- The paper presents a novel semantic search engine that curates 8.07 million statements from 435,000 peer-reviewed papers and textbooks to enhance math literature retrieval.
- The paper details a two-stage extraction pipeline using DeepSeek-V3.2 to recover fine-grained mathematical statements and construct directed dependency graphs for self-contained results.
- The paper leverages Qwen3-Embedding-8B to embed unfolded statements into a vector database, enabling efficient and context-aware retrieval for both human users and AI systems.
Matlas: A Semantic Search Engine for Mathematics
Motivation and Problem Context
Mathematics research relies fundamentally on the ability to retrieve, interpret, and connect formal results embedded in an expansive and continuously growing literature. The explosion in the number of mathematical publications, as quantified by data from MathSciNet since the 19th century, presents significant obstacles for both human researchers and AI-enabled mathematical discovery. A primary technical challenge is rooted in the fragmentary nature of mathematical writing—statements such as theorems, definitions, and lemmas are often context-dependent, reliant on prior results, and scattered across millions of documents. This context dependence, combined with the scale of the literature, impedes reliable and efficient search, reuse, and formal reasoning.
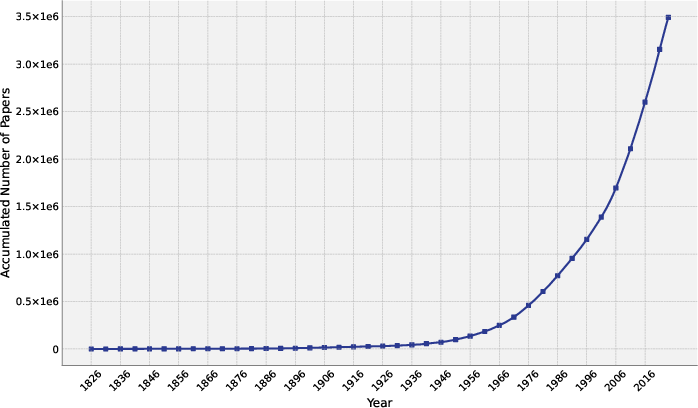
Figure 1: The cumulative number of mathematics journal papers from 1826 to 2024 computed from MathSciNet metadata.
Compounding these difficulties, existing semantic search solutions for mathematics either focus on relatively narrow formal corpora (e.g., mathlib4) or rely on preprints, which lack uniform reliability. AI systems for mathematics, especially those employing LLMs, further intensify the need for robust grounding on high-fidelity, self-contained knowledge bases. The absence of infrastructures that combine large-scale, peer-reviewed coverage, fine-grained knowledge units, and explicit dependency-tracking remains a central barrier.
Dataset Construction and Corpus Curation
Matlas addresses this deficiency with a rigorously curated corpus comprising 8.07 million statements extracted from 435,000 peer-reviewed papers (spanning 1826–2025) and 1,900 textbooks, sourced from 180 journals selected via ICM citation-based criteria. The journal selection method ensures both domain relevance and citation impact while filtering out low-quality venues. Raw PDF documents are processed with OCR to maximize coverage, and textbooks are chosen from major academic publishers. This approach yields a corpus that supports both reliability (favoring published, peer-reviewed work) and breadth (covering most of modern mathematics).
Extraction Pipeline: Statement and Dependency Recovery
The extraction process centers on a two-stage pipeline that overcomes the limitations of naive chunk-based or context-insensitive approaches for mathematical text. An LLM (DeepSeek-V3.2) is employed to first synthesize document-specific patterns for segmenting statements, generating stable indices for each statement unit (definition, theorem, lemma, etc.).
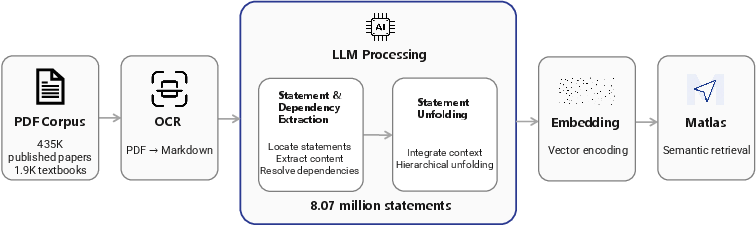
Figure 2: Overview of the Matlas pipeline from PDF collection through statement extraction, dependency graph construction, unfolding, and semantic search.
This locator is then followed by a structurer, which, using windowed context and overlapping batch inputs, recovers fine-grained statement representations and explicit local dependencies. All dependencies are maintained as directed edges in a document-local graph. This strategy ensures that essential short-range and cross-referential relationships are not lost, supporting accurate subsequent unfolding.
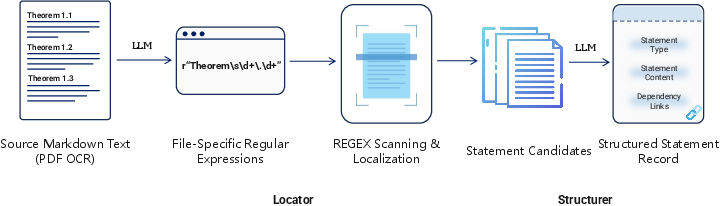
Figure 3: Two-stage pipeline for statement and dependency extraction, consisting of a locator and a structurer.
By explicitly reconstructing the directed acyclic graph of dependencies for each document, Matlas captures the hierarchical and referential logic that is intrinsic to mathematical discourse, surpassing the granularity and precision of prior retrieval systems.
Statement Unfolding: Achieving Self-Containment
A defining feature of Matlas is its mechanism for recursive statement unfolding. Each document-specific dependency graph is topologically sorted into layers: nodes with zero in-degree are unfolded first, and each subsequent layer builds by recursively expanding dependent statements with their prerequisites. This incremental, multi-layer expansion ensures that every unfolded statement is as self-contained as possible, recursively integrating definitions and prior lemmas referenced in the text.
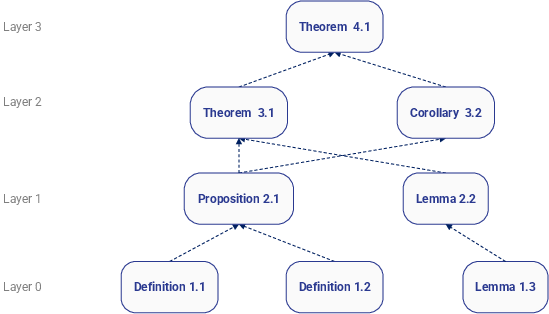
Figure 4: Example of a directed dependency graph and its layered structure used for statement unfolding.
This methodology contrasts with prior work such as (Peyronnet et al., 27 Feb 2026), which attempts context recovery in bulk using full-document or vector-based retrieval. The stepwise, compositional expansion in Matlas is more robust, reflecting the true logical structure of mathematical discourse.
Semantic Retrieval System
The finalized corpus of unfolded statements is embedded into high-dimensional vectors using the Qwen3-Embedding-8B model (Zhang et al., 5 Jun 2025). All embeddings are stored in a vector database, supporting efficient large-scale dense retrieval. Natural language queries are processed to generate query embeddings, and candidates are ranked using cosine similarity. The retrieval system is designed to support both informal and technical phrasings, maximizing accessibility.
The pipeline supports theorem retrieval both for human users—who may be searching for unknown or related results—and for AI mathematical agents needing reliable, contextualized grounding. The interface and API endpoints (https://matlas.ai/) target both use cases, enabling programmatic and interactive access.
Distinctiveness and Empirical Validation
Matlas advances beyond earlier efforts—including (Alexander et al., 5 Feb 2026), which draws primarily on arXiv preprints and lacks explicit dependency-aware statement unfolding—by building its database on published, peer-reviewed sources and integrating hierarchical dependency tracking. This systematic focus on both reliability and contextualization underpins its utility for autonomous mathematical agents, and for workflows demanding strict attribution and provenance.
In an early use case, Matlas was instrumental in enabling a natural language reasoning agent to autonomously resolve an open conjecture by retrieving a critical technical lemma (Ju et al., 4 Apr 2026), empirically verifying the effectiveness of dependency-aware retrieval in practical research scenarios.
Implications and Future Research
Matlas represents a foundational step toward machine-interpretable and AI-grounded infrastructure for mathematical knowledge retrieval. For mathematicians, it streamlines literature search, reduces duplication of known results, and supports more precise historical attribution. For AI systems, it provides high-quality, self-contained knowledge units suited for formal verification, proof generation, and autonomous research programs.
Theoretical implications include the opportunity to study the structural properties of mathematical knowledge at scale (e.g., the topology of dependency graphs, cross-domain transfer of tools via dependency patterns), as well as to drive advances in mathematical ontologies and formalization pipelines. Practically, Matlas can inform the construction of next-generation benchmarks for LLM-based automatic theorem proving, proof assistance, and mathematical question answering.
Prospects for future iteration include expansion to wider formal and informal sources, improved LLM architectures for extracting long-range dependencies, and tighter integration with interactive proof assistants. Additionally, enhancing the coverage for multi-lingual and multi-modal (e.g., diagrams) mathematical texts stands as a challenging but valuable direction.
Conclusion
Matlas offers a robust, scalable, and context-sensitive infrastructure for semantic mathematics retrieval by integrating fine-grained statement extraction, explicit dependency resolution, unfolding for self-containment, and state-of-the-art vector embedding. These design choices directly address the limitations of existing systems and respond to the unique requirements of both human and machine mathematicians. By supporting the systematic organization and cross-linking of mathematical knowledge at the statement level, Matlas sets the stage for enhanced literature search, reliable grounding of AI systems, and the advancement of mathematical discovery infrastructures (2604.17484).