- The paper introduces a unified framework that decouples semantic content and stylistic features through staged disentanglement and frequency-aware reconstruction.
- It achieves superior performance with improved FID, CLIP-I, DINO, and DreamSim metrics while minimizing reference-content leakage and artifacts.
- The approach enables reliable image editing for digital art, advertising, and game design by ensuring robust content preservation and controlled style transfer.
Unified High-Fidelity Content-Constrained Style Generation via Semantic and Frequency Disentanglement
Background and Motivation
Style transfer—applying a desired visual style to a content image while retaining semantic structure—is a central task in controllable image synthesis. Diffusion transformer (DiT) models are current state-of-the-art for high-resolution generation but lack robust mechanisms for content-style disentanglement, often suffering from reference-content leakage, unstable stylization, and checkerboard artifacts. Existing approaches using convolutional UNets, hybrid pipelines, or feature fusion mechanisms (e.g., ControlNet, IP-Adapter) fail to achieve fine-grained semantic separation and frequency-specific optimization, especially in challenging settings with geometric or texture-deforming styles.
UniCSG addresses these limitations through a staged, unified framework that decomposes the learning process into semantic disentanglement and frequency-aware detail reconstruction, coupled with reward-guided perceptual alignment in pixel space. This design explicitly separates structural content preservation and style injection in latent space and aligns the generation objectives with human visual perception post-decoding.
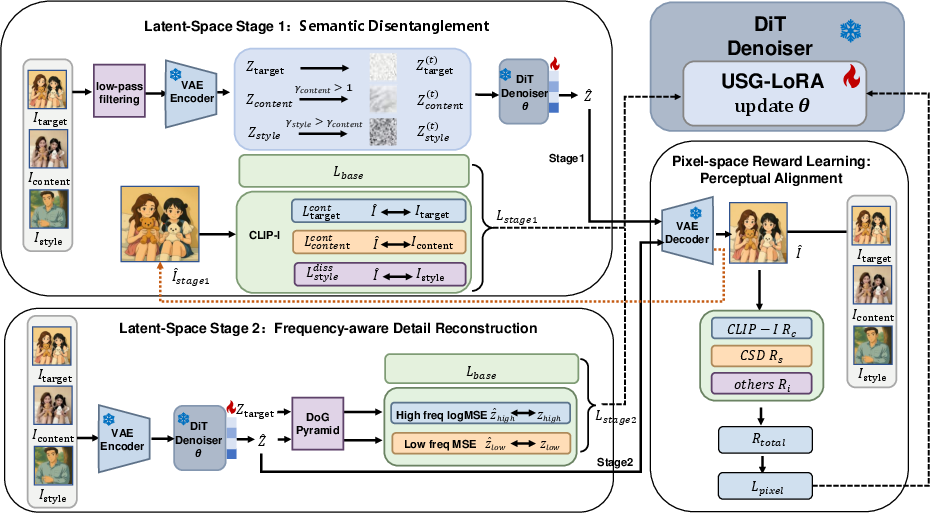
Figure 1: Schematic overview of UniCSG, showing staged semantic–frequency disentanglement and pixel-space reward-guided perceptual alignment.
Methodological Framework
1. Semantic Disentanglement (Stage 1)
The first stage operates in latent space, applying low-frequency preprocessing to input images and conditioning corruption to enforce an information hierarchy (target < content < style in corruption level). Low-pass filtering ensures that the model focuses on global contours and semantic layout, suppressing overfitting to local textures. Conditioning branches are variably noised via Gaussian amplification, strengthening the representation of core content and abstracting style cues.
Semantic supervision leverages CLIP-based image encoders, constructing loss terms for target faithfulness, content preservation, and content-style repulsion to mitigate reference-mode leakage and overly literal content transfer from style exemplars.
2. Frequency-Aware Detail Reconstruction (Stage 2)
Upon establishing a robust semantic scaffold, UniCSG transitions to full-spectrum training with frequency-domain decomposition. Latents are processed via a Difference of Gaussian (DoG) pyramid, separating low-frequency global structure from high-frequency stylization details. The loss function combines MSE for low-frequency components and LogMSE for high-frequency textures, emphasizing the refinement of transferable stylistic elements while filtering noise and outliers. The progressive decay schedule in conditioning corruption ensures a smooth handover from disentanglement to texture synthesis.
3. Pixel-Space Reward Learning
To align optimization with perceptual quality, UniCSG integrates a multi-dimensional reward module evaluated in pixel space. This module includes content-faithfulness (CLIP-I), style-alignment (CSD), LPIPS for perceptual similarity, and adversarial feedback. The reward is integrated via policy-gradient methods to bridge the gap between latent-space solutions and decoded image quality, further stabilizing stylization fidelity and detail preservation.
Dataset, Benchmarks, and Training Protocol
UniCSG is trained on a CSG-Dataset comprising 40,000 curated four-tuple samples: content image, reference style, target stylized output, and description text. The pipeline encompasses data cleaning, stylization/de-stylization cycles, and stringent filtering via semantic matchers, quality assessment (ViT/CLIP), manual annotation, and aesthetic scoring.
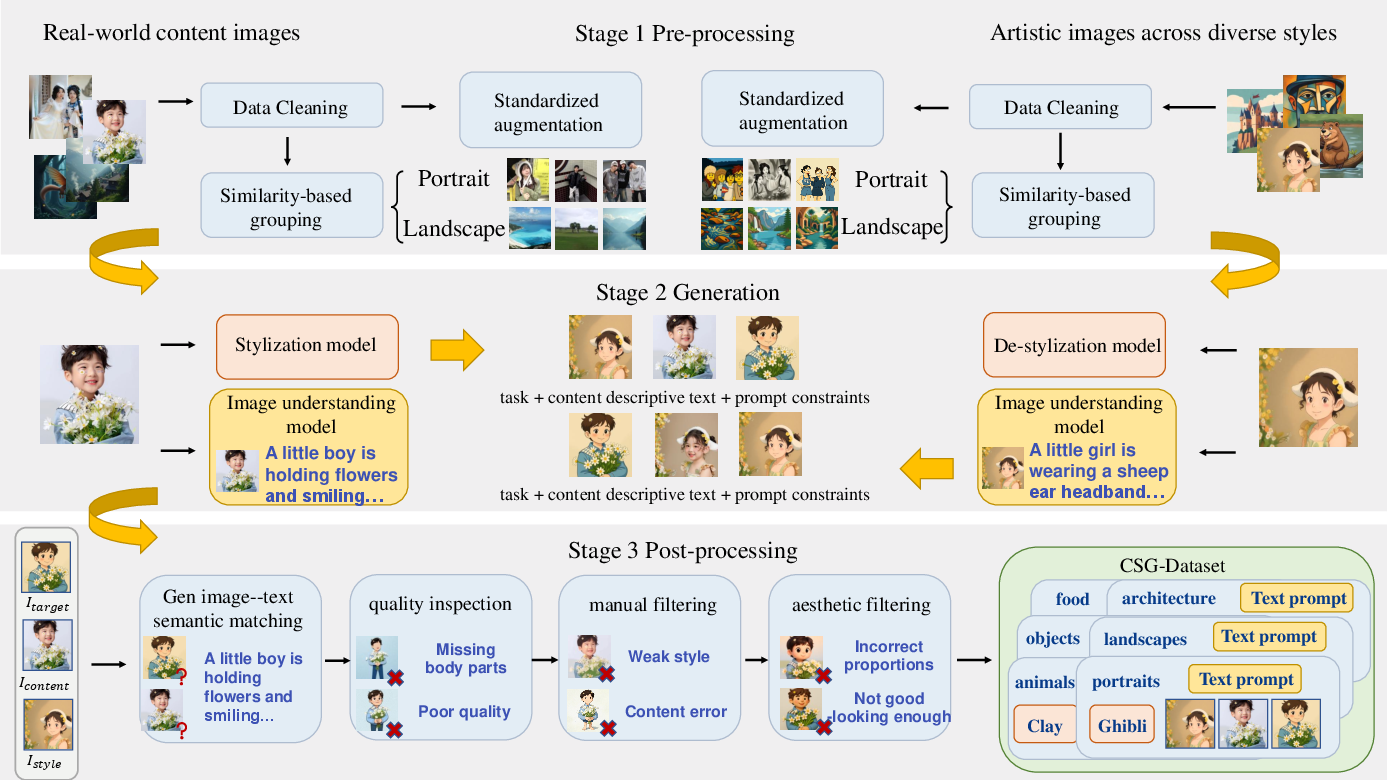
Figure 2: Visualization of the CSG-Dataset generation pipeline, showing pre-processing, mutual stylization/de-stylization, text construction, and multi-stage filtering.
Dataset coverage includes 20 styles (atmosphere, stroke/texture, geometric deformation) and six content domains, supporting both seen and unseen style evaluation settings.
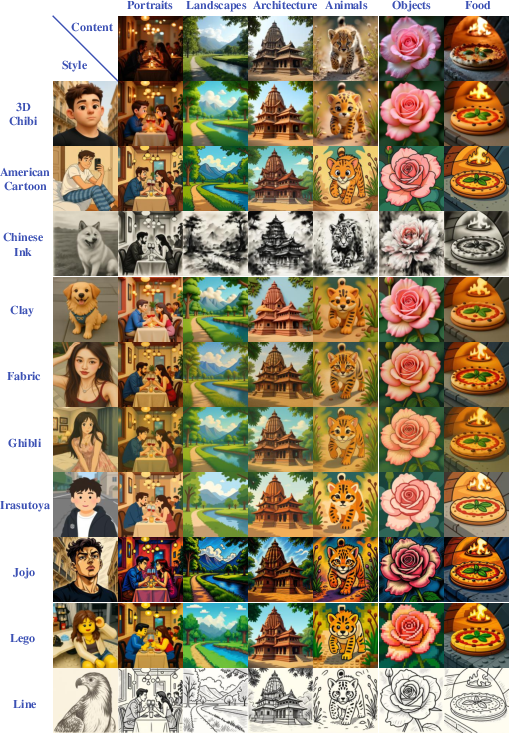
Figure 3: Matrix visualization of CSG-Dataset, illustrating comprehensive coverage of style-content pairings across portrait, landscape, animal, object, architecture, and food classes.
Results and Analysis
Quantitative Metrics
UniCSG is evaluated against eight state-of-the-art baselines on the CSG-Bench (and subset OmniConsistency-Bench) using FID, CSD, CLIP-T, CLIP-I, DINO, and DreamSim. In both text-guided and reference-guided style transfer:
- UniCSG achieves superior FID (113.94 text-guided, 87.32 reference-guided), highest CLIP-I, DINO, DreamSim metrics, and second-best style consistency across baselines.
- User preference studies indicate UniCSG is favored for both content and style consistency.
Qualitative and Ablation Analyses
Qualitative results demonstrate robust content preservation and style injection for both text- and reference-guided settings—UniCSG maintains structural fidelity while avoiding reference-content leakage and artifacts seen in competing models.

Figure 4: Sample results for text-guided style transfer showcasing faithful content preservation and strong stylization.

Figure 5: Reference-guided style transfer results, highlighting geometric and texture fidelity across transferred exemplars.
Ablation studies confirm the critical contributions of staged semantic disentanglement, frequency supervision, and reward modules. Removal of Stage 1 leads to content hallucination and severe leakage; absence of Stage 2 degrades stylization precision; exclusion of reward guidance reduces fine detail quality, most noticeably in reference-guided tasks.

Figure 6: Ablation results illustrating the effects of staged training components on stylization and content preservation across Ghibli and 3D Chibi styles.
Generalization and Failure Modes
UniCSG generalizes effectively to unseen styles, with only minor degradation in quantitative metrics. The model successfully handles the full spectrum of style complexity, from global palette shifts to geometric deformation.

Figure 7: Qualitative results for unseen styles, confirming strong generalization capability.
Failure cases include distortion of fine typography and unnatural deformation in complex hand poses—tasks requiring highly granular structural preservation remain challenging, motivating further research into cross-modal and structural regularization.

Figure 8: Failure analysis contrasting text distortion and hand gesture deformation between UniCSG and Nano-banana.
Implications and Future Directions
UniCSG demonstrates that staged latent-space disentanglement combined with frequency-targeted supervision and reward-based pixel-level alignment results in robust, high-fidelity controllable generation. The approach substantially reduces reference-content leakage, improves style transfer stability, and enhances perceptual quality. The design is effective across both text-guided and reference-guided regimes, and generalizes to unseen and challenging style categories.
Practically, UniCSG enables more reliable and flexible image editing in domains such as digital art, advertising, and game design, supporting complex requirements for content preservation and targeted style blending. Theoretically, the framework opens avenues for further architectural advances in DiT-based generative models and multi-stage objective design.
Future directions include enhancing structural preservation for highly localized content (e.g., text, hands), exploring more efficient and generalized reward modeling, and extending controllable generation paradigms to cross-modal and cross-domain tasks.
Conclusion
UniCSG introduces a unified framework for content-constrained, style-driven image generation leveraging staged semantic and frequency disentanglement with reward-guided perceptual alignment. The method achieves superior fidelity, controllability, generalization, and style diversity versus leading baselines, setting a new benchmark for robust content-style manipulation in diffusion transformer models.