ViT-5: Vision Transformers for The Mid-2020s
Abstract: This work presents a systematic investigation into modernizing Vision Transformer backbones by leveraging architectural advancements from the past five years. While preserving the canonical Attention-FFN structure, we conduct a component-wise refinement involving normalization, activation functions, positional encoding, gating mechanisms, and learnable tokens. These updates form a new generation of Vision Transformers, which we call ViT-5. Extensive experiments demonstrate that ViT-5 consistently outperforms state-of-the-art plain Vision Transformers across both understanding and generation benchmarks. On ImageNet-1k classification, ViT-5-Base reaches 84.2\% top-1 accuracy under comparable compute, exceeding DeiT-III-Base at 83.8\%. ViT-5 also serves as a stronger backbone for generative modeling: when plugged into an SiT diffusion framework, it achieves 1.84 FID versus 2.06 with a vanilla ViT backbone. Beyond headline metrics, ViT-5 exhibits improved representation learning and favorable spatial reasoning behavior, and transfers reliably across tasks. With a design aligned with contemporary foundation-model practices, ViT-5 offers a simple drop-in upgrade over vanilla ViT for mid-2020s vision backbones.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “ViT-5: Vision Transformers for the Mid-2020s” in simple terms
What is this paper about?
This paper is about improving a popular kind of computer vision model called a Vision Transformer (ViT). Think of a ViT like a very smart camera that reads an image in small squares (patches) and decides which parts to pay attention to. The authors bring in a bunch of practical “tweaks” that have helped LLMs (like modern chatbots) over the last five years and apply them carefully to ViTs. The result is a new, upgraded model called ViT-5 that works better without being more complicated.
What questions are the researchers asking?
The paper focuses on simple, practical questions:
- Can the tricks that made LLMs better also make vision models better?
- Which small parts (components) of a ViT should we update—like how it normalizes numbers, how it understands positions in an image, or how it turns signals on and off?
- How do we combine these updates so they help, not hurt?
- Does the upgraded model perform better on different jobs, like recognizing objects, generating images, and understanding pixel-level details?
How did they study this? (Methods explained simply)
The authors took the basic ViT “building block” and swapped in better versions of certain parts, testing one change at a time and in combinations. They kept the overall shape of the model the same (no major redesigns), like upgrading parts of a car engine without changing the car itself. They then tested these versions on:
- Image recognition (classifying photos in ImageNet)
- Image generation (making images with diffusion models)
- Semantic segmentation (labeling which pixel belongs to what)
Here are the main parts they updated, with everyday explanations:
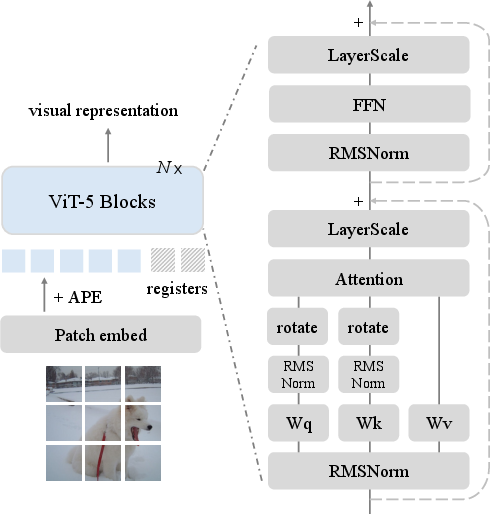
- Normalization (RMSNorm): Like keeping a sound system at a clear, comfortable volume so it doesn’t blow out or get too quiet. RMSNorm is a simple, efficient way to keep numbers under control inside the model.
- LayerScale: Imagine tiny “volume knobs” on each channel inside the network that help stabilize training, especially for deep models. LayerScale adds these knobs so the model learns steadily.
- Activation functions (GeLU vs. SwiGLU): Activations decide how strongly signals “pass through.” SwiGLU uses a “gate,” like a door that can be partly open or closed. But the authors found that combining SwiGLU (gates) with LayerScale (knobs) can make things too quiet—what they call “over-gating.” So they stick with GeLU (simple and effective) to avoid this problem.
- Positional encoding (APE + RoPE): The model needs to know where things are in an image.
- Absolute Position Embeddings (APE) are like grid coordinates (“this is at row 5, column 7”).
- Rotary Position Embeddings (RoPE) help the model understand relative positions (“this patch is to the left of that one”).
- ViT-5 uses both: APE keeps absolute location sense, while RoPE helps the model adapt to different image sizes and focus on relative distances. Using only RoPE can make the model treat some flipped images as the same, which isn’t always correct.
- Register tokens: Think of these as extra “scratch-paper” tokens the model carries along to store helpful notes. They reduce noisy background effects and help the model focus on important parts of the image. ViT-5 also gives these registers their own special positional settings (a high-frequency version of RoPE) so they interact cleanly with image patches.
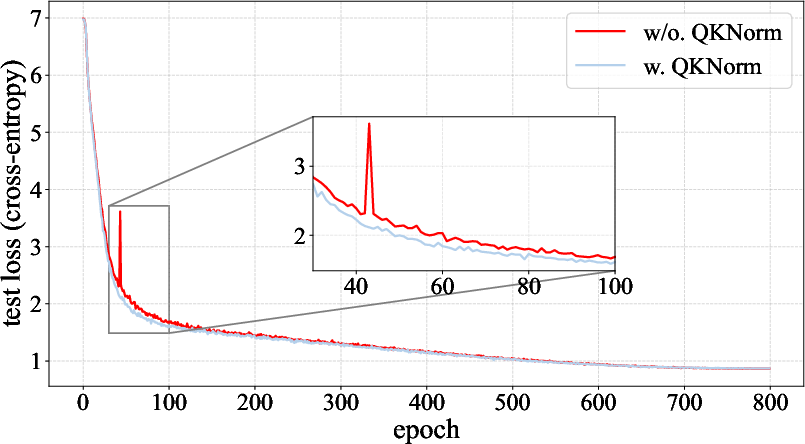
- QK-Norm (Query/Key normalization): In attention, the model compares “queries” and “keys” to decide what to focus on. QK-Norm is like tidying both sides before comparing, which makes training smoother and avoids sudden spikes in the learning process.
- Bias-free QKV projections: The authors remove tiny extra “bias” terms from the attention layers to keep the system cleaner and more stable, especially when combined with QK-Norm.
What did they find, and why does it matter?
The upgraded ViT-5 consistently works better than standard ViTs, without using more compute at the same model size:
- Image recognition (ImageNet-1k):
- ViT-5-Base reaches about 84.2% top-1 accuracy (higher is better), beating a strong baseline (DeiT-III-Base at ~83.8%) with similar compute.
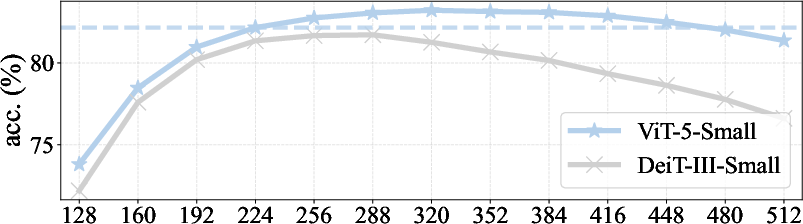
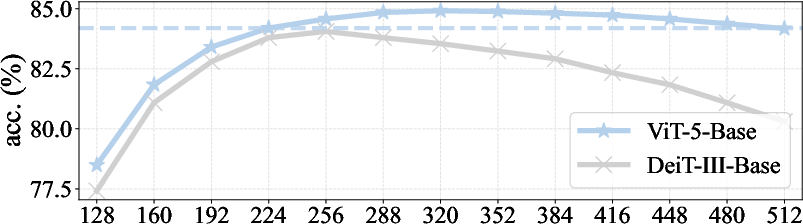
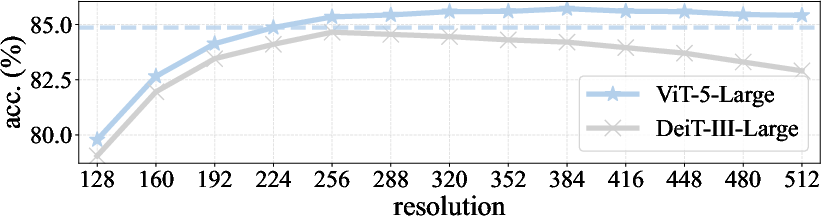
- Larger ViT-5 models also outperform their counterparts, especially at higher image resolutions (e.g., 86.0% for ViT-5-Large at 384×384).
- Image generation (diffusion models):
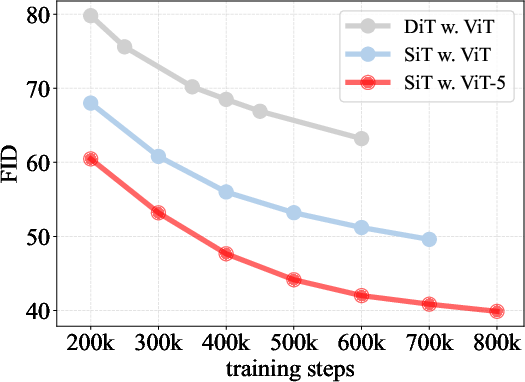
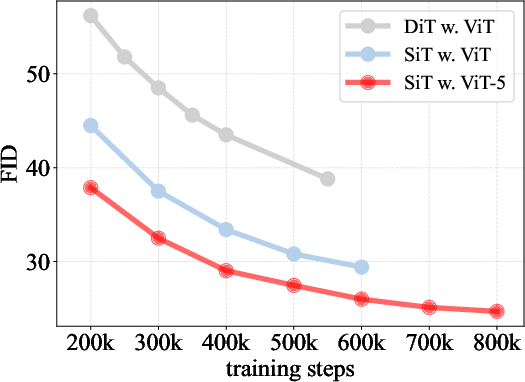
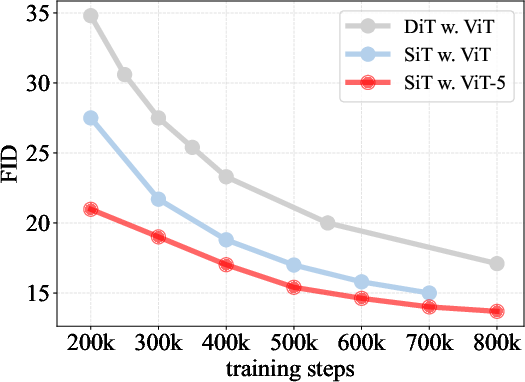
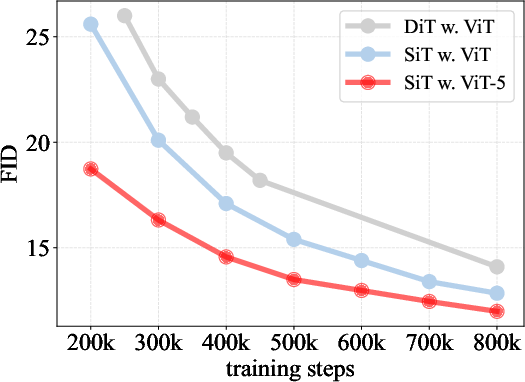
- When ViT-5 is used inside a diffusion generator, the FID score (lower is better) improves from ~2.06 to ~1.84 in a strong setup—meaning crisper, more realistic images.
- Pixel-wise understanding (semantic segmentation):
- ViT-5 gives better accuracy (mIoU) than comparable ViT baselines, and the gains get bigger with larger models.
- Better spatial reasoning and stability:
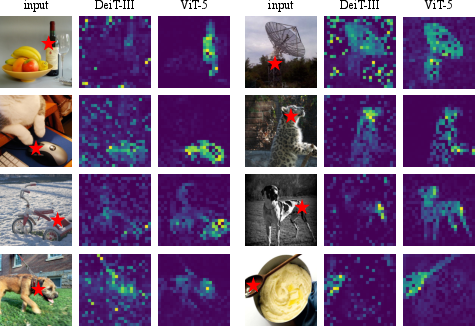
- Attention maps (visualizations of what the model looks at) are cleaner and more focused.
- The model handles different image sizes more reliably.
- Training is more stable, with fewer sudden “loss spikes.”
One important lesson: not all “modern tricks” play nicely together. For example, mixing LayerScale (the knobs) with SwiGLU (the gates) can make the model too quiet—so ViT-5 avoids that combo.
What’s the bigger impact?
- A “drop-in” upgrade: ViT-5 keeps the classic ViT structure, so it’s easy to swap into many systems without rewriting everything.
- Stronger foundation for vision and multimodal AI: Better backbones help with tasks like photo search, image captioning, and image generation—and they make combined text+image systems more reliable.
- Clear design guidance: The paper shows that small, well-chosen updates (normalization, position handling, stability tricks) can bring big wins—no need for complicated redesigns.
- Toward unified transformers: The successful transfer of ideas from LLMs to vision suggests a future where a single, well-tuned Transformer style works across text, images, and beyond.
In short, ViT-5 is a careful refresh of ViTs using proven ideas from recent AI advances. It’s simpler, steadier, and better at “seeing,” making it a practical backbone for vision tasks in the mid-2020s.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of concrete gaps and open questions that remain unresolved and could guide future research:
- Pretraining scale and regimes: ViT-5 is validated with supervised ImageNet-1k training; its behavior under large-scale weakly supervised/self-supervised pretraining (e.g., ImageNet-21K, JFT, LAION) and contrastive multimodal pretraining (e.g., CLIP/SigLIP) is untested.
- Vision–language integration: Claims of better alignment with LLM practices are not substantiated on VLM benchmarks (e.g., COCO/NoCaps captioning, VQA, image–text retrieval, instruction-following with LLaVA/Qwen-VL); end-to-end evaluations are missing.
- Downstream breadth: Core detection/instance segmentation (COCO, LVIS), keypoint/pose estimation, depth/normal estimation, and panoptic/instance segmentation benchmarks are not evaluated.
- Video and spatiotemporal modeling: It is unknown how 2D RoPE, registers, and QK-Norm extend to video (temporal relative positions, temporal registers), or how ViT-5 performs on Kinetics, SSv2, or video generation.
- Robustness and safety: No tests on robustness/shift benchmarks (ImageNet-C/A/R, Stylized-ImageNet), OOD detection, calibration, adversarial robustness, fairness/bias, or safety characteristics of generative outputs.
- Data/compute efficiency: Sample efficiency (few-shot/linear-probe on VTAB), low-data or low-epoch training behavior, and compute-optimal scaling (accuracy vs. FLOPs/epochs) are not characterized.
- Scaling laws: Beyond diffusion FID curves, there is no compute–data–parameter scaling law analysis for classification or dense prediction to assess asymptotic advantages and compute-optimality.
- Training recipe generality: Results hinge on a DeiT-III-style recipe; robustness across optimizers (AdamW vs. LAMB), learning-rate schedules, augmentation strength, and other training regimes is unexamined.
- Over-gating phenomenon: The hypothesized LayerScale × SwiGLU “over-gating” is only observed up to ViT-XL; its presence at larger scales and potential mitigations (e.g., reduced gate ratio, gated-MLP scaling, gate dropout, removing LayerScale in MLP blocks, init schemes) remain open.
- Positional encoding design space: APE+2D RoPE is chosen to avoid patch-flip invariances, but alternatives (ALiBi, T5-style biases, learned relative biases, axis-wise or learned RoPE bases) and their invariance/robustness trade-offs are not explored.
- Absolute vs. relative trade-offs: The impact of adding APE on tasks favoring translational invariance vs. those requiring absolute localization is not quantified; potential task-adaptive positional encoding remains open.
- Resolution extrapolation limits: Dynamic-resolution evaluation stops at 512; stability, accuracy, and memory behavior at higher resolutions (e.g., 768–1024) are unknown.
- Registers: Registers are fixed to 4 and applied uniformly; open questions include optimal number/placement per layer, per-head or per-stage registers, dynamic or input-adaptive registers, and their effects across tasks (detection/segmentation/generation) and tokenizers (VAE/learned).
- Registers in diffusion: The contribution of registers to diffusion performance is not isolated; ablations within the generative setting are missing.
- High-frequency RoPE for registers: The choice of much higher frequency base is heuristic; sensitivity, principled selection, and theoretical justification are not provided.
- QK-Norm interactions: The interplay of QK-Norm with attention temperature, head dimension, FlashAttention kernels, bfloat16/FP8 numerics, and mixed precision is not analyzed; head-wise vs. shared normalization variants are unexplored.
- QKV bias removal: Removing biases improves performance here, but its effect on convergence speed, calibration, dense prediction, and generative quality (and variants like removing only Q/K or only V bias) remains untested.
- Efficiency and systems aspects: Wall-clock training time, throughput, GPU utilization, memory footprint, and inference latency (including overheads from 2D RoPE, QK-Norm, and registers) are not reported; kernel availability/fusion implications are unclear.
- Quantization and compression: Behavior under post-training quantization/quant-aware training (INT8/INT4), sparsity/pruning, and distillation is unknown; bias-free QKV and RMSNorm may interact nontrivially with quantization error.
- Hierarchical/multi-scale compatibility: It is unknown whether ViT-5’s component choices transfer to hierarchical ViTs or multi-scale feature pyramids, and what gains they provide in such settings.
- Patchification choices: Only standard non-overlapping patch embedding is used; effects of patch size, overlapping/conv stem, and learned tokenizers (for understanding as well as generation) are not systematically studied.
- Long-context behavior: Memory/attention stability and accuracy under very long token sequences (e.g., high-res grids or tiled inference) with 2D RoPE and QK-Norm are not evaluated.
- Theoretical grounding: The functional relationship between LayerScale and post-norm, causes of loss spikes mitigated by QK-Norm, and the mechanism of “over-gating” are not theoretically analyzed.
- Fairness of comparisons: Although FLOPs/params are matched, exact training budgets (epochs/steps, augmentation strength, regularization) and energy/carbon cost comparisons across baselines are not fully audited.
- Statistical reliability: Variance across seeds, confidence intervals, and significance testing for reported gains are missing; reproducibility under different random seeds/hardware is unreported.
- Open-source assets: Pretrained weights at multiple scales, training logs, and exact configs to enable third-party replication across frameworks are not detailed in the main text.
- Broader impacts in generation: Potential societal risks (bias, misuse) of improved generative capacity are not assessed, despite measurable gains in FID/IS.
Practical Applications
Immediate Applications
Below are actionable, real-world uses that can be deployed now, drawing on ViT-5’s component-wise upgrades (LayerScale, RMSNorm, QK-Norm, 2D RoPE with APE, register tokens, bias-free QKV) and demonstrated gains in classification, segmentation, and diffusion-based image generation.
- Industry — Vision model backbone upgrade for production pipelines (software, robotics, retail, media)
- Action: Replace vanilla ViT/DeiT backbones with ViT-5 in existing classification, detection, and segmentation systems (e.g., mmdetection, mmsegmentation, Detectron2, timm/Hugging Face pipelines) to gain accuracy (+0.4–0.6% on ImageNet) and stability at comparable FLOPs.
- Tools/Workflows: Drop-in PyTorch modules; export via ONNX/TensorRT; reuse DeiT-III training recipes with minor tweaks; use provided GitHub code.
- Assumptions/Dependencies: Availability of fine-tuning data; kernel support for RMSNorm/QK-Norm in deployment stack; minor retraining to realize gains.
- Industry — Multimodal systems upgrade (software, education, customer support)
- Action: Swap the vision encoder in CLIP/SigLIP/LLaVA/Qwen-VL-like systems with ViT-5 to improve retrieval, captioning, and VQA, leveraging improved spatial reasoning and resolution robustness without changing the attention–FFN topology.
- Tools/Workflows: Re-encode image towers in contrastive pretraining; reuse tokenizer/LLM; adopt 2D RoPE+APE to avoid flip invariance issues.
- Assumptions/Dependencies: Access to multimodal pretraining data; modest retraining; compatibility checks for positional encoding changes.
- Industry — Diffusion model quality boost (media, creative tools, advertising)
- Action: Replace ViT backbones in DiT/SiT diffusion pipelines with ViT-5 to reduce FID (e.g., 2.06 → 1.84 at XL scale) under the same compute.
- Tools/Workflows: Keep SiT training configs; plug in ViT-5 modules; roll out in image generation APIs and creative suites.
- Assumptions/Dependencies: Training compute budget; consistent guidance schedules; content safety filters for higher-quality generations.
- Industry — Resolution-robust perception in variable-camera environments (retail analytics, drones, surveillance)
- Action: Deploy ViT-5 for scenarios with fluctuating input sizes; its combined 2D RoPE+APE maintains or improves accuracy when test resolution differs from train resolution, reducing the need for multiple specialized models.
- Tools/Workflows: Single backbone serving multiple camera streams; dynamic-resolution inference policies; automatic resizing.
- Assumptions/Dependencies: Proper calibration for each input stream; validation on target cameras; inference budget headroom for higher resolutions.
- Industry — Robotics and automation perception (robotics, manufacturing, logistics)
- Action: Fine-tune ViT-5 on detection/segmentation datasets (COCO, ADE-like) to exploit cleaner attention and stronger spatial reasoning for grasping, part localization, bin-picking, and scene understanding.
- Tools/Workflows: Integrate with ROS perception stacks; deploy via TensorRT on edge GPUs; use register tokens to stabilize attention in cluttered scenes.
- Assumptions/Dependencies: Domain data; real-time constraints; hardware kernels for RMSNorm.
- Healthcare — Pilot studies in medical imaging (segmentation/classification)
- Action: Evaluate ViT-5 as a backbone for organ/tumor segmentation and detection (U-Net-like heads with ViT-5 backbone) to benefit from stability and spatial modeling improvements.
- Tools/Workflows: Fine-tune on curated, labeled datasets; calibrate 2D RoPE+APE for medical image grids.
- Assumptions/Dependencies: Regulatory approval pathways; robust clinical validation; adherence to privacy and bias audits.
- Document AI and UI understanding (finance, enterprise software, accessibility)
- Action: Use ViT-5 in layout analysis, form understanding, and UI parsing pipelines; registers and QK-Norm can reduce attention artifacts on dense, structured pages.
- Tools/Workflows: Replace vision backbones in LayoutLMv3-style pipelines; leverage resolution robustness for varied DPI scans.
- Assumptions/Dependencies: Availability of labeled corpora; post-processing heuristics for forms; PDF rasterization consistency.
- Edge/mobile vision enhancements (consumer devices)
- Action: Deploy ViT-5 for on-device portrait/background segmentation, AR effects, and photo enhancement, leveraging stability and resolution robustness across camera modes.
- Tools/Workflows: Quantization-aware training; fused RMSNorm kernels; export to mobile accelerators (NNAPI, Core ML).
- Assumptions/Dependencies: Efficient kernel support for bias-free QKV and RMSNorm; power/latency budgets; device-specific tuning.
- Academia — A reproducible, modern baseline for vision research
- Action: Adopt ViT-5 as a standard baseline for studies on normalization, positional encoding, attention robustness, and transfer learning; reuse openly available code.
- Tools/Workflows: Controlled ablations (LayerScale vs. post-norm; RoPE+APE; QK-Norm); unified training scripts.
- Assumptions/Dependencies: Compute access; dataset licenses; consistent seeds and recipes for fair comparisons.
- Policy — Near-term compute-efficiency and training-stability guidance
- Action: Encourage use of architectures that reduce loss spikes and retraining (QK-Norm, LayerScale, RMSNorm) in public-sector AI RFPs and green-AI guidelines, cutting wasted energy from unstable training runs.
- Tools/Workflows: Procurement checklists referencing backbone properties; energy and retrain metrics reporting.
- Assumptions/Dependencies: Measurement frameworks; vendor compliance; open reporting norms.
- Policy — Content provenance for stronger diffusion models
- Action: Strengthen watermarking/provenance requirements in platforms adopting improved diffusion models backed by ViT-5 (due to higher fidelity and potential misuse).
- Tools/Workflows: Default invisible watermarks; content authenticity standards (e.g., C2PA).
- Assumptions/Dependencies: Platform cooperation; watermark robustness; legal frameworks.
Long-Term Applications
These require additional research, scaling, validation, or ecosystem development before broad deployment.
- Industry — Unified multimodal foundation backbones (software, education, enterprise)
- Vision: Build next-gen VLMs that use ViT-5-style components across vision and language for tighter alignment and stable training at scale.
- Potential Products: ViT-5-powered CLIP 2.0/SigLIP successors; enterprise multimodal assistants with improved spatial grounding.
- Assumptions/Dependencies: Large-scale multimodal pretraining data; optimized kernels for RMSNorm/QK-Norm on large clusters; positional encoding conventions across modalities.
- Industry — Video and 3D perception transformers (media, AV, robotics, AR/VR)
- Vision: Extend 2D RoPE+APE and register tokens to spatiotemporal settings as memory/anchors for long context in video; adapt to 3D point clouds and volumetric data.
- Potential Products: Long-horizon video QA and summarization; robust AV perception backbones; AR/VR scene understanding.
- Assumptions/Dependencies: Temporal RoPE design; memory/register scaling; real-time constraints and safety validation (especially in AV/robotics).
- Industry — Privacy-preserving, on-device foundation vision models (mobile, IoT)
- Vision: Quantization/distillation of ViT-5 into small footprints while maintaining resolution robustness and stability for edge compute.
- Potential Products: Offline visual assistants, wearable vision for accessibility, smart home devices.
- Assumptions/Dependencies: High-quality quantization kernels for RMSNorm and bias-free attention; secure model update pipelines; thermal budgets.
- Industry — Autonomous systems with safety-grade perception (manufacturing, AV, drones)
- Vision: Use ViT-5’s stable training and cleaner attention to support certifiable, interpretable perception modules.
- Potential Products: Safety-certified perception stacks; monitoring tools that leverage interpretable attention maps.
- Assumptions/Dependencies: Formal verification methods; regulatory acceptance of attention-based interpretability; rigorous OOD and robustness benchmarks.
- Industry — Remote sensing and climate analytics (energy, agriculture, public sector)
- Vision: Leverage resolution robustness for multi-scale satellite and aerial imagery across sensors and orbits.
- Potential Products: Crop monitoring, infrastructure inspection, disaster assessment dashboards.
- Assumptions/Dependencies: Domain-adapted pretraining; sensor-specific calibration; handling of multi-spectral inputs.
- Academia — Scaling laws and theory for “over-gating” and registers
- Vision: Systematically study the interaction between LayerScale and gated MLPs (SwiGLU) at trillion-token scales; formalize when/why registers mitigate attention artifacts and how high-frequency RoPE on registers decouples positional correlations.
- Potential Tools: Open benchmarks for sparsity vs. capacity; diagnostic suites for attention artifacts.
- Assumptions/Dependencies: Access to large compute; community-agreed protocols; standardized metrics.
- Academia — Standardization of positional encoding in vision backbones
- Vision: Establish best practices for combined APE + 2D RoPE to avoid unwanted invariances (e.g., patch-flip invariance) while preserving scalability across resolutions.
- Potential Outputs: Community guidelines; interoperability layers for pretrained weights.
- Assumptions/Dependencies: Broad benchmarking across detection/segmentation/generation and cross-resolution transfer.
- Policy — Green AI standards emphasizing stable training backbones
- Vision: Formalize architecture-level recommendations (e.g., QK-Norm to reduce loss spikes) in sustainability guidelines and public funding criteria.
- Potential Outputs: Policy briefs; model cards requiring training-stability metrics; lifecycle emissions reporting.
- Assumptions/Dependencies: Consensus on measures of stability/efficiency; tooling for energy tracking.
- Policy — Safety and provenance in next-gen generative models
- Vision: With improved FID and realism, strengthen norms for labeling, watermarking, and detection of synthetic media, including regulation-ready benchmarks and audits.
- Potential Outputs: Certification programs; audit frameworks for content authenticity.
- Assumptions/Dependencies: Cross-platform coordination; legal harmonization; robust watermark tech.
- Daily life — AR/VR and embodied assistants with robust perception
- Vision: Use ViT-5-derived backbones for spatially coherent, low-latency perception in home robots, AR glasses, and mixed-reality apps.
- Potential Products: Household task assistants; context-aware overlays; navigation aids for low-vision users.
- Assumptions/Dependencies: Low-power hardware kernels; latency-optimized attention; user privacy safeguards.
- Daily life — Safer, higher-quality creative tools
- Vision: Future consumer apps with ViT-5-based diffusion for photorealistic editing and content creation, with built-in watermarking and safety rails.
- Potential Products: Mobile editors with realist generative fills; personalized content generation assistants.
- Assumptions/Dependencies: UX that surfaces provenance; content moderation; device compute capacity.
Cross-cutting assumptions and dependencies
- Reproducibility and licensing: Availability and licensing of the ViT-5 codebase; compatibility with existing training recipes (e.g., DeiT-III).
- Hardware/software kernels: Efficient RMSNorm/QK-Norm and bias-free attention in inference engines (TensorRT, ONNX Runtime, mobile NN accelerators).
- Data and evaluation: Access to high-quality labeled/unlabeled data; task-specific validation beyond ImageNet and ADE20K; domain adaptation for specialized sectors (medical, AV).
- Safety, ethics, and compliance: For higher-fidelity generation, robust watermarking/provenance; for regulated sectors (healthcare/AV), rigorous validation and governance.
- Migration risk: Minor retraining and positional encoding migration (APE + 2D RoPE) may be required; consider weight conversion tools and careful fine-tuning.
Glossary
- Absolute positional embeddings (APE): Learnable vectors added to token embeddings to encode their absolute positions in a sequence or grid. "Standard ViTs employ learnable absolute positional embeddings (APE), which have been shown to lack explicit relative positional modeling in complex visual reasoning tasks and to be inherently limited when handling dynamic input resolutions~\cite{qwen2vl,pixtral}."
- ADE20k: A benchmark dataset for semantic segmentation with diverse scene annotations. "We further evaluate ViT-5 on ADE20k~\cite{ade20k} for semantic segmentation using the UperNet~\cite{upernet} framework."
- AdamW: An optimizer that decouples weight decay from the gradient-based update to improve generalization. "we switch to the AdamW optimizer with a smaller learning rate and train for a short schedule."
- Class token: A special token in ViTs used to aggregate information for image-level predictions. "enabling the class token to attend more accurately to semantically meaningful regions of the image."
- Classifier-free guidance: A technique in diffusion models that improves sample fidelity by guiding generation without an explicit classifier. "We train the models for 7M steps with classifier-free guidance set to 1.5."
- Cosine learning rate schedule: A training schedule where the learning rate follows a cosine decay, often improving convergence. "using the LAMB optimizer~\cite{lamb} with a large batch size and cosine learning rate schedule."
- CutMix: A data augmentation method that mixes patches between images and adjusts labels accordingly. "including random resized cropping, horizontal flipping, Mixup, and CutMix, while disabling label smoothing and dropout."
- Diffusion Transformer (DiT): A diffusion-based generative model architecture that uses Transformers as the backbone. "We evaluate the transferability of ViT-5 by training it as the backbone of a Diffusion Transformer~\cite{dit} for image generation."
- FID (Fréchet Inception Distance): A metric for evaluating the quality of generated images by comparing feature distributions. "it achieves 1.84 FID versus 2.06 with a vanilla ViT backbone."
- GeLU: Gaussian Error Linear Unit, a smooth nonlinearity commonly used in Transformer MLPs. "modern LLMs have widely utilized gated MLP architectures, in which the traditional GeLU activation is replaced by SwiGLU (Swish-Gated Linear Unit)~\cite{swiglu}."
- ImageNet-1k: A large-scale image classification benchmark with 1,000 classes. "On ImageNet-1k classification, ViT-5-Base reaches 84.2\% top-1 accuracy under comparable compute, exceeding DeiT-III-Base at 83.8\%."
- LAMB optimizer: A large-batch training optimizer that scales layer-wise updates to stabilize training. "models are trained from scratch using the LAMB optimizer~\cite{lamb} with a large batch size and cosine learning rate schedule."
- Layer Normalization (LayerNorm): A normalization technique applied across feature dimensions of a token to stabilize training. "the de facto standard in LLM architectures has largely shifted from Layer Normalization (LayerNorm) to Root Mean Square Normalization (RMSNorm)."
- LayerScale: A learnable per-channel scaling of residual block outputs that stabilizes deep Transformer training. "This mechanism is commonly referred to as LayerScale and has been used as a default component in many modern ViT architectures such as DINO v3~\cite{dinov3}."
- Mixup: A data augmentation technique that linearly mixes pairs of training examples and labels. "including random resized cropping, horizontal flipping, Mixup, and CutMix, while disabling label smoothing and dropout."
- Patchification: The process of splitting an image into non-overlapping patches and projecting them into token embeddings for ViTs. "we do not focus on improving the patchification layer, and instead employ the standard non-overlapping patch embedding with linear projection."
- Post-normalization (post-RMSNorm): Applying normalization after the residual addition in a Transformer block, often improving stability in deep models. "Formally, post-RMSNorm can be rewritten as"
- QK-Normalization (QK-Norm): Normalizing query and key vectors in self-attention (e.g., with RMSNorm) to improve stability and robustness. "Formally, this QK-Normalization mechanism has"
- QKV projection: The linear projections that produce query (Q), key (K), and value (V) vectors for self-attention. "we remove bias terms in the QKV projection layers"
- Register tokens (Registers): Additional learnable tokens appended to the token sequence to stabilize attention and suppress artifacts. "register tokens should also be assigned relative positional embeddings."
- Relative positional encoding: Encoding positions relative to each other to inform attention of spatial relationships, improving generalization across resolutions. "using relative positional encoding alone can introduce undesirable invariances."
- RMSNorm (Root Mean Square Normalization): A normalization method that rescales activations by their root mean square, omitting mean-centering. "the de facto standard in LLM architectures has largely shifted from Layer Normalization (LayerNorm) to Root Mean Square Normalization (RMSNorm)."
- RoPE (Rotary Positional Embeddings): A positional encoding mechanism that injects relative position information via complex rotations in feature space. "we extend rotary positional embeddings (RoPE) to the 2D setting and incorporate them into our models."
- Self-attention: A mechanism where tokens attend to each other to compute contextualized representations. "The latest LLMs such as Qwen3~\cite{qwen3} and Gemma3~\cite{gemma3} have begun to reform self-attention by applying additional normalization to the query and key."
- Semantic segmentation: The task of assigning a class label to every pixel in an image. "We further evaluate ViT-5 on ADE20k~\cite{ade20k} for semantic segmentation using the UperNet~\cite{upernet} framework."
- Stochastic depth: A regularization technique that randomly drops entire layers or residual paths during training to improve generalization. "Stochastic depth is applied with scale-dependent rates, and gradient clipping is enabled for training stability."
- SwiGLU (Swish-Gated Linear Unit): A gated MLP activation that multiplies a Swish-activated gate with a linear transform, widely used in modern LLMs. "modern LLMs have widely utilized gated MLP architectures, in which the traditional GeLU activation is replaced by SwiGLU (Swish-Gated Linear Unit)~\cite{swiglu}."
- UperNet: A widely used semantic segmentation head architecture that aggregates multi-scale features. "for semantic segmentation using the UperNet~\cite{upernet} framework."
- Vision Transformer (ViT): A Transformer architecture adapted to images by operating on patch tokens instead of sequence tokens. "Since its introduction at the end of 2020, the Vision Transformer~\cite{vit} (ViT) has substantially reshaped visual encoding paradigms."
Collections
Sign up for free to add this paper to one or more collections.