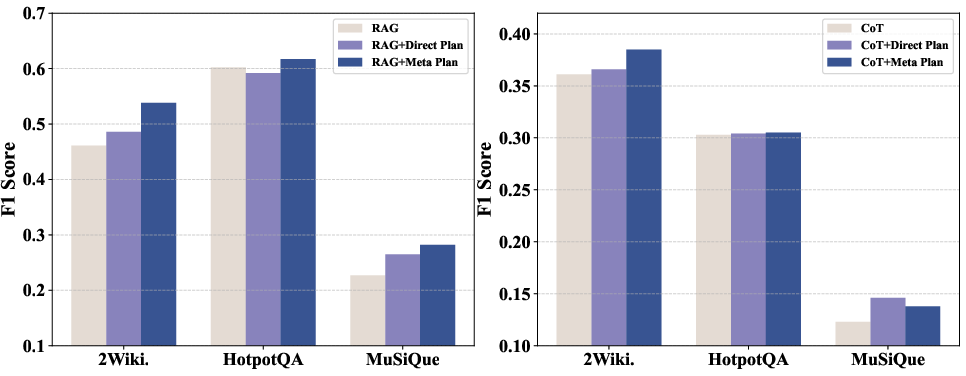
- The paper introduces a modular framework that disentangles reasoning into strategy, control, and execution layers for robust multi-hop question answering.
- The paper employs dynamic scheduling and self-supervised fine-tuning to enhance retrieval accuracy and execution efficiency.
- The paper demonstrates improved performance and resilience across benchmarks, especially under noisy, compositional, and deep reasoning conditions.
STRIDE: Strategic Iterative Decision-Making for Retrieval-Augmented Multi-Hop Question Answering
Motivation and Problem Setting
Multi-hop question answering (MHQA) requires the synthesis of evidence and reasoning over multiple documents, posing a significant challenge beyond single-hop queries resolvable via simple information retrieval. The dominant paradigm, Retrieval-Augmented Generation (RAG), enables LLMs to ground outputs in external sources. Standard or even iterative RAG pipelines, however, are hindered by two central problems: (1) premature entity grounding preceding reasoning skeleton abstraction, causing brittle disambiguation and error cascades, and (2) rigid, sequential sub-question scheduling that neglects complex dependency structures among reasoning steps.
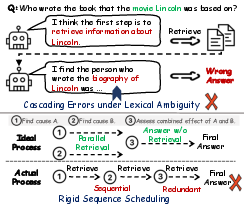
Figure 1: Key challenges in current iterative RAG are premature entity grounding (top, leading to cascading errors) and rigid scheduling (bottom, failing to account for dependency-rich sub-questions).
These deficiencies are especially detrimental for complex, compositional queries where successful inference is contingent on both robust high-level strategy and adaptive, context-aware execution control.
STRIDE Framework: Hierarchically Structured Reasoning
STRIDE directly addresses these limitations via explicit decomposition of the MHQA process into three decision-making layers—Strategy, Control, and Execution—mirroring real-world hierarchical decision paradigms.
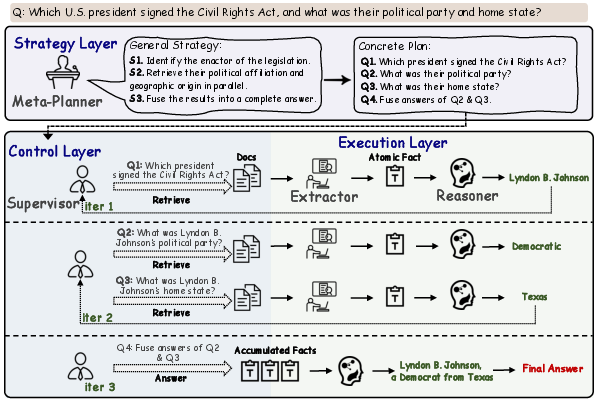
Figure 2: The STRIDE framework decomposes reasoning into strategy, control, and execution modules, each responsible for a distinct set of responsibilities.
The Meta-Planner first constructs an abstract, entity-agnostic reasoning skeleton (“General Strategy”), separating logical flow from surface-level entity commitments. Only once the overall logic and dependency paths across entities and relations are set does the system instantiate a “Concrete Plan” of executable, entity-specific sub-questions. This separation improves robustness to lexical ambiguity and enables transferable planning over structurally similar queries.
Control Layer: Supervisor and Adaptive Scheduling
The Supervisor dynamically orchestrates sub-question execution according to their logical dependencies. By maintaining the evolving execution state, it enables:
- Parallel execution of independent branches
- Sequential or fork-join coordination for dependent sub-questions
- Adaptive choice between evidence retrieval and inference-only reasoning
- On-the-fly query rewrites when retrieval fails or disambiguation is required
- Cross-branch information fusion and robust fallback behaviors for execution failures
Execution Layer: Extractor and Reasoner
Execution is further modularized via specialized LLM-based units:
- Extractor for atomic fact grounding from retrieved documents
- Reasoner for logical synthesis over current fact sets
This decomposition ensures interpretability, faithfulness, and more structured supervision for downstream fine-tuning.
Modular Self-Supervised Fine-Tuning (STRIDE-FT)
To improve open-source LLM deployment within STRIDE, STRIDE-FT introduces modular self-supervised fine-tuning using execution traces from STRIDE itself, thus requiring neither human annotation nor teacher models. Components are fine-tuned for plan preference (Meta-Planner), effective rewrites (Supervisor), minimal necessary fact extraction (Extractor), and concise, deterministic answer generation (Reasoner), using trajectory-level success signals and outcome filtering.
Empirical Evaluation
Experiments span three MHQA benchmarks (2WikiMultihopQA, HotpotQA, MuSiQue) and both open- and closed-source LLMs (Qwen3-8B, GPT-4o-mini).
Key empirical findings:
Furthermore, STRIDE demonstrates the smallest performance degradation under corpus expansion to 50,000 documents, confirming its robustness in high noise, open-domain conditions.
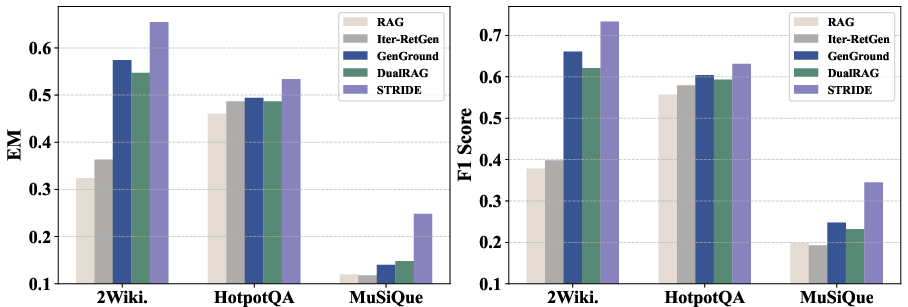
Figure 4: STRIDE maintains superior performance under large, noisy retrieval corpora, showing smallest performance drop among evaluated methods.
It also exhibits strong gains at increasing reasoning depths (number of hops), confirming its ability to manage complex, long-horizon inference chains.
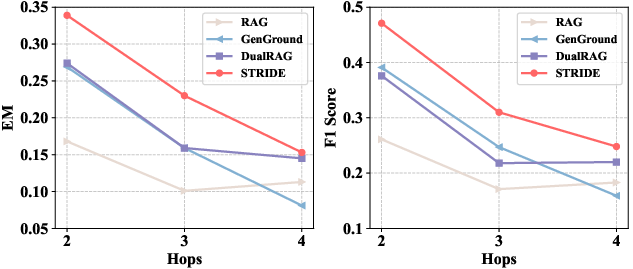
Figure 5: STRIDE consistently outperforms baselines at all reasoning depths (hops) in MuSiQue, confirming robustness in complex multi-hop settings.
Ablation studies indicate:
- All core modules are critical; the Supervisor’s dynamic scheduling yields the largest independent contribution.
- Modularity in fine-tuning provides strictly additive improvement, with the Reasoner benefiting most from component-level adaptation.
STRIDE is also highly efficient—achieving higher F1 at lower average token usage and wall-clock inference time compared to strong baselines, due to precise and non-redundant retrieval-generation cycles.
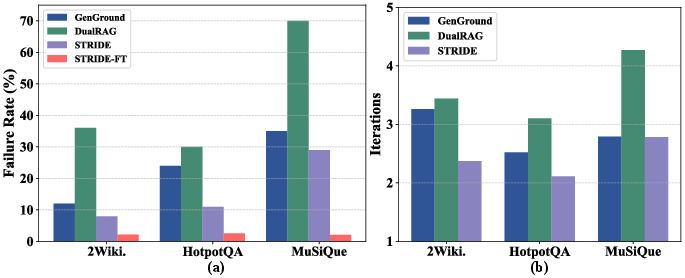
Figure 6: (a) STRIDE achieves the lowest failure rate; (b) STRIDE and especially STRIDE-FT require fewer average iterative refinements per instance, indicating higher execution efficiency and reliability.
Finally, STRIDE's structured, focused sub-questions attain better retrieval yields at smaller top-k settings compared to baselines.
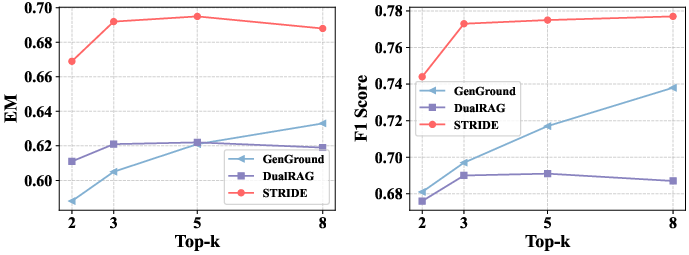
Figure 7: STRIDE achieves superior performance with lower retrieval top-k values, reflecting more targeted and effective sub-question generation.
Theoretical and Practical Implications
STRIDE’s explicit separation of meta-level reasoning, dependency-aware scheduling, and faithfulness-preserving execution introduces new modularization principles for MHQA and broader retrieval-augmented NLP pipelines. This approach enables not only greater robustness and efficiency but also creates naturally interpretable execution traces, supporting both model auditing and targeted self-improvement. Practically, the self-supervised fine-tuning paradigm democratizes high-performance multi-hop QA for open-source models, facilitating deployment under real-world cost and privacy constraints.
Future Prospects
Future directions include:
- Extending STRIDE’s planning and control paradigm to other knowledge-intensive reasoning domains (e.g., multi-modal QA, procedural reasoning).
- Leveraging STRIDE-style modular traces for continual self-improvement and process-level explainability in large-scale AI agents.
- Exploring automatic plan correctness verification and more sophisticated fallback or recovery mechanisms in extremely noisy or adversarial retrieval settings.
Conclusion
STRIDE provides a principled, hierarchical framework for multi-hop question answering, demonstrating that explicit separation of strategy, control, and execution modules combined with self-supervised modular fine-tuning can drive both accuracy and robustness in retrieval-augmented reasoning tasks. The approach is broadly applicable to complex QA and reasoning settings, especially as open-source LLM capability and structure-aware training paradigms continue to advance.