- The paper introduces Re2MoGen, a three-stage framework that combines LLM reasoning, MCTS-enhanced keyframe planning, and physics-aware RL refinement for robust open-vocabulary text-to-motion generation.
- Quantitative results show significant improvements in semantic alignment and physical plausibility over prior methods, including state-of-the-art baselines such as MDM, MLD, and MotionGPT.
- The approach enables generalizable, realistic motion synthesis applicable to character animation, robotics, and embodied AI by bridging high-level linguistic instructions with low-level physical execution.
Re2MoGen: Open-Vocabulary Motion Generation via LLM Reasoning and Physics-Aware Refinement
The generation of human motion from textual descriptions, commonly known as Text-to-Motion (T2M), has progressed significantly, particularly for motions within the distribution of training data. However, a notable challenge remains in synthesizing plausible and semantically consistent motions for open-vocabulary descriptions that deviate substantially from the training corpus. The Re2MoGen framework addresses this limitation through a novel, multi-stage approach that integrates LLM reasoning with physics-aware refinement techniques.
Framework Overview
Re2MoGen operates through three distinct yet interconnected stages: MCTS-enhanced LLM Reasoning, Motion Completion and Finetuning, and Physics-aware Refinement. This top-down decomposition enables the framework to first construct a high-level motion plan and then iteratively refine its spatiotemporal coherence and physical plausibility. The overall architecture is designed to progressively transform abstract textual commands into concrete, executable motion sequences.
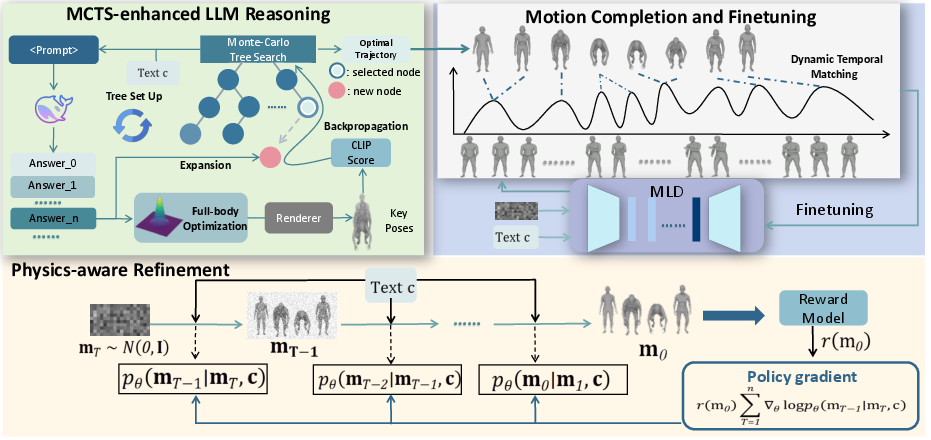
Figure 1: The framework of Re2MoGen, which consists of three key parts: (i) MCTS-enhanced LLM Reasoning; (ii) Motion Completion and Finetuning, and (iii) Physics-aware refinement.
MCTS-Enhanced LLM Reasoning
Traditional LLM applications in motion planning are often hampered by their inherent limitations in spatial reasoning and physical understanding, especially when dealing with explicit 3D joint positions and the intricate temporal correlations within motion sequences. Re2MoGen mitigates these challenges by employing Monte Carlo Tree Search (MCTS) to augment the LLM's reasoning capabilities.
The core idea is to guide the LLM in generating a sequence of keyframes, focusing only on the root (pelvis) and four end-effector joints (left/right wrist and left/right ankle). This simplification reduces the complexity of the planning task, making it more tractable for the LLM. An MCTS-enhanced approach, specifically through the construction of a Motion Keyframe Tree (MKT), allows for a systematic exploration of potential keyframe sequences. Each node in the MKT represents a segment of keyframes, and paths from the root to a leaf node correspond to complete keyframe sequences. The MCTS process involves iterative selection, expansion, simulation, and backpropagation phases. During simulation, potential keyframe sequences are evaluated for semantic consistency with the input text using a CLIP-based scoring mechanism. This process iteratively refines the keyframe generation by rewarding sequences that align well with the textual description, thereby solidifying the initial motion plan.
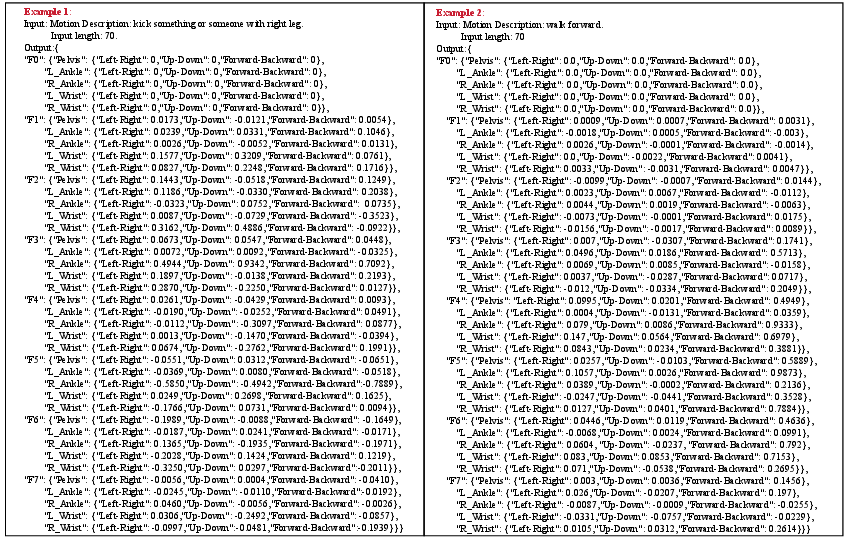
Figure 2: Examples for LLM reasoning.

Figure 3: Related reasons for the given examples.
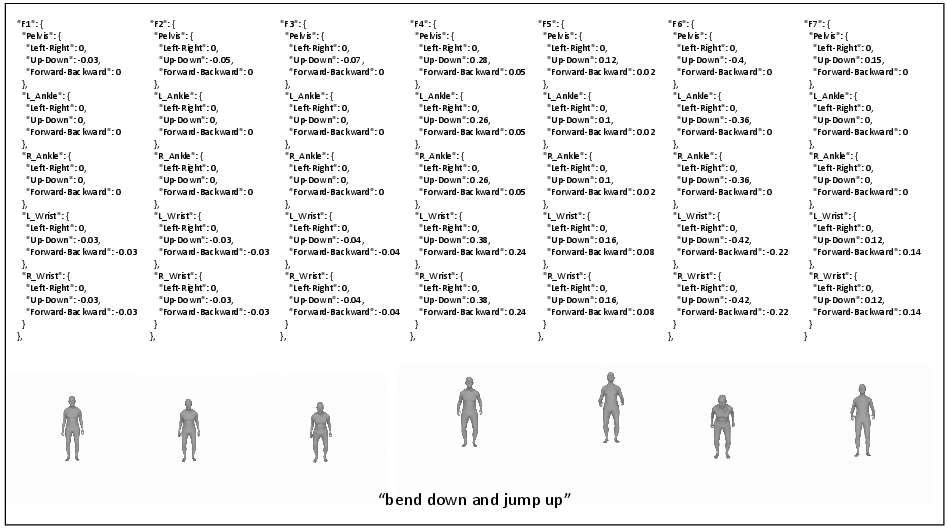
Figure 4: LLM-planned key joint positions and rendered images.
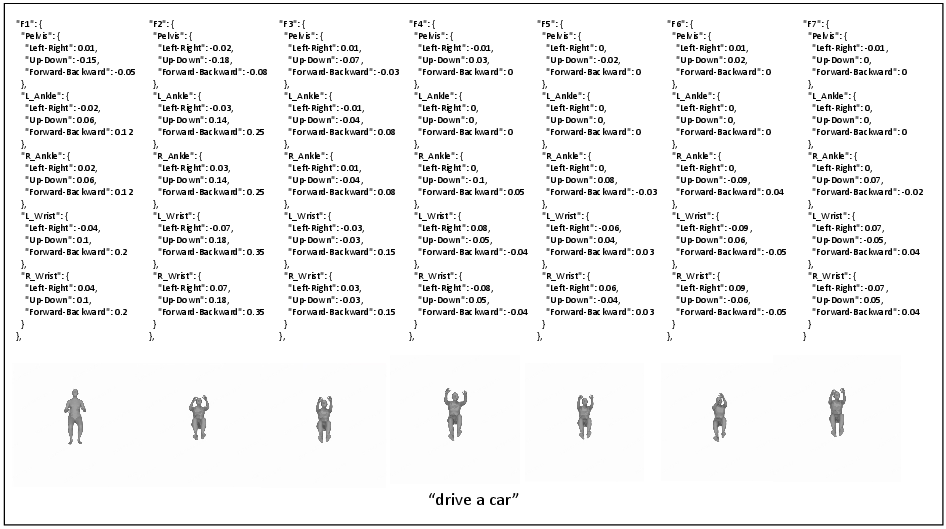
Figure 5: LLM-planned key joint positions and rendered images.
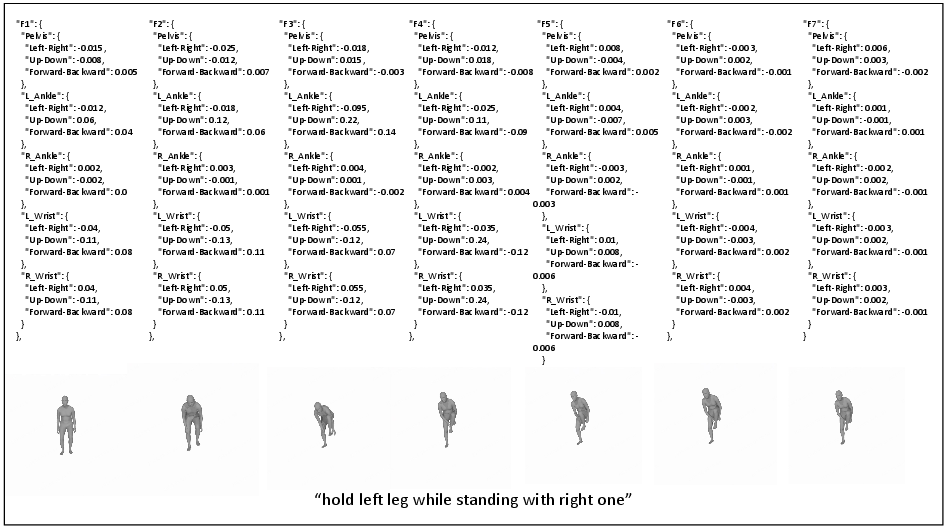
Figure 6: LLM-planned key joint positions and rendered images.
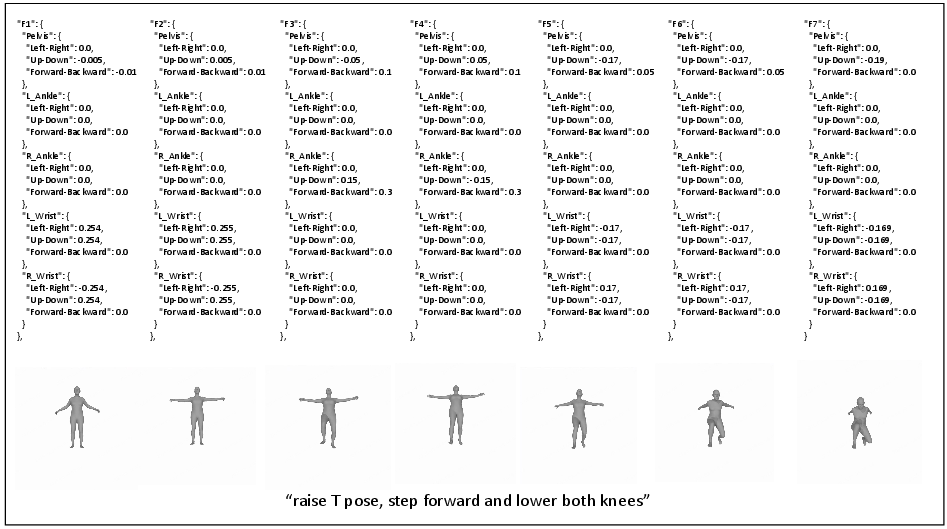
Figure 7: LLM-planned key joint positions and rendered images.

Figure 8: LLM-planned key joint positions and rendered images.
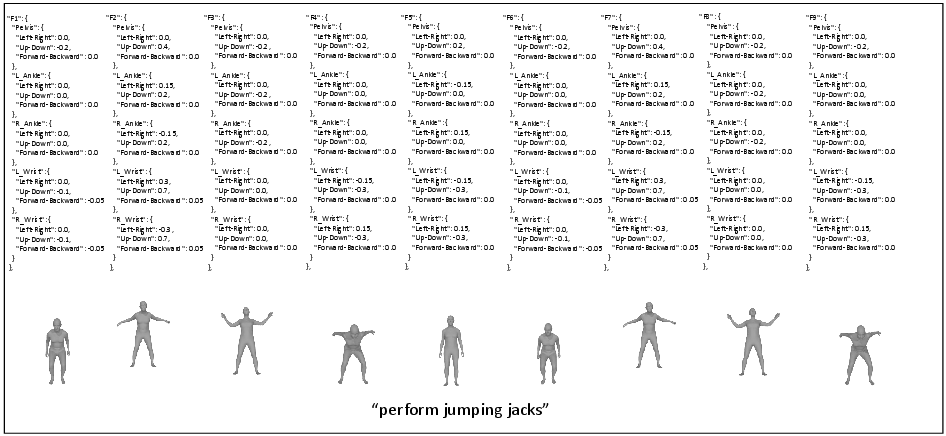
Figure 9: LLM-planned key joint positions and rendered images.
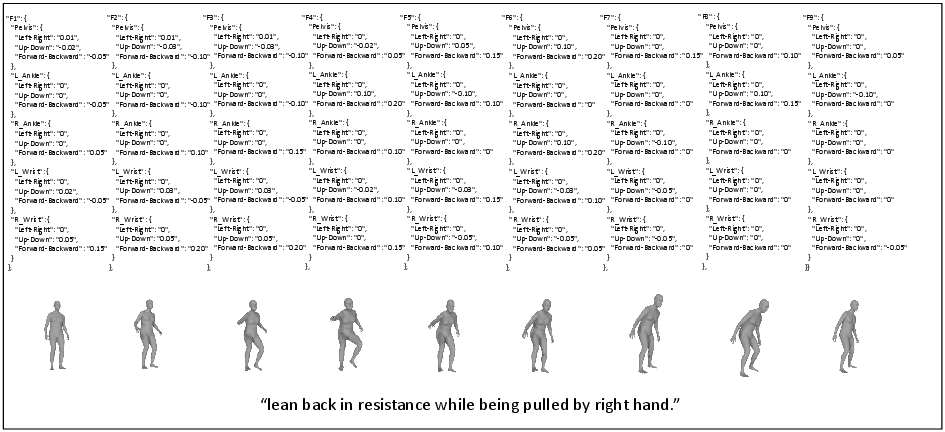
Figure 10: LLM-planned key joint positions and rendered images.
Motion Completion and Finetuning
Following the MCTS-enhanced LLM reasoning, the system obtains a sequence of key joint positions. The subsequent stage, Motion Completion and Finetuning, transforms these sparse keyframes into a complete, full-body motion sequence.
The first step in this stage is Full-body Pose Optimization. Since the LLM only provides positions for a limited set of key joints, a human pose model, specifically an extended VPoser trained on AMASS and Motion-X datasets, is employed as a prior to infer the complete full-body poses. This is achieved by optimizing latent codes in VPoser's learned latent space, regularized by a term penalizing deviations from the learned distribution, to ensure the decoded pose adheres to both the LLM-planned key joint positions and human pose priors.
For Spatiotemporal Motion Completion, a pre-trained Motion Latent Diffusion (MLD) model is finetuned using the optimized key poses. A key innovation here is the introduction of a dynamic temporal matching objective, Ltemporal, based on soft-Dynamic Time Warping (soft-DTW). This objective allows for flexible temporal alignment between the generated motion sequence and the LLM-planned key poses, which are not inherently synchronized. This, combined with a reconstruction loss (Lrecon) that ensures adherence to key poses, enables the MLD model to generate smooth, fine-grained motions that extend the sparse keyframes into a complete sequence. The ablation studies confirm the criticality of both MCTS and dynamic temporal matching, showing significant performance drops in semantic alignment when either component is omitted (e.g., CLIP_S of 22.57 without MCTS compared to 23.64 with MCTS, and 23.16 without Ltemporal).
Physics-Aware Refinement
Despite the semantic consistency achieved through LLM reasoning and spatiotemporal completion, the generated motions may still suffer from physical implausibilities such as foot sliding, ground penetration, and floating artifacts. To address these issues, Re2MoGen incorporates a physics-aware refinement stage using Reinforcement Learning (RL) post-training.
The reverse denoising process of the MLD model is framed as a Markov Decision Process (MDP), where the model acts as a parameterized policy. The objective of this RL post-training is to maximize an expected physics-aware reward function. Three specific metrics are utilized as reward components: a foot sliding reward, a floating reward, and a ground penetration reward. These rewards are designed to penalize deviations from physically realistic motion patterns. Proximal Policy Optimization (PPO) is employed to maximize this objective, along with a Kullback-Leibler (KL) divergence objective to prevent excessive deviation from the original policy. Quantitative results demonstrate that RL post-training significantly enhances physical plausibility, reducing Floating from 16.85 to 2.46 and Penetration from 32.84 to 21.70. This refinement directly translates to improved trackability by imitation policies in physics simulations, highlighting the practical benefits of physically plausible motions.
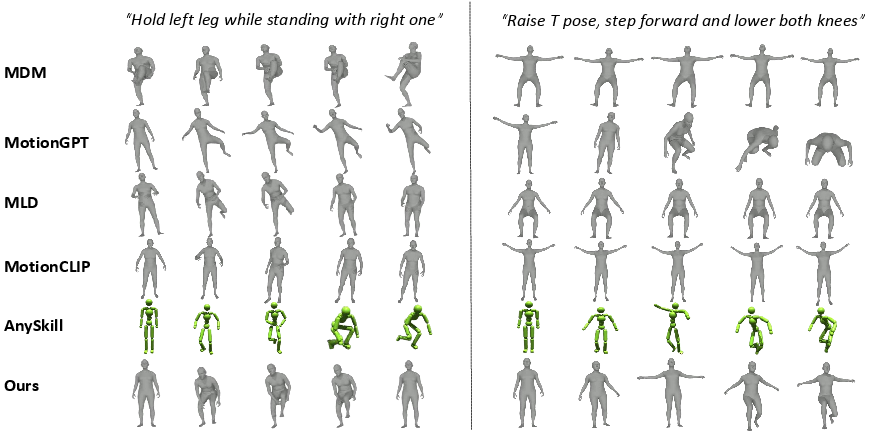
Figure 11: Qualitative comparison results of motions generated by different methods.
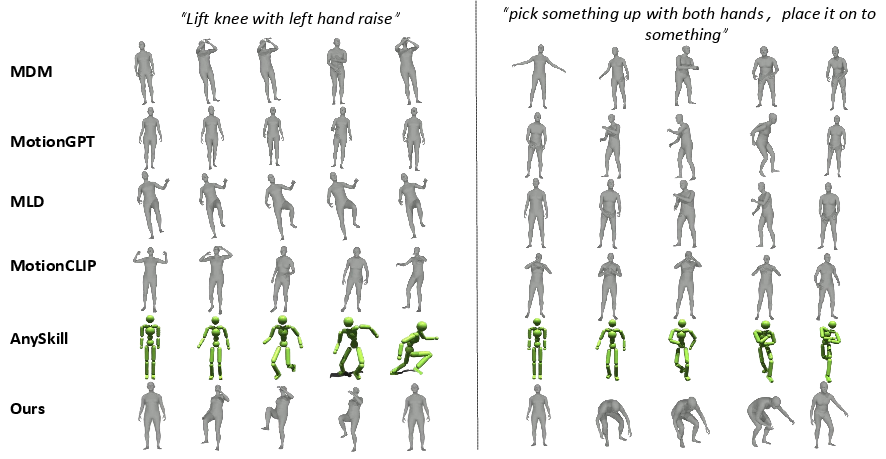
Figure 12: Additional qualitative comparison results of motions generated by different methods.
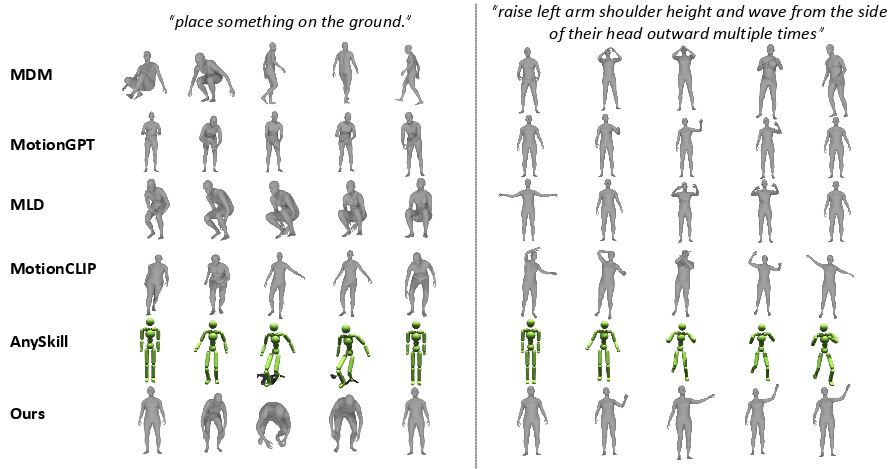
Figure 13: Additional qualitative comparison results of motions generated by different methods.
Experimental Validation and Implications
Extensive experiments on open-vocabulary motion generation demonstrate Re2MoGen's superior performance across semantic alignment and physical plausibility compared to state-of-the-art baselines like MDM, MLD, MotionGPT, MotionCLIP, and AnySkill. The framework particularly excels in handling novel and sequential motion descriptions, as evidenced by its higher CLIP_S and VLM_S scores (23.64 and 2.72 respectively for the full model). This robust generalization capability is directly attributable to the symbiotic relationship between LLM reasoning and physics-aware refinement.
The implications of Re20MoGen are substantial. Practically, the ability to generate physically plausible motions from open-vocabulary text could revolutionize character animation in gaming and film, robotic control, and virtual reality environments. The sim-to-sim transfer experiments on the MuJoCo platform and deployment on real-world robots further underscore the direct applicability and robustness of the generated motions. Theoretically, this work highlights the potential of integrating LLMs with advanced control and physics engines, pushing the boundaries of what is possible in embodied AI and bridging the gap between high-level linguistic instructions and low-level physical execution. Future developments could explore more complex multi-character interactions, real-time adaptation, and further integration of multimodal input for even richer motion generation.
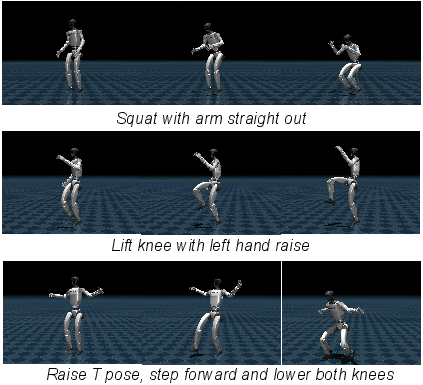
Figure 14: Visualization of our generated motions on the MuJoCo platform.

Figure 15: Additional results on the MuJoCo platform.
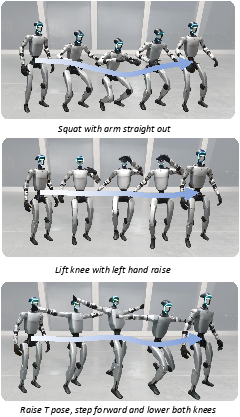
Figure 16: Deploy generated motions on the real world robot.
Conclusion
Re21MoGen establishes an effective pipeline for open-vocabulary motion generation by synergistically combining LLM-based reasoning and physics-aware refinement. The framework’s structured approach, from MCTS-enhanced keyframe planning to dynamic temporal completion and RL-guided physical correction, enables the generation of semantically consistent and physically plausible human motions. This research not only advances the state of T2M generation but also provides a robust foundation for future endeavors in embodied AI, particularly in applications requiring intuitive and generalizable control of virtual and physical agents.