution shift.
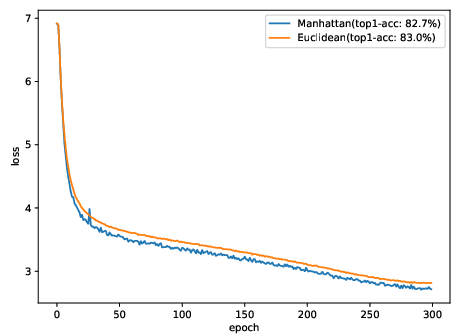
Performance gains are supported by detailed ablations, highlighting the impact of EuSA, grouped attention, convolutional stems, CPE, and LCE modules. Loss curve analyses confirm improved convergence and reduced overfitting with Euclidean decay.
Figure 5: Loss curves for Euclidean distance and Manhattan distance, showing improved stability and generalization with Euclidean decay.
Visualization and Interpretation
Visualization of attention maps demonstrates that the Euclidean decay matrix leads to more concentrated, radially distributed attention, with smoother transitions and improved object localization. In shallow layers, EVT preserves fine-grained spatial detail, while deeper layers maintain strong discriminative focus.
Figure 6: Visualization results: vanilla DeiT vs. DeiT with Manhattan and Euclidean distance priors. Euclidean decay yields sharper, more effective attention distributions.
Figure 7: EVT versus Swin-Transformer attention maps. EVT shows reduced noise and precise object localization, with global spatial coherence.
Practical and Theoretical Implications
EVT’s explicit spatial prior represents a shift in token mixing for vision transformers: it enables isotropic, biologically-inspired modelling of spatial decay, facilitating more effective spatial generalization and robust performance. The one-dimensional grouping paradigm resolves prior efficiency and coverage constraints, making EVT well-suited for high-resolution and dense vision tasks. Theoretical analyses affirm the superiority of Euclidean decay in attention optimization, spectral coverage, and spatial entropy regulation.
EVT’s design principles can inform future transformer architectures, particularly regarding explicit spatial priors, flexible grouping, and multi-scale receptive fields. Application in multi-modal settings, high-resolution vision, and domain-adaptive tasks is warranted. Further extensions may include dynamic decay coefficient learning, domain-adaptive spatial priors, and integration with foundation models in vision-language contexts.
Conclusion
EVT introduces a vision transformer backbone that combines explicit Euclidean spatial priors in attention with efficient grouped token processing. It addresses key limitations in prior models, delivering improved accuracy, robustness, and throughput across vision benchmarks. Theoretical and empirical analyses substantiate EVT's approach, and its design lays groundwork for future advances in spatially-aware vision transformers (2604.18549).