- The paper introduces trajectory-restricted regularity conditions that replace conservative global bounds by quantifying local geometry through Hoffman constants and restricted smoothness.
- It formalizes the equivalence of restricted Polyak–Łojasiewicz and error bound conditions, proving that the active subsets visited by iterates dictate fast, local linear convergence rates.
- Empirical studies with LASSO and SVM demonstrate that identifying active sets significantly improves conditioning and accelerates convergence, guiding adaptive algorithm design.
Trajectory-Restricted Convergence and Geometry-Aware Conditioning in First-Order Optimization
Introduction and Motivation
Standard analyses of first-order algorithms in convex and composite optimization typically invoke global regularity conditions—such as the Polyak–Łojasiewicz (PL) inequality, error bounds, and quadratic growth—which guarantee linear convergence with rates determined by worst-case geometric constants evaluated over the full ambient space. Such global constants often scale unfavorably with the problem dimension, especially in high-dimensional settings or when structure (e.g., sparsity) is present, leading to conservative theoretical predictions that are at odds with the empirically observed fast convergence upon entering structured (e.g., sparse or low-rank) solution manifolds.
This paper develops a trajectory-restricted theory of optimization, systematically localizing regularity conditions and their associated geometric constants to subsets relevant to the optimization trajectory. The authors provide formal definitions of restricted PL, error bound, and quadratic growth conditions, encompassing both smooth and polyhedral composite problems, and establish their equivalence on restricted subsets. The main insight is that actual convergence rates are fundamentally governed by geometric quantities (Hoffman constants, restricted smoothness) associated with active faces or manifolds traversed by the algorithm, not by worst-case global bounds.
The foundational definitions in the paper introduce “restricted” versions of the central optimization regularity conditions, requiring them to hold only on subsets K visited by the iterates. For a composite
F(x)=f(x)+g(x),
where f is L-smooth (possibly nonconvex), and g is convex, possibly nonsmooth, the main restricted conditions are:
- K-restricted PL: For all x∈K,
21Dg(x,L)≥νK(F(x)−F∗),
where Dg is the generalized gradient size.
- K-restricted Error Bound (EB): For all F(x)=f(x)+g(x),0,
F(x)=f(x)+g(x),1
where F(x)=f(x)+g(x),2 is the proximal gradient mapping.
Crucially, the paper proves that all standard linear convergence guarantees for proximal-gradient methods hold under these restricted conditions, with contraction rates dictated by the localized constants on the sets actually visited by the iterates. If the iterates enter and remain within a well-conditioned subset F(x)=f(x)+g(x),3, the remaining optimization enjoys the fast “local” rate
F(x)=f(x)+g(x),4
where F(x)=f(x)+g(x),5 is the restricted smoothness (largest local Lipschitz constant) over F(x)=f(x)+g(x),6. They also establish the equivalence (with explicit constants) between the restricted PL and EB properties under weak invariance assumptions, thereby unifying restricted regularity analysis.
Polyhedral Problems: Local Hoffman Constants and Active-Set Behavior
For polyhedral composite problems
F(x)=f(x)+g(x),7
with F(x)=f(x)+g(x),8 strongly convex and F(x)=f(x)+g(x),9 polyhedral (including indicator constraints), the global Hoffman constant f0 quantifies the translation of constraint violations to distance from feasibility. The paper’s core theoretical result is that after localization to the set f1 (e.g., active face or support identified along the trajectory), the restricted PL and EB constants are explicitly governed by the restricted Hoffman constant f2. This leads to tremendous dimensionality reduction in the effective conditioning once the active structure is identified. In high dimensions, this improvement is dramatic: the global Hoffman constant for the f3-LASSO problem, for example, scales as f4, while the active-set restricted value is independent of f5, scaling only with the intrinsic sparsity.
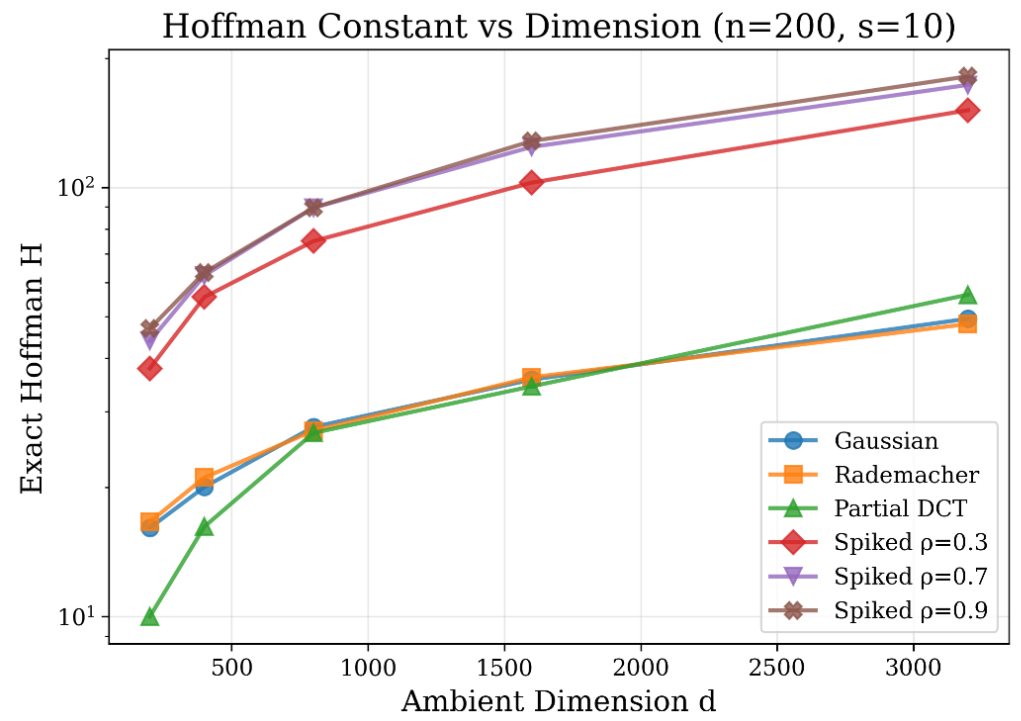
Figure 1: The Hoffman constant f6 for LASSO increases as f7 with ambient dimension; highly correlated designs (spiked models) are strictly worse than Gaussian/Rademacher ensembles.
This phenomenon is formalized in results specifying the two-phase convergence profile observed for ISTA and similar first-order methods: a transient regime governed by conservative, ambient-scale geometry precedes sharp acceleration upon entry into the active-set manifold (e.g., support identification). The local linear rate is then governed by the active submatrix’s spectral and geometric properties, not those of the full design matrix.
LASSO: Empirical and Theoretical Geometry of the Iterates
Using the LASSO as a case study, the paper provides an explicit characterization of the optimal set, active set structure, and strict complementarity margins, with direct calculation of restricted Hoffman and firm convexity constants. Empirically and by analytic bounds,
- The global condition number scales as f8;
- The active-set restricted condition number scales as f9 (for L0), i.e., a reduction by L1.
The trajectory of the algorithm is shown to be quickly contained in a specific cone or even the active subspace:
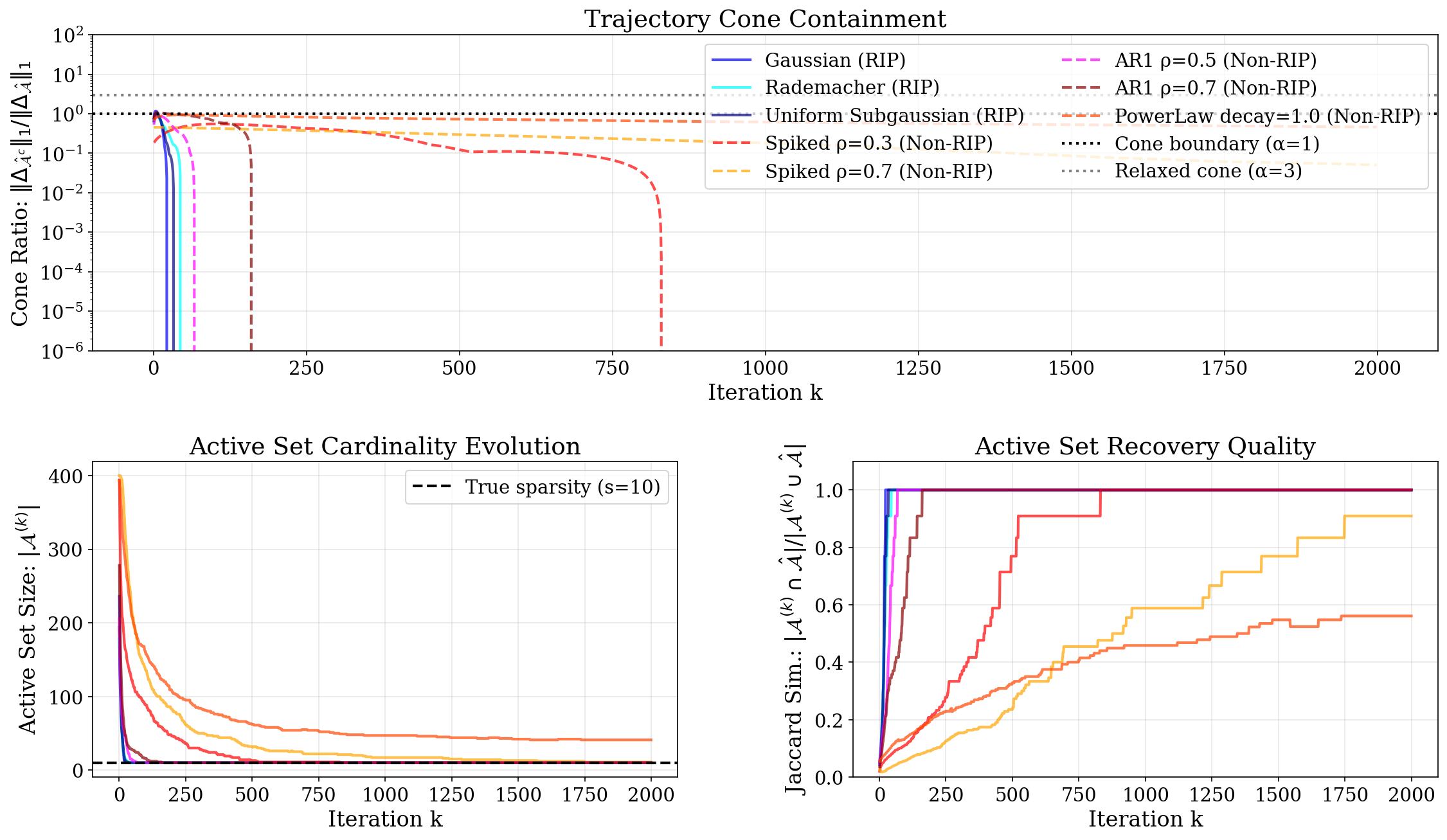
Figure 2: ISTA iterates for LASSO quickly enter structured cones around the optimal support; once the Jaccard similarity between current and optimal support reaches 1, the local manifold has been identified and convergence accelerates.
This observation is robust across matrix ensembles, and designs satisfying the Restricted Isometry Property (RIP) enter the restricted cone and support set more sharply, explaining their improved rates. The analysis further demonstrates that in normalized formulations (with loss scaled by sample size), the local condition number becomes dimension-free (L2), aligned with both theoretical and empirical high-dimensional statistics results.
Extensions: SVMs, Non-Polyhedral, and General First-Order Methods
The restrict-to-trajectory paradigm extends to the dual SVM problem, where the effective asymptotic rate is dictated by the geometry (restricted Hoffman constant) of the support vector subspace, not the global matrix—explaining fast convergence in overparameterized or kernelized SVM even when the ambient Gram matrix is ill-conditioned. The same philosophy applies to other composite regularizers (group-lasso, nuclear norm) and first-order solvers (coordinate, block-coordinate, SGD), and the framework is naturally generalized to arbitrary L3 norms.
The authors argue that this geometric approach demystifies the success of first-order methods in high-dimensional overparameterized regimes, including deep learning, where empirical trajectories concentrate on low-dimensional, favorably conditioned manifolds.
Implications and Future Directions
The trajectory-restricted theory developed here has several impactful consequences:
- Geometry-Aware Algorithm Design: Knowledge of active-set entry can allow the use of adaptive step sizes and preconditioning tuned to local rather than ambient geometry, offering substantial practical acceleration.
- Beyond Worst-Case Complexity: Practically observed fast convergence rates are justified whenever the algorithm’s trajectory rapidly enters well-conditioned subsets, and worst-case lower bounds are only relevant if iterates are forced to visit ill-conditioned regions.
- Extensions to Nonconvex and Deep Learning Regimes: The framework provides an analytic pathway for local geometric analysis in nonconvex optimization, illustrated by the observed low-dimensional structure discovered by neural networks during training.
Conclusion
This work formalizes and quantifies the geometry-driven mechanism underlying linear convergence of first-order methods. By localizing regularity to the subset of the domain actually explored by the iterates, it demonstrates that linear convergence rates are governed by the conditioning of the visited regions—not the global worst-case geometry. For polyhedral and structured composite problems, this is captured by restricted Hoffman constants and restricted smoothness, directly linking optimization dynamics, algorithmic rates, and high-dimensional geometric statistics. The implications extend beyond convexity and suggest that adaptive, geometry-aware methods will be central to efficient optimization in large-scale and overparameterized statistical and machine learning models.
Reference: "Trajectory-Restricted Optimization Conditions and Geometry-Aware Linear Convergence" (2604.17067).