- The paper demonstrates a novel human-in-the-loop text-to-model pipeline that automates generating structurally valid TMK procedural models from instructional artifacts.
- The approach uses ontology-constrained prompt engineering and JSON scaffolds to extract and organize domain concepts, enabling efficient expert refinement for semantic fidelity.
- Empirical results show up to a 70% reduction in authoring time while achieving high structural and instructional alignment across diverse AI tutoring scenarios.
AI-Assisted Text-to-Model Authoring for Procedural Skill Representation: An Expert Overview
Problem Motivation and Approach
Scalable, structured AI tutoring systems require explicit, machine-interpretable models of procedural skills. Traditional manual authoring of such models, especially detailed ontologies like Task-Method-Knowledge (TMK) structures, constitutes a major bottleneck, often involving upwards of 200-300 expert hours per instruction hour for robust Intelligent Tutoring System (ITS) deployment. The paper proposes a human-in-the-loop, LLM-driven text-to-model (TTM) pipeline that constrains LLM output to domain-specific schemas, automating the drafting of syntactically and structurally valid TMK models from instructional artifacts (e.g., lecture transcripts) while retaining human oversight for semantic and procedural fidelity.
The pipeline leverages ontology-constrained prompt engineering and schema-complete, content-empty JSON templates. LLMs automate the extraction and structuring of domain concepts, task decompositions, methods (often as FSMs), and associated knowledge graphs. The resulting drafts are iteratively refined by domain experts to ensure causal consistency and instructional alignment, addressing domain- and task-specific nuances that remain out of reach for unconstrained generative models. This division of labor targets high-impact scalability gains in the bottleneck of procedural skill model authoring for AI tutoring contexts.
System Architecture
At the core of the TTM pipeline is a schema-driven generation-refinement loop:
- Inputs: Instructional documents, TMK schemata, representational guidelines, and JSON scaffolds.
- LLM Generation: A large model (e.g., Gemini 3) synthesizes schema-compliant drafts, assigning extracted procedural and ontological elements to the appropriate TMK categories.
- Expert Iteration: Human experts review and revise drafts, identifying missing causal transitions, weakly encoded failure handling, misaligned terms, or shallow decompositions. Refinement prompts target these deficiencies, iteratively enhancing draft quality.
This workflow enables strict syntactic and structural validity by design, while shifting expert effort toward high-level semantic refinement. The approach is instructor-facing and intentionally minimizes required technical expertise with formal representations.
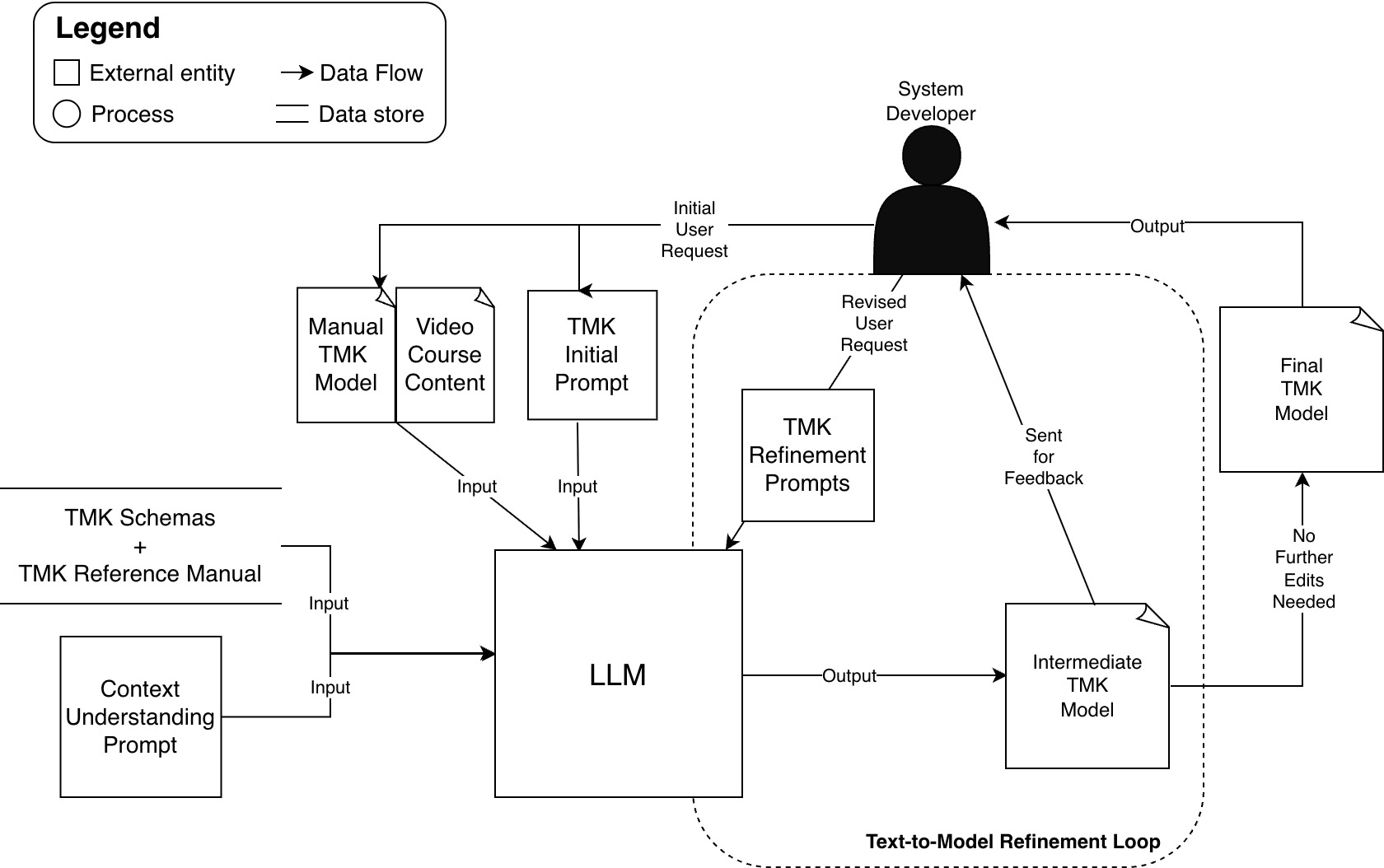
Figure 1: Human-in-the-loop text-to-model architecture illustrating schema-constrained generation and iterative refinement.
Evaluation Methodology
A multi-dimensional evaluation framework is articulated, encompassing:
- Syntactic Metrics: Structural validity (schema conformance, reference completeness), structural binding across TMK components (e.g., Task-Method and Method-Knowledge connectivity), and procedural heuristics (e.g., presence and depth of guard logic, explicit modeling of failure, hierarchical decomposition).
- Semantic Metrics: Lexical instructional alignment (terminological consistency between generated models and instructional sources), similarity-based comparisons (cosine similarity by TMK component between raw LLM output, refined models, and prior expert-crafted baselines), and stability analysis (output consistency under fixed input and prompting).
- LLM-Assisted Judging: Rubric-scored evaluation of causal chaining, teleological clarity, and procedural fidelity via a separate LLM as an "external" judge, calibrated to TMK semantics.
- Authoring Effort: Quantitative measurement of expert time spent refining LLM outputs to deployment-ready models, relative to baseline manual authoring time, yielding a direct measure of efficiency gain.
Empirical Results
Application to 23 graduate-level online AI course skills, with an additional probe in organic chemistry, yielded the following:
- Syntactic and Structural Validity: All outputs conformed to required JSON schemas; connectivity and binding measures improved substantially post-refinement, reflecting effective division of labor.
- Instructional Alignment: Improved from 0.67 (raw) to 0.82 (refined), indicating that expert revision incrementally rectifies lexical misalignment.
- Semantic Similarity: Strong mean cosine similarities were observed between raw LLM drafts and expert-crafted baselines (tasks: 0.79, methods: 0.85, knowledge: 0.71). Post-refinement, similarity increased to ≈0.9 across TMK components, with lower per-field scores reflecting finer-grained divergences addressed in expert editing.
- Generation Stability: Re-running generations with identical prompts and templates resulted in nearly identical models (score ≈ 1.0), affirming consistency under ontology-constrained prompting.
- Efficiency: Manual TMK authoring was reduced from ~6–7 hours per model to ~2 hours (median 2.0, SD 0.42), a 50–70% reduction. Expert effort focused on correcting subtle causal, relational, or pedagogical errors rather than reconstructing models wholesale.
- Common Refinement Patterns: Experts frequently decomposed underspecified tasks, refined guard logic, removed misplaced artifacts, and strengthened semantic ties to instructional content. Edge-case handling and FSM logic often lagged in raw drafts, necessitating targeted intervention.
Implications and Limitations
Practical Implications
The TTM pipeline demonstrates that LLMs, under tightly constrained schema scaffolds, can reliably generate valid high-level procedural representations suitable for rapid iterative refinement by human experts. These models directly facilitate the construction of scalable, structured AI tutoring systems—enabling dynamic explanation generation, state tracking, and reliable intervention mechanisms across large curricula.
The dual-process workflow—automated generation for structural scaffolding, expert curation for semantic and pedagogical accuracy—substantially lowers the barrier to wide-scale procedural model authoring, a critical advance for both educational technology and other domains demanding formalized procedural knowledge.
Theoretical Implications
The design validates that leveraging explicit representational ontologies (TMK) as both authoring constraints and runtime execution scaffolds is synergistic with advanced LLM capabilities. It supports the broader thesis that hybrid neuro-symbolic approaches, which combine generative flexibility with symbolic validity and explicit knowledge grounding, are essential for trustworthy, interpretable AI applications.
Observed limitations—cascading conceptual errors, shallow decomposition depth, and gaps in edge-case modeling—highlight current LLM shortfalls in procedural abstraction and underscore the continuing necessity of expert-in-the-loop oversight. Representational granularity remains an open design challenge, influenced by both model priors and the epistemic structure of instructional artifacts.
Limitations and Open Questions
- Domain Generality: The pipeline's efficacy outside well-scoped STEM domains remains largely untested; different procedural genres (e.g., clinical protocols, creative workflows) may require extensions to the current schema-driven approach.
- Authoring Usability: Reliance on JSON editing and FSM inspection may limit adoption among non-AI-expert instructors, motivating the development of user-friendly graphical or schema-aware interfaces.
- Automated Semantic Reasoning: While syntactic validity is guaranteed, high-level semantic and causal adequacy is not, particularly for edge cases and rare procedural variants.
Future Directions
Key development avenues include:
- Scaling Across Curricula: Extending to a broader variety of instructional genres and domains, accompanied by system-level evaluations to directly measure impact on learning outcomes.
- Enhanced Prompt Engineering and Tooling: Refining LLM prompts to elicit deeper decompositions and more comprehensive failure modeling; exploring grammar-based compilers and editors to further automate reasoning support.
- User Experience and Generality: Building domain-general, accessible authoring interfaces to democratize structured procedural modeling; empirically testing cross-domain adaptability.
Conclusion
The AI-assisted text-to-model approach offers a scalable, reproducible solution to the procedural skill authoring bottleneck in structured AI tutoring systems. Ontology-constrained LLM prompting automates the generation of syntactically and structurally robust drafts, while expert-in-the-loop refinement ensures semantic, causal, and pedagogical fidelity. This methodology yields a significant reduction in authoring costs and positions explicit TMK-based representations as practical and extensible foundations for future neuro-symbolic educational AI development. However, expanding domain coverage, automating deeper semantic reasoning, and improving authoring usability remain vital next steps for broad adoption and theoretical advancement.