- The paper introduces a multimodal framework that uses visual instruction tuning on 3D CT scans and radiology reports for enhanced survival prediction.
- It employs a joint training strategy combining clinical data with imaging features to improve risk stratification over traditional survival models.
- The approach demonstrates superior c-index performance and generates structured clinical explanations for increased transparency in predictions.
Medical Image Understanding Improves Survival Prediction via Visual Instruction Tuning
Introduction
The integration of multimodal medical data, specifically 3D CT imaging and clinical information, has become an essential area of research for survival analysis in various disease contexts. Prognostic modeling in this domain not only drives personalized clinical decisions but also enhances our understanding of risk stratification and treatment planning. The paper introduces a vision–language framework leveraging large-scale, open-sourced 3D CT images paired with radiology reports, utilizing visual instruction tuning to induce clinically meaningful latent representations. This approach enables improved survival prediction and simultaneously generates structured clinical natural language responses.
Methodology
The framework is composed of a 3D CT vision–LLM coupled with a survival prediction head. Visual tokens are derived from the Merlin image encoder and mapped to the language embedding space using a trainable projection, thereby facilitating joint representation learning. The language decoder is based on Radllama, which is pre-trained on medical corpora, ensuring domain specificity.
Pre-training is conducted using visual instruction tuning over 282,894 image-text pairs from the CT-RATE dataset. Radiology reports are decomposed into structured question-answer pairs through a semi-automated process involving high-frequency medical word extraction followed by prompt-based question generation. Fine-tuning attaches a survival prediction head atop the instruction-tuned backbone—either DeepSurv for continuous-time survival or DeepHit for discrete event prediction. Complementary losses, including a modality alignment loss and a dispersion loss, are used to reinforce risk-relevant latent space structure and to regularize the alignment of linguistic and survival representations.
The pipeline for joint training integrates both clinical/tabular context and 3D image data, enabling simultaneous backpropagation through the visual-language and survival heads. During inference, predefined clinical questions are applied uniformly to all patients, averaging risk predictions over multiple queries for ensemble robustness.
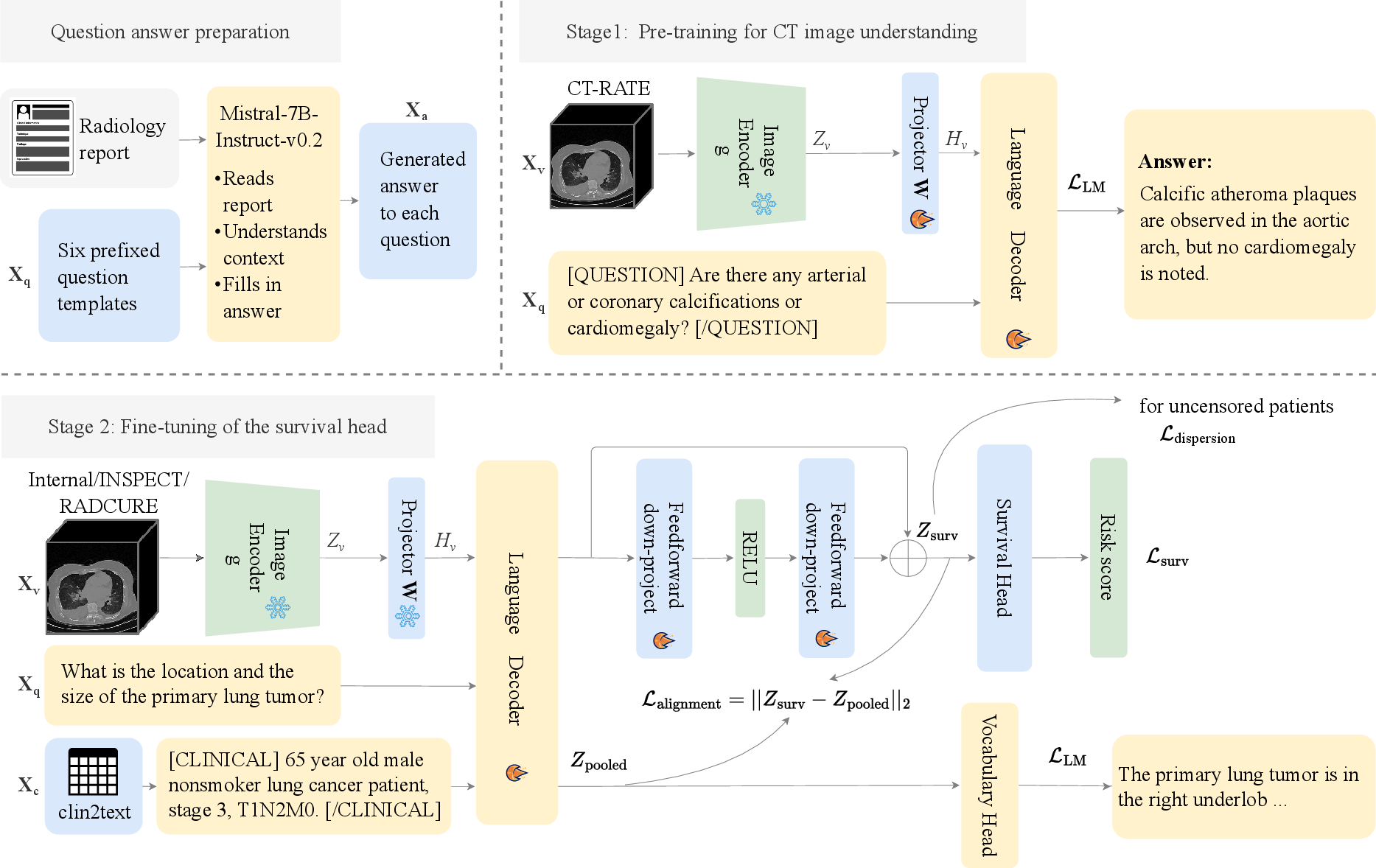
Figure 1: Overview of joint training for visual instruction finetuning and survival head adaptation within the proposed framework.
Visual QA Construction and Clinical Relevance
Automated VQA corpus construction is achieved by extracting high-yield medical tokens from free-text radiology reports, which are then used to scaffold canonical clinical questions (e.g., tumor size, lymph node involvement, presence of metastasis). These templates are validated by clinical experts and paired with report-derived answers, filtered and reviewed, to ensure clinical fidelity. This process produces high-quality language supervision for effective vision-language pre-training.
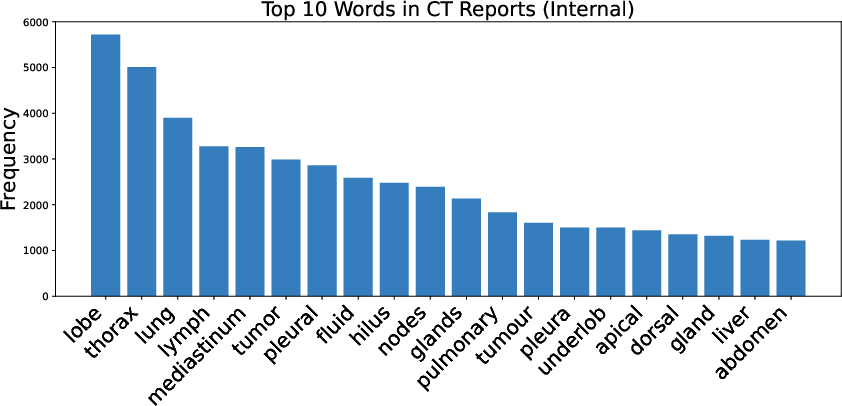
Figure 2: Distribution of top-10 medical word frequencies in the internal dataset and examples of predefined radiology question templates.
Experimental Evaluation
The experimental setup utilizes CT-RATE for pre-training, and evaluates survival prediction and generation quality on the INSPECT and an internal lung cancer dataset. Performance is compared against classic statistical (CoxPH) and established deep learning survival models (DeepSurv, DeepHit) with unimodal and multimodal input regimes.
Quantitative analyses indicate that the proposed joint training strategy yields improved concordance index (c-index) on the INSPECT dataset, relevant in cases where imaging features provide substantial prognostic signal beyond clinical data. BERTScore is used to assess the factual quality of generated language answers, demonstrating that the model generates high-fidelity clinical-language outputs aligned with ground-truth radiology reports.
On the internal lung cancer cohort, gains in c-index are modest due to the high predictive power of structured TNM staging and related clinical variables. In contrast, for pulmonary embolism in INSPECT, where imaging cues are paramount, the joint vision-language training with pre-training on CT-RATE substantially boosts performance, confirming the value of instruction-tuned representation transfer.
Kaplan–Meier curve analyses illustrate the improved separation of risk strata between high and low-risk groups, with substantial improvements observed post vision-language pre-training on CT-RATE.
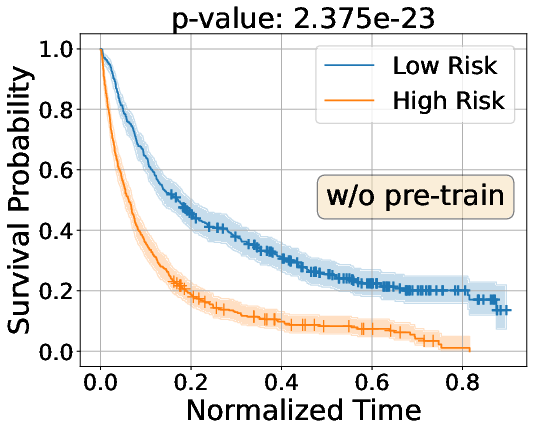
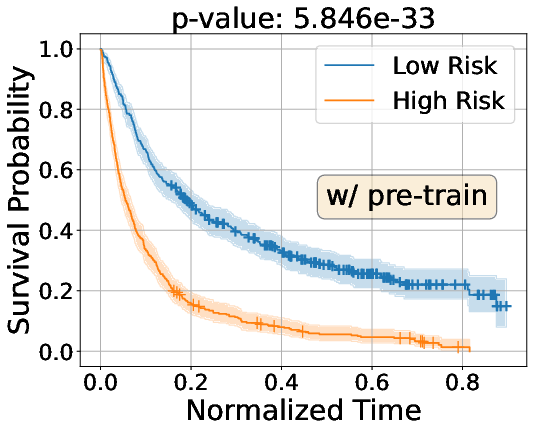
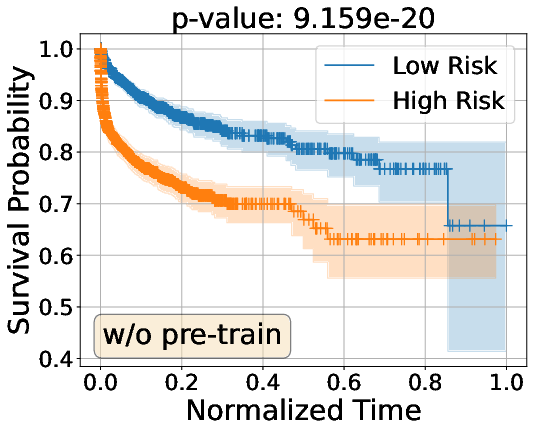
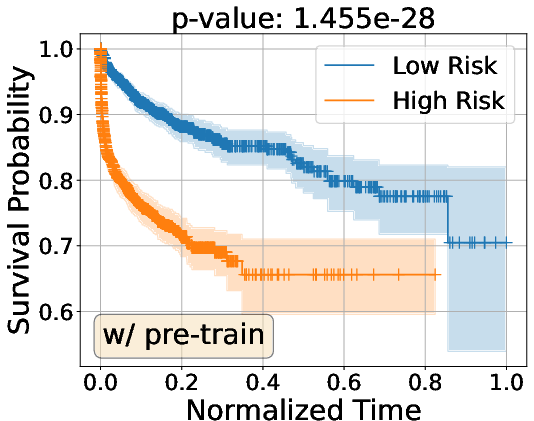
Figure 3: Kaplan–Meier survival analysis on Internal and INSPECT cohorts, demonstrating enhanced group separation with vision-language pre-training.
Implications and Future Perspectives
These results underscore the advantage of pre-training vision-LLMs on large-scale clinically aligned VQA datasets, accelerating transfer for downstream survival tasks in settings where clinical tabular data is less predictive. The model’s ability to output structured, clinically actionable language-based explanations for risk predictions addresses transparency and trustworthiness requirements for real-world deployment.
From a theoretical standpoint, the success of visual instruction tuning corroborates the hypothesis that joint multimodal latent representations—aligned by clinically validated VQA supervision—can outperform more naively fused or modality-isolated architectures, especially in censored, high-dimensional clinical prediction domains. The addition of regularization terms to maximize dispersion among latent representations with divergent survival times further addresses key limitations of feature collapse, a common failure mode in medical survival analysis.
Practical implications include improved decision support for less well-structured or rare disease cohorts, and the framework’s modular nature facilitates extension to other imaging modalities and clinical conditions. An immediate extension is fine-tuning on additional question-answer templates reflecting non-radiologic risk factors. Future research may address scaling the approach to even broader federated datasets, integrating additional omics or EHR modalities, or leveraging advances in foundation models for more data-efficient generalization.
Conclusion
The presented research demonstrates that large-scale vision–language pre-training with clinically meaningful visual instruction tuning substantially improves downstream survival prediction and enables explainable response generation from medical imaging and clinical data. The framework achieves strong predictive and generative results, particularly in tasks where imaging signals are prognostically dominant, highlighting the pivotal role of joint multimodal representation learning for medical AI applications.