Hybrid Reinforcement: When Reward Is Sparse, It's Better to Be Dense
Abstract: Post-training for reasoning of LLMs increasingly relies on verifiable rewards: deterministic checkers that provide 0-1 correctness signals. While reliable, such binary feedback is brittle--many tasks admit partially correct or alternative answers that verifiers under-credit, and the resulting all-or-nothing supervision limits learning. Reward models offer richer, continuous feedback, which can serve as a complementary supervisory signal to verifiers. We introduce HERO (Hybrid Ensemble Reward Optimization), a reinforcement learning framework that integrates verifier signals with reward-model scores in a structured way. HERO employs stratified normalization to bound reward-model scores within verifier-defined groups, preserving correctness while refining quality distinctions, and variance-aware weighting to emphasize challenging prompts where dense signals matter most. Across diverse mathematical reasoning benchmarks, HERO consistently outperforms RM-only and verifier-only baselines, with strong gains on both verifiable and hard-to-verify tasks. Our results show that hybrid reward design retains the stability of verifiers while leveraging the nuance of reward models to advance reasoning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI LLMs to “reason” better, especially on math problems. The authors show that using only pass/fail feedback (did the answer match exactly or not) is too strict, while using only fuzzy scoring (how good does the answer seem) can be unreliable. They introduce HERO, a training method that smartly combines both kinds of feedback so models learn more reliably and improve on both easy-to-check and hard-to-check problems.
What questions did the researchers ask?
- Can we keep the reliability of strict, verifiable checks (pass/fail) but still give the model richer guidance like partial credit?
- How can we safely mix these two feedback styles so training doesn’t become unstable or misleading?
- Will this hybrid approach help models do better on math tasks where exact checking works, and also on tasks where checking is hard (e.g., flexible formats, long reasoning steps)?
How did they do it?
Think of grading math homework:
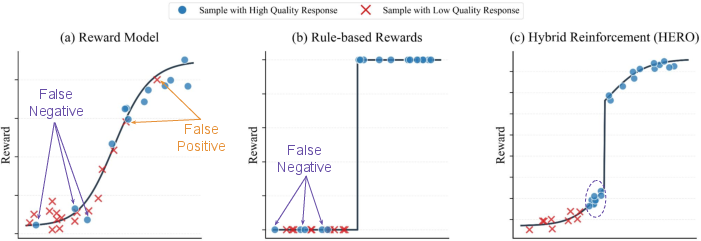
- A rule-based “verifier” is like a super strict grader who gives only pass (1) or fail (0). It rarely says a wrong answer is right, but it often gives zero to answers that are mostly correct but formatted differently.
- A reward model is like a human teacher who gives partial credit (a score on a scale), but sometimes this teacher can be fooled and give high scores to flawed answers.
HERO combines both:
Two types of feedback
- Sparse (pass/fail) feedback: A checker says 1 if the final answer matches the ground truth (after smart normalization), otherwise 0. This is reliable but coarse and often “brittle.”
- Dense (continuous) feedback: A reward model gives a smooth score that can recognize “almost correct,” but can sometimes be misaligned.
HERO’s two core ideas
- Stratified normalization (anchored partial credit)
- First, group the model’s answers by the strict checker: “correct group” (pass) and “incorrect group” (fail).
- Then, within each group, rescale the reward-model scores to a safe, limited range.
- Translation: the pass/fail gate decides the big bucket. Inside each bucket, partial credit ranks answers from better to worse, without letting fuzzy scores overrule correctness.
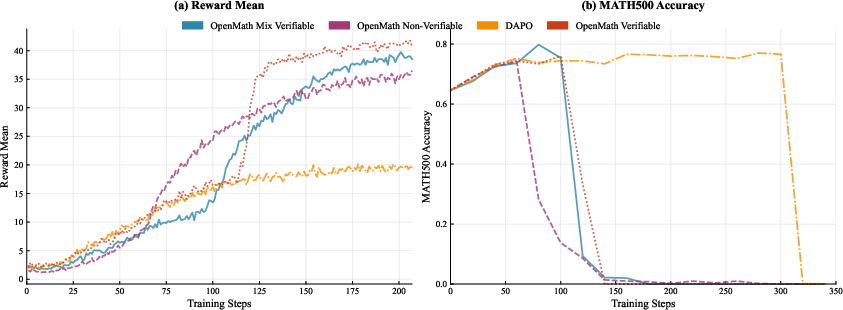
- Why this helps: If every answer in a batch is marked the same by the strict checker (all pass or all fail), normal pass/fail gives no learning signal. HERO still gives meaningful differences inside the bucket, so the model keeps learning.
- Variance-aware weighting (focus where it matters)
- Some questions are too easy (all answers similar), so they don’t teach much.
- Other questions are hard (answers vary a lot), which means they’re more informative.
- HERO measures how spread-out the scores are for each question. If there’s lots of variation (high uncertainty), it boosts that question’s importance during training. If there’s little variation, it tones it down.
- Translation: spend more study time on the confusing questions and less on the obvious ones.
They train with a group-based RL method (like comparing multiple answers per question) so the model learns which answers are relatively better, not just whether they pass or fail.
What did they find?
Across several math benchmarks and different base models:
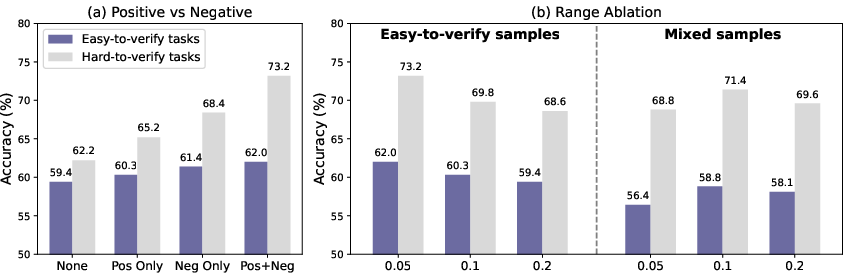
- HERO beat “verifier-only” (strict pass/fail) and “reward-model-only” (fuzzy scoring) methods.
- Gains were solid on easy-to-verify math (where exact checking works) and even bigger on hard-to-verify math (where formatting or long reasoning can trick strict checkers).
- Example highlight (Qwen-4B-Base, hard-to-verify evaluation): HERO reached about 66, while reward-model-only was ~55 and verifier-only was ~57. That’s a clear improvement.
- The hybrid design was stable: anchoring dense scores to the pass/fail groups kept training from drifting off-course.
- Focusing on difficult prompts (variance-aware weighting) gave extra boosts, especially on hard tasks.
- They also found that giving nuanced feedback to “wrong” answers (dense negative signals) was especially important—penalizing errors in a detailed way helped the model learn faster and smarter.
- A bigger reward model (72B) didn’t help much compared to a smaller one (7B) when using HERO. The combination method mattered more than the size.
Why does it matter?
- Better reasoning: Models learn not just to match exact final answers, but to improve their step-by-step thinking, even when answers are partially correct or formatted differently.
- More robust training: HERO keeps the safety and clarity of strict checks while adding the nuance of partial credit. This reduces brittleness and makes learning more sample-efficient.
- Practical impact: Many real tasks aren’t perfectly “verifiable.” HERO’s hybrid approach can help AI do better on open-ended math, proofs, or tasks where “almost right” needs to be recognized and refined.
- Efficiency: You don’t need a giant reward model to see benefits—good design in combining signals goes a long way.
In short, when pass/fail feedback is too sparse, it’s better to add dense, well-controlled guidance. HERO shows how to do that safely and effectively, leading to stronger reasoning in AI.
Knowledge Gaps
Below is a concise list of the paper’s unresolved gaps, limitations, and open questions that future work could address:
- Domain scope: Results are limited to mathematical reasoning; generalization to code generation (unit tests), scientific QA, tool-using agents, proofs, and multimodal reasoning remains untested.
- Verifier diversity: HERO is evaluated with a single primary rule-based verifier (math_verify/VERL); robustness to alternative verifiers, ensembles of verifiers, or probabilistic/soft verifiers is unexplored.
- Gating on imperfect verifiers: False negatives from rule-based verifiers are still placed in the “incorrect” group; no mechanism adapts the gate when the verifier is uncertain or likely wrong (e.g., soft gates, verifier confidence).
- Theoretical guarantees: No analysis of conditions on α, β ensuring non-overlapping reward ranges across groups (e.g., require α < 1 − β); lack of proofs for stability, advantage ordering, or convergence under stratified normalization.
- Hyperparameter sensitivity: Limited ablation on α (negative range) and little/no coverage of β, ε, KL strength, k, w_min, w_max, or group size; robust tuning guidelines and sensitivity curves are missing.
- Choice and calibration of reward model (RM): Results rely on AceMath RMs; transfer to different RMs, calibration quality on hard-to-verify data, and bias to RM training distribution are not characterized (e.g., ECE/AUROC/PR per subtask).
- Distribution shift and stale RM: The RM is fixed while the policy shifts; no study of online RM updates, co-training, or regularization to mitigate RM-policy distribution drift.
- Difficulty estimator reliability: Variance-aware weighting uses per-prompt RM variance only; alternative or complementary estimators (e.g., entropy of the policy, verifier disagreement, outcome variance across seeds) are not compared.
- Reward hacking within groups: Potential for gaming RM scores with stylistic artifacts or verbosity to win intra-group rankings is not stress-tested; adversarial evaluations and defenses are absent.
- Interaction with KL and exploration: Effects of KL penalty strength, decoding temperature, and number of rollouts per prompt (N) on stability, exploration, and performance are not analyzed.
- Data efficiency and compute: No reporting of tokens, wall-clock, GPU budget, or sample efficiency; scaling laws vs. data/model size and cost-performance trade-offs are missing.
- Mixed-regime curriculum: Only a 1k/1k mix is tested; optimal mixing ratios, curriculum schedules (easy→hard), and dynamic rebalancing are unstudied.
- Process-level rewards: HERO optimizes outcome-level rewards; integration of process/step-level verifiers or rubric-based partial credit with stratified normalization remains open.
- Ensemble hybridization: Combining multiple verifiers and multiple RMs (and their aggregation/calibration) to increase robustness is not evaluated.
- Evaluation reliability on hard-to-verify: Heavy reliance on GPT-4o as judge lacks calibration checks, inter-judge agreement, multi-judge adjudication, or open-source judge replication.
- Baseline breadth: Missing head-to-head comparisons with strong contemporary alternatives (e.g., DAPO, VeriFree, rubric-anchored RL, step-level RL, RLAIF) under identical compute and data budgets.
- Failure mode taxonomy: No qualitative analysis of where HERO helps or fails (e.g., formatting issues, algebraic equivalence, multi-step logic, extraneous reasoning).
- Exploration vs. penalization: Dense negative rewards help, but the impact on exploration, output diversity, length/verbosity, and premature pruning of promising but imperfect trajectories is unmeasured.
- Long-horizon and compositional tasks: Performance on very long chains-of-thought, proofs, or multi-tool compositions (where sparse rewards are more severe) is unknown.
- Robustness across scales/backbones: Only Qwen3-4B and OctoThinker-8B are tested; interactions with larger/stronger instruction-tuned models and scaling behavior remain unclear.
- RM size vs. quality: The 72B RM offers minimal gains; principled criteria for choosing RM capacity, training data, and calibration methods (e.g., isotonic/temperature scaling) are not provided.
- Metric protocol consistency: For verifiable sets, generating N=8 but reporting pass@1 on the first sample is unusual; effects of best-of-k or majority voting vs. single-sample reporting are not disentangled.
- Reproducibility details: Filtering for “hard-to-verify” training data, verifier post-processing, and exact HERO hyperparameters are deferred to appendices and contain typos in equations; clearer, executable recipes and code are needed.
Practical Applications
Immediate Applications
Below is a concise set of practical applications that can be deployed now, derived from the paper’s HERO framework (hybrid reward integration via stratified normalization and variance-aware weighting). Each item notes sectors, potential tools/workflows, and feasibility assumptions.
- Bold: Sector-cross LLM training plugin for reasoning tasks
- Sectors: software, education, finance, data/analytics
- What: Integrate HERO into existing RLHF/RLAIF pipelines to fine-tune LLMs on math, code, text-to-SQL, and analytic tasks where final answers can be verified but reasoning is diverse.
- Tools/products/workflows: “Hybrid Reward Trainer” module built atop GRPO; stratified normalization layer that gates reward-model scores by verifier outputs; variance-aware prompt sampler; plug-in support for VERL math_verify, unit-test checkers for code, and execution-guided SQL verifiers.
- Assumptions/dependencies: Availability of deterministic verifiers per domain; a reward model (e.g., AceMath-RM-7B) with acceptable generalization; compute to sample multiple candidate responses per prompt (grouped rollouts); careful hyperparameter tuning for α/β/ε and difficulty weights.
- Bold: Math tutoring and assessment with partial credit
- Sectors: education
- What: Use verifiers to ensure correctness of final answers while HERO’s intra-group dense signals enable partial credit and graded feedback on near-correct reasoning steps; improves pass@1 and robustness on hard-to-verify formats (e.g., equivalent expressions, flexible formatting).
- Tools/products/workflows: Tutor engines that score both correctness (rule-based) and quality (RM); step-wise feedback; dashboards showing difficulty-weighted practice; automated grading aligned to curriculum.
- Assumptions/dependencies: High-quality math verifiers (symbolic equivalence, numeric normalization); calibrated RM for math reasoning; policies and rubrics that accept partial credit; reliable LLM inference for multiple solution candidates.
- Bold: Code generation CI with hybrid rewards
- Sectors: software engineering
- What: Train code assistants using unit tests and static analyzers as verifiers, combined with an RM scoring code style, readability, and performance; HERO preserves correctness while encouraging higher-quality code.
- Tools/products/workflows: RL fine-tuning with test suites (verifiers) + code-quality RMs; pipeline hooks in CI (run tests, collect RM signals, apply stratified normalization, update policy); variance-aware upweighting of failure-prone modules.
- Assumptions/dependencies: Comprehensive test coverage; domain-specific RMs (style/perf) that don’t reward unsafe patterns; adequate CI resources for multi-sample generation; safeguards against reward hacking.
- Bold: Text-to-SQL and analytics assistants with execution-guided reward
- Sectors: data/analytics, finance, enterprise BI
- What: Use query execution as the verifier (correctness, constraints, latency) with RM scoring clarity, schema adherence, and business-rule alignment; HERO improves reliability on both simple and complex queries.
- Tools/products/workflows: Execution-guided verifiers; schema-aware RM; logging to compute variance and adapt sampling; dashboards for difficulty-weighted evaluation and iterative retraining.
- Assumptions/dependencies: Safe sandboxed databases; clear business constraints (verifier rules); RM trained on enterprise schemas; privacy controls.
- Bold: Evaluation workflows for hard-to-verify outputs
- Sectors: academia, industry benchmarking
- What: Combine strict verifiers (where available) with bounded RM signals to reduce false negatives and provide partial credit; improves assessment on open-ended reasoning (e.g., Olympiad questions, proofs).
- Tools/products/workflows: Hybrid scoring harnesses that first gate with verifiers, then normalize RM scores within groups; variance-aware sample selection to focus on ambiguous prompts; optional LLM-as-judge fallback clearly marked as non-authoritative.
- Assumptions/dependencies: Verifier coverage varies by task; RM calibration; LLM-as-judge known limitations and bias; need human review for contested cases.
- Bold: Dataset curation and training efficiency via variance-aware weighting
- Sectors: ML Ops, research
- What: Prioritize prompts with high RM score variance to focus on informative, challenging samples; downweight trivial prompts to avoid wasted compute.
- Tools/products/workflows: Difficulty scorer that tracks per-prompt variance; curriculum scheduler; logging/telemetry for prompt distributions and learning progress.
- Assumptions/dependencies: Stable estimation of per-prompt variance; appropriate bounds to avoid overfitting to hard cases; monitoring to detect drift.
- Bold: Finance calculators and audit-friendly assistants
- Sectors: finance, compliance
- What: Use rule-based verifiers for numeric outcomes (constraints, bounds, unit checks) with RM for explanation quality and formatting; HERO reduces brittle failures from strict formats while preserving correctness guarantees.
- Tools/products/workflows: Verification libraries for financial calculations; RM that scores clarity and completeness of rationales; audit logs recording verifier decisions and normalized RM contributions.
- Assumptions/dependencies: Clear financial rules encoded as verifiers; domain RMs that avoid incentivizing misleading narratives; governance over judge models; PII controls.
- Bold: Knowledge-base QA with hybrid scoring
- Sectors: enterprise support, customer service
- What: For questions with structured correct answers (IDs, SKUs, dates), use verifiers to check exact fields and RM to reward response organization and helpfulness; HERO reduces false zero scores due to formatting mismatches.
- Tools/products/workflows: Answer normalization/verifiers; RMs trained on domain-specific QA preferences; workflow to sample multiple candidate answers and select via hybrid scoring.
- Assumptions/dependencies: High-quality normalization; consistent KB schemas; preference data for RM; careful prompt design to elicit structured outputs.
Long-Term Applications
Below are forward-looking applications that may require further research, scaling, domain adaptation, or standardization before deployment.
- Bold: Process-level reward shaping for complex reasoning chains
- Sectors: software, education, scientific computing
- What: Extend HERO from outcome rewards to step-wise process rewards (proof steps, code refactoring phases, data transformation pipelines), using verifiers at intermediate milestones and RM for coherence and efficiency.
- Tools/products/workflows: Step verifiers (proof checkers, unit tests per stage); multi-stage stratified normalization; dynamic curriculum that weights steps by variance and error exposure.
- Assumptions/dependencies: Availability of reliable step verifiers; fine-grained preference data for RM; prevention of shortcut exploitation.
- Bold: Robotics and embodied AI planning with hybrid rewards
- Sectors: robotics, automation, logistics
- What: Combine strict task success verifiers (e.g., “object placed in bin”) with dense RM signals for trajectory smoothness, safety margins, and human-preference compliance to improve plan robustness.
- Tools/products/workflows: Simulator-based verifiers; safety RMs; stratified normalization guarding against rewarding unsafe but “efficient” behavior; variance-aware task sampling to prioritize ambiguous scenes.
- Assumptions/dependencies: High-fidelity simulators and sensors; safe reward-modeling for safety-critical domains; rigorous validation and certification pipelines.
- Bold: Clinical decision support with verifier-anchored nuance
- Sectors: healthcare
- What: Ground recommendations in guideline verifiers (drug–drug interactions, contraindications) while using RM for documentation quality, rationale completeness, and patient-friendly explanations.
- Tools/products/workflows: Medical rule engines as verifiers; domain RMs; audit trails of hybrid scoring; human-in-the-loop review; bias and safety monitoring.
- Assumptions/dependencies: Regulatory approvals; trustworthy domain RMs; robust verification coverage; strict guardrails to prevent unsafe reward hacking; extensive clinical validation.
- Bold: Scientific discovery and formal theorem proving
- Sectors: academia, R&D
- What: Use proof checkers/verifiers to anchor correctness while RM rewards guide search over partial proofs, lemmas, and explanatory clarity; HERO could improve sample efficiency in hard proof spaces.
- Tools/products/workflows: Lean/Coq/Isabelle verifiers; RM for proof readability and structure; variance-aware search prioritization.
- Assumptions/dependencies: Strong integration with formal systems; high-quality training corpora; mechanisms to avoid spurious high RM scores for invalid proofs.
- Bold: Multimodal hybrid rewards (vision–text–math)
- Sectors: education, engineering, geospatial, manufacturing
- What: Extend HERO to tasks where visual verifiers (e.g., diagram correctness, CAD constraints) anchor the outcome, while RM captures descriptive accuracy and reasoning coherence across modalities.
- Tools/products/workflows: Multimodal verifiers (constraint checkers, OCR/equivalence checkers); multimodal RMs; stratified normalization adapted for cross-modal score scales.
- Assumptions/dependencies: Robust multimodal verifiers; availability of multimodal preference data; unified normalization strategies.
- Bold: Standards and policy for AI evaluation with hybrid rewards
- Sectors: policy, governance, compliance
- What: Develop guidelines that require verifier-anchored hybrid reward designs for high-stakes deployments; define audit requirements (logs of gating, normalization ranges, difficulty weights); reduce reliance on unconstrained LLM-as-judge.
- Tools/products/workflows: Compliance frameworks; conformance tests; reference implementations of hybrid reward auditing; bias testing for RM/judge models.
- Assumptions/dependencies: Consensus among standards bodies; measurable governance metrics; sector-specific verifiers; transparency mandates.
- Bold: Auto-curriculum and dataset governance based on prompt variance
- Sectors: ML platforms, EdTech
- What: Use variance-aware weighting to continuously curate and balance training datasets, focusing learning on informative samples while controlling drift and overfitting.
- Tools/products/workflows: Data governance services that monitor RM variance, prompt difficulty, and coverage; automated resampling policies; quality dashboards.
- Assumptions/dependencies: Reliable difficulty estimation; guardrails to prevent curriculum collapse to edge cases; infrastructure for continuous re-training.
- Bold: Public-sector math/logic proficiency tools and equitable assessment
- Sectors: public education policy
- What: Deploy hybrid-verifier grading engines that assign partial credit fairly across diverse formats (e.g., typed responses, handwritten recognition after OCR), reducing under-crediting due to formatting.
- Tools/products/workflows: Standardized verifier banks; calibrated RM tied to curricular rubrics; accessibility enhancements; teacher-facing analytics.
- Assumptions/dependencies: Procurement and standards alignment; fairness auditing of RM; stakeholder buy-in to partial-credit policies; privacy and data protections.
Notes on Feasibility and Risk
- Verifier coverage is the linchpin: HERO’s benefits depend on having reliable, domain-specific deterministic checkers to gate correctness and prevent reward drift.
- Reward-model quality and calibration matter: Poorly aligned RMs can mis-score incorrect outputs; stratified normalization mitigates but does not eliminate this risk.
- Compute and sampling costs: GRPO-style group rollouts improve stability but require more inference; budget and latency constraints must be considered.
- LLM-as-judge use in hard-to-verify settings remains a dependency with known bias/variance; use for evaluation rather than training where possible, and audit decisions.
- Hyperparameters (α, β, ε; weighting bounds and slope k) impact stability/performance trade-offs; careful tuning is necessary, with smaller ranges favoring verifiable tasks and larger ranges aiding mixed regimes.
- Safety-critical domains (healthcare, robotics, finance) require additional guardrails, human oversight, and regulatory compliance before production deployment.
Glossary
- Ablation: An experimental analysis that removes or modifies components to assess their contribution to performance. "Ablations further confirm that anchoring dense signals to verifiable correctness and adaptively reweighting difficult prompts are both critical for stability and efficiency."
- AceMath-7B-RM: A math-focused reward model used to score response quality in mathematical reasoning tasks. "a math-focused reward model (AceMath-7B-RM)"
- Bradley–Terry model: A probabilistic model for pairwise comparisons used to train reward models on preference data. "Based on the Bradley–Terry model"
- Chain-of-thought: A reasoning style where models generate intermediate steps before final answers. "specifically trained for chain-of-thought answer verification."
- Evidence lower bound (ELBO): A variational objective that lower-bounds the log-likelihood, often used when treating latent variables. "uses Jensen's evidence lower bound"
- Generative model-based verifier: An LLM used to judge or verify responses instead of rule-based checks. "we include a generative model-based verifier (TIGER-Lab/general-verifier"
- GRPO (Group Relative Policy Optimization): An RL method that compares groups of responses per prompt to compute relative advantages and stabilize learning. "GRPO extends RLVR by optimizing over multiple responses per prompt rather than treating them independently."
- HardVerify_Math: A benchmark of hard-to-verify math problems designed to stress verification methods. "HardVerify_Math benchmark"
- HERO (Hybrid Ensemble Reward Optimization): The proposed RL framework that combines verifier-based and reward-model signals via stratified normalization and variance-aware weighting. "We introduce HERO (Hybrid Ensemble Reward Optimization)"
- KL penalty (Kullback–Leibler penalty): A regularization term that penalizes divergence from a reference policy to prevent unstable updates. "adds a KL penalty"
- LLM-as-a-judge: An evaluation protocol where a LLM assesses the correctness or quality of outputs. "we adopt an LLM-as-a-judge protocol."
- Min–max normalization: A scaling technique that maps values to a bounded range using their minimum and maximum within a group. "apply min–max normalization within each group"
- Pass@1: An evaluation metric indicating whether the first generated solution solves the problem. "We report pass@1 averaged over 8 seeds"
- PPO (Proximal Policy Optimization): A policy-gradient RL algorithm with clipping to ensure stable updates. "as in PPO"
- RLVR (Reinforcement Learning from/with Verifiable Rewards): An RL paradigm that uses deterministic correctness checks (0/1) as rewards. "Reinforcement learning with verifiable rewards (RLVR) leverages a deterministic function"
- Reward modeling: Learning a scalar scoring function from preference data to guide RL toward preferred outputs. "Reward modeling learns a scalar function r(x, y)"
- Rollout: A sampled trajectory or generated response from a policy used for training or evaluation. "for a group of N rollouts."
- Rubric-anchored RL: An RL approach that uses structured rubrics to grade open-ended responses instead of strict binary checks. "rubric-anchored RL which introduces structured rubrics for open-ended response evaluation"
- Rule-based verifier: A deterministic checker that applies predefined rules (e.g., exact match, unit tests) to label outputs as correct/incorrect. "rule-based verifiers that provide sparse but precise correctness signals"
- SFT (Supervised Fine-Tuning): Fine-tuning a model on labeled input–output pairs to stabilize or initialize subsequent RL. "we first perform supervised fine-tuning (SFT) on each base model"
- Stratified normalization: A procedure that rescales reward-model scores within verifier-defined groups (correct vs. incorrect) to preserve correctness semantics. "it introduces a stratified normalization scheme"
- Symbolic equivalence check: A verification method that tests whether two expressions are mathematically equivalent via symbolic manipulation. "a symbolic equivalence check"
- Variance-aware weighting: A training scheme that up-weights prompts with higher score variance (harder/ambiguous) and down-weights easier ones. "variance-aware weighting mechanism"
- Verifiable rewards: Rewards derived from deterministic checks that indicate correctness with binary signals. "Verifiable rewards implement this idea by running a deterministic checker"
- Verifier-free RL: Methods that avoid explicit verifiers by optimizing alternative objectives that correlate with correctness. "verifier-free RL strategies like VeriFree, which bypass explicit checking"
Collections
Sign up for free to add this paper to one or more collections.

